KNNアルゴリズム(K-近傍法)をscikit-learnを使わず5行で実装する。(Python)

機械学習のライブラリは抽象化されていますが、どのように動いているいるのか、アルゴリズムは絶対理解しておいた方がいいいです。逆に機械学習を学ぶということは、アルゴリズムの理解が大部分を占めます。
k-近傍法(k-nearest neighbor algorithm)は、分類や回帰のためのシンプルな機械学習アルゴリズムです。
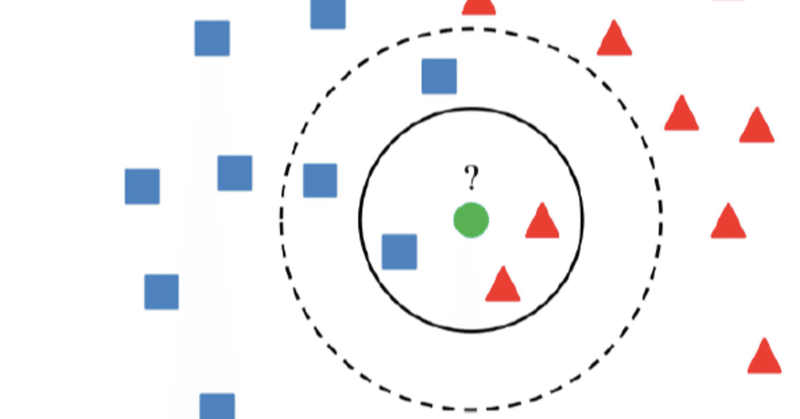
k-近傍法は、新しいデータが与えられたときに、そのデータが近いとされる、学習用のデータセット中の個々のサンプルとの距離を計算します。その後、これらのサンプルからk個の最も近いサンプル(k-nearest neighbors)を選択します。これらk個のサンプルから、新しいサンプルが最も多く分類されるクラスを予測します。
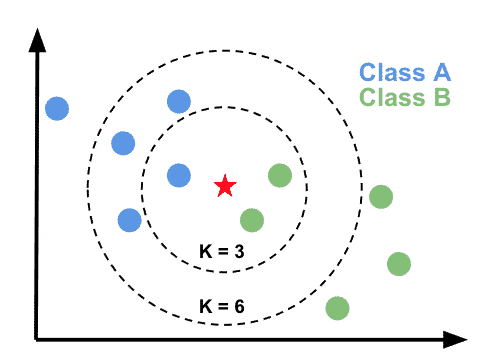
例えば、新しいサンプルが緑の点としてプロットされているとします。k=3の場合、この新しいサンプルに最も近い2つのサンプル(緑の点)を選択します。この3つのサンプルから、新しいサンプルが最も多く分類されるクラスは、緑の点です。そのため、新しいサンプルは緑のクラスとして予測されます。(k=6の場合は青いクラス)
k-近傍法は、分類や回帰のための簡単なアルゴリズムであり、実装が容易であるため、機械学習の初学者によく使われます。ただし、kの値を適切に選択する必要があり、大きすぎるか小さすぎる値を選択すると、過学習や未学習の問題が発生する可能性があります。
import numpy as np
def knn(data, labels, new_data, k):
# 予測したいデータと他のすべてのデータ間の距離を計算する
distances = np.array([np.linalg.norm(new_data - d) for d in data])
# k分ソートしてして近いインデックスを見つける
knn_indices = np.argsort(distances)[:k]
#ソートした分のラベルを取得
knn_labels = [labels[i] for i in knn_indices]
#最も多いラベルを返す
return max(set(knn_labels), key=knn_labels.count)
# テストデータ
data = np.array([[0, 1],[1, 2], [3, 4], [5, 6], [7, 8], [9, 10]])
labels = ["a","a", "b", "b", "c", "c"]
k = 3
# 分類したいデータ
new_data = np.array([4, 5])
# 実行
label = knn(data, labels, new_data, k)
# 結果
label
b以下、機械学習のオススメ書籍。この順番で学ぶと理解が深まります。
この記事が気に入ったらサポートをしてみませんか?