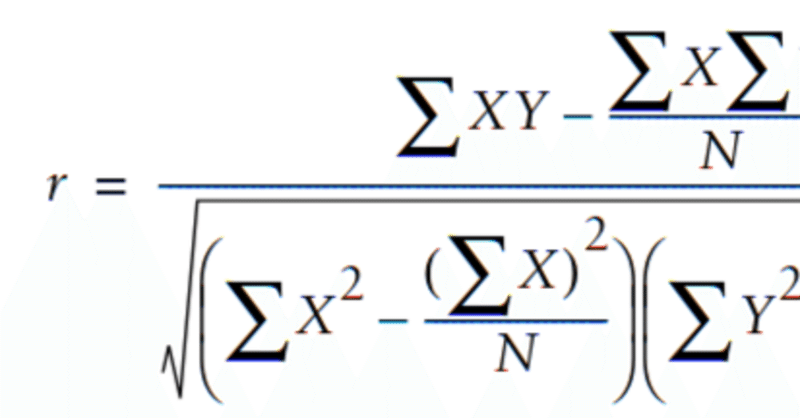
レコメンドシステム入門 Javascriptで実装する

レコメンド(推薦システム)に関して素晴らしい記事があったので訳してみました。訳に難があるが、そこはご勘弁ください。
プログラム実行してみると理解できると思います。入門者に打って付けの記事です。
以下、本文。
インターネットの世界はレコメンドで溢れていますね。
Amazonのように商品を購入するeコマース・サイト、Facebookのようなソーシャルネットワーク、YoutubeやNetflixのようなビデオ/映画サイトなど。これらのサイトに共通するのは、あなたに新しいものを推薦するために、映画、商品と友人などの過去のデータを使うことです。
この記事では、レコメンド機能がJavaScriptで、どのように動くか簡単に紹介します。推薦システムを実現するための、異なるアプローチも見ていきます。最終的にはアルゴリズムを切り替えただけで、結果を出力できるようにします。映画評論家の小さいデータセットと、MovieLensと呼ばれる本物の映画データを使った例で実装していきます。
協調フィルタリング
誰でも、製品、映画の推薦を得るための最良の方法は、友人に聞くことだと知っています。私が一番いい映画を発見した唯一の方法のは、映画に詳しい友人を介して知ったことです。最初は退屈だと思っていた「Game of throne」は、まさに友人を介して知りました。誰もが、このような体験したことがあると思います。
あなたがファッションについて詳しい友人が何人かいたとしましょう。あなたがデートで着る服で迷っているとします。誰もが、全く違う服を提案して来ます。どんどん混乱していくあなた。
より多くの選択肢が増えるにつれて、何が最適か少人数に聞くのは、実用的でなくなります。協調フィルタリングと呼ばれる手法が開発されたのはこのためです。
協調フィルタリング・アルゴリズムは、大勢の人たちの嗜好から、あなたに似た好みの小さな集団を見つけます。彼らの好みを元に提案がランク付けされたリストを作成します
Javascriptでオブジェクトを作成して、映画評論家たちを格納し、彼らが好きな映画と、その評価を対応させていきます。
var dataset={
'Lisa Rose': {
'Lady in the Water': 2.5,
'Snakes on a Plane': 3.5,
'Just My Luck': 3.0,
'Superman Returns': 3.5,
'You, Me and Dupree': 2.5,
'The Night Listener': 3.0},
'Gene Seymour': {'Lady in the Water': 3.0,
'Snakes on a Plane': 3.5,
'Just My Luck': 1.5,
'Superman Returns': 5.0,
'The Night Listener': 3.0,
'You, Me and Dupree': 3.5},
'Michael Phillips': {'Lady in the Water': 2.5,
'Snakes on a Plane': 3.0,
'Superman Returns': 3.5,
'The Night Listener': 4.0},
'Claudia Puig': {'Snakes on a Plane': 3.5,
'Just My Luck': 3.0,
'The Night Listener': 4.5,
'Superman Returns': 4.0,
'You, Me and Dupree': 2.5},
'Mick LaSalle': {'Lady in the Water': 3.0,
'Snakes on a Plane': 4.0,
'Just My Luck': 2.0,
'Superman Returns': 3.0,
'The Night Listener': 3.0,
'You, Me and Dupree': 2.0},
'Jack Matthews': {'Lady in the Water': 3.0,
'Snakes on a Plane': 4.0,
'The Night Listener': 3.0,
'Superman Returns': 5.0,
'You, Me and Dupree': 3.5},
'Toby': {'Snakes on a Plane':4.5,
'You, Me and Dupree':1.0,
'Superman Returns':4.0}};嗜好の似たユーザーを探す
ユーザーの好みに関する情報を収集した後で、同じ嗜好のユーザーを特定する方法を見つけます。これを行うには、全てのユーザーの類似性スコアを計算し、対象となる人と比較していきます。アルゴリズムには、ユークリッド距離とピアソン相関係数を使用します。
ユークリッド距離
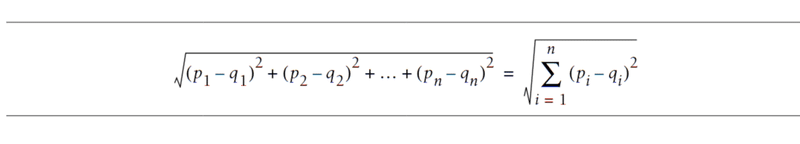
2人のユーザー間の類似性スコアを計算するための、最も簡単な方法の1つです。下の図で言うとチャート上の点(xy軸)としてデータを表現します。例で言うと、映画評論家から「Dupree」を見た人の軸(x軸)と「Snakes on a Plan」を見た人の軸(y軸)となります。
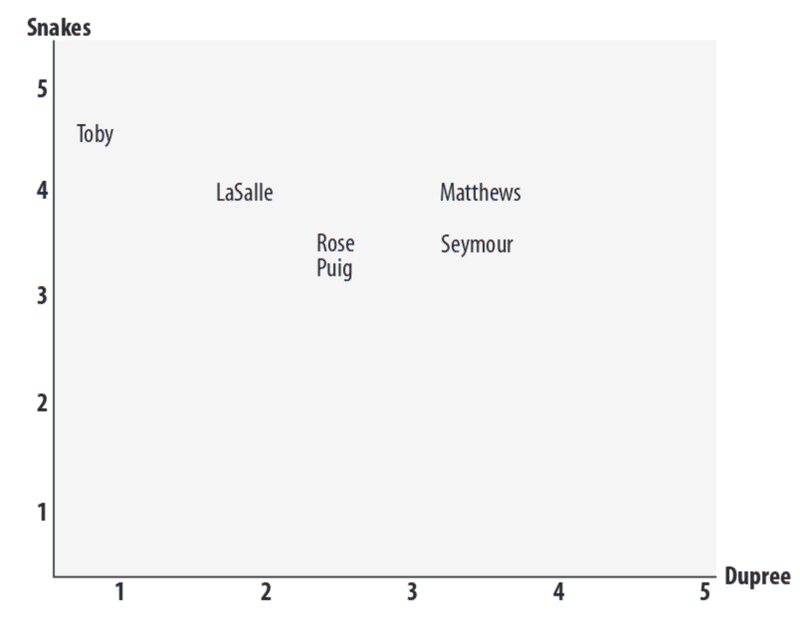
上の図は、Roseが「Snakes on a Plan」に3.5、「 Dupree」の軸に2.5に位置されていることを示しています。ユーザー同士の嗜好空間に近いほど、彼らの類似性は近くなります。チャートは2次元であるため、一度に限られたランキングしか見ることしかできません。
例えば、Lisa RoseとMathewの距離を計算してみます。
var euclid = Math.sqrt(Math.pow(3.5-2.5,2)+Math.pow(4.0-3.5,2));
//1.118033989これは距離を計算ています。類似しているユーザーは、値がより小さくなりますが、趣向が同じような人々に対して、値を高くしたいので、値は0から1の間の範囲にします。つまり、似たようなユーザーは、1に近い値なるよう変換します。
var reuclid = 1/(1+euclid);
//0.472135954それでは映画評論家のための、ユークリッド距離を計算するメソットを作成しましょう。
//2つのアイテムのユークリッド距離を計算
var euclidean_score = function(dataset,p1,p2){
var existp1p2 = {};//datasetにりょうアイテムがある場合のオブジェクト
//datasetの中にp1,p2があれば1を格納
for(var key in dataset[p1]){
if(key in dataset[p2]){
existp1p2[key] = 1
}
if(len(existp1p2) ==0) return 0;//データがあるかチェック
var sum_of_euclidean_dist = [];//ユークリッド距離を格納
//ユークリッド距離を計算
for(item in dataset[p1]){
if(item in dataset[p2]){
sum_of_euclidean_dist.push(Math.pow(dataset[p1] [item]-dataset[p2][item],2));
}
}
var sum=0;
for(var i=0;i<sum_of_euclidean_dist.length;i++){
sum +=sum_of_euclidean_dist[i]; //ユークリッド距離の合計を計算
}
//類似性が高い場合に値が小さくなるので
// 類似性が高い場合は値を大きくする計算
//0から1の間に収まるようにする。
var sum_sqrt = 1/(1 +Math.sqrt(sum));
return sum_sqrt;
}
}オブジェクトの、長さを計算するためのヘルパー関数を作成します。
var len = function(obj){
var len=0;
for(var i in obj){
len++
}
return len;
}Lisa RoseとMathewsの間のユークリッド距離を計算しましょう。
euclidean_score(dataset,"Lisa Rose","Jack Mathews");
//0.3405424265831667ピアソン相関係数
相関係数とは、2つのデータセットがどの程度、直線に収まるかを示す尺度です。公式は、ユークリッド距離より複雑ですが、データが正規化されていない場合はより正確な結果が得られます。
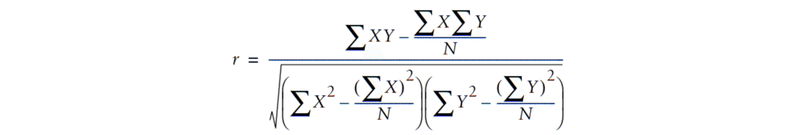
var pearson_correlation = function(dataset,p1,p2){
var existp1p2 = {};
for(item in dataset[p1]){
if(item in dataset[p2]){
existp1p2[item] = 1
}
}
var num_existence = len(existp1p2);
if(num_existence ==0) return 0;
var p1_sum=0,
p2_sum=0,
p1_sq_sum=0,
p2_sq_sum=0,
prod_p1p2 = 0;
for(var item in existp1p2){
p1_sum += dataset[p1][item];
p2_sum += dataset[p2][item];
p1_sq_sum += Math.pow(dataset[p1][item],2);
p2_sq_sum += Math.pow(dataset[p2][item],2);
prod_p1p2 += dataset[p1][item]*dataset[p2][item];
}
var numerator =prod_p1p2 - (p1_sum*p2_sum/num_existence);
var st1 = p1_sq_sum - Math.pow(p1_sum,2)/num_existence;
var st2 = p2_sq_sum -Math.pow(p2_sum,2)/num_existence;
var denominator = Math.sqrt(st1*st2);
if(denominator ==0) return 0;
else {
var val = numerator / denominator;
return val;
}
}
この関数は-1から1の間の値を返します。値-1は近いか類似していないことを意味し、値1は2人の人物がすべてのアイテムに対して、まったく同じ評価を持つことを意味します。
pearson_correlation(dataset,'Lisa Rose','Jack Matthews')
//0.7470178808339965※ピアソンの積率相関係数の算出はこの記事が非常にわかりやすいので参考にしてみてください。
批評家のランキング
類似性スコアが作成された後に、対象となるユーザーと、映画評論家の中からユーザをランク付けします。すなわち、同じ映画の好む他のユーザを見つけるための関数を作成します。
var similar_user = function(dataset,person,num_user,distance){
var scores=[];
for(var others in dataset){
if(others != person && typeof(dataset[others])!="function"){
var val = distance(dataset,person,others)
var p = others
scores.push({val:val,p:p});
}
}
scores.sort(function(a,b){
return b.val < a.val ? -1 : b.val > a.val ? 1 : b.val >= a.val ? 0 : NaN;
});
var score=[];
for(var i =0;i<num_user;i++){
score.push(scores[i]);
}
return score;
}この関数は、ユーザ同士を比較するときに、ユーザが自分自身と比較されていないかどうかをチェックします。最後に、ソートされたn個のユーザを返します。
similar_user(dataset,'Jack Matthews',3,pearson_correlation);
//[ { val: 0.963795681875635, p: 'Gene Seymour' },
{ val: 0.7470178808339965, p: 'Lisa Rose' },
{ val: 0.66284898035987, p: 'Toby' } ]この結果から、Jack MatthewsはGene Seymourの映画レビューを読んでいるはずです。
おすすめアイテム
先ほど作成したランキングは、ユーザーが実際に見たいものではありません。たとえば、Jack Matthewsのようなユーザーが、Gene Seymourが視聴したことのあるオススメ映画を返すだけでは面白くないです。多くの評論家から悪い評判を得た映画なのに、たまたまその映画が好きだったユーザーからのオススメをもらいたいものです。
これらの問題を解決するには、評論家をランク付けする、類似性とアイテムとの加重スコアを作成します。ユーザー以外のすべての評論家の評価を用いて、ユーザーとの類似度を各映画のスコアで乗算します。
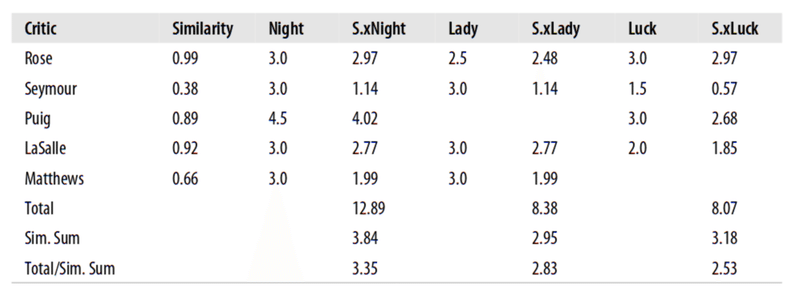
プログラミング集合知(Toby)
上の表は、各評論家の相関スコアと3つの映画に対する評価を示しています。上の表はTobyのスコアマトリックスです。 Tobyは(The Night Listener、Lady in the Water、Just My Lick)のような映画を評価していません。列S.xを得るためには、各映画の評価をTobyとの類似性(Simmllarity)を掛け算してすべての評価に重みを付けます。次に、各S.x列の合計を、類似性スコア(Simmillarty)の合計で割ります。
割る理由は、より多くの人々によってレビューされた映画がより有利になってしまうからです。たとえば、Night Listenerはみんなに見られているので、合計は、すべての類似点の合計で割られます。一方でLady in the WaterはPuigによって評価されなかったので、Puigを除いた類似点の合計で割られます。
var recommendation_eng = function(dataset,person,distance){
var totals = {
setDefault:function(props,value){
if(!this[props]){
this[props] =0;
}
this[props] += value;
}
},
simsum = {
setDefault:function(props,value){
if(!this[props]){
this[props] =0;
}
this[props] += value;
}
},
rank_lst =[];
for(var other in dataset){
if(other ===person) continue;
var similar = distance(dataset,person,other);
if(similar <=0) continue;
for(var item in dataset[other]){
if(!(item in dataset[person]) ||(dataset[person][item]==0)){
//the setter help to make this look nice.
totals.setDefault(item,dataset[other][item]*similar);
simsum.setDefault(item,similar);
}
}
}
for(var item in totals){
if(typeof totals[item] !="function"){
var val = totals[item] / simsum[item];
rank_lst.push({val:val,items:item});
}
}
rank_lst.sort(function(a,b){
return b.val < a.val ? -1 : b.val > a.val ?
1 : b.val >= a.val ? 0 : NaN;
});
var recommend = [];
for(var i in rank_lst){
recommend.push(rank_lst[i].items);
}
return [rank_lst,recommend];
}recommendation_eng(dataset, "Toby", euclidean_score);
[ [ { val: 3.457128694491423, items: 'The Night Listener' },
{ val: 2.778584003814924, items: 'Lady in the Water' },
{ val: 2.422482042361917, items: 'Just My Luck' } ],
[ 'The Night Listener', 'Lady in the Water', 'Just My Luck' ] ]
みなさん、いかがでしたか?いいデータセットが取れれば、あらゆる分野で応用できそうです。ぜひ、遊んでみてください。
記事の元ネタはこれ。いまだに名著です。
この記事が気に入ったらサポートをしてみませんか?