
【Python×Tableau】KaggleのデータセットをTableauとPythonで特徴量選択と外れ値の除去をやってみた!

みなさん、こんにちは!
今回の記事は、ライター今田が担当します。
無料版のTableauとPythonを使用して、住宅価格予測のKaggleチュートリアルのデータセットを用いて、目的変数に関連の高い特徴量の選択と、外れ値の除去をやってみようと思います!
1. Kaggle House Prices (住宅価格予測のチュートリアル)のデータセット
Kaggleとは世界中のデータサイエンティスト・アナリストが競う分析コンペのプラットフォームです。
Kaggleのチュートリアルには、今回扱う回帰問題の住宅価格予測とクラス分類問題のタイタニック乗客生存予測があります。タイタニックの方から取り組む方が多いかもしれません。(私は、タイタニックからやりました。)
データセットのダウンロードは、以下ページよりできます。アカウントの登録(無料)が必要です。
データセットの内容についても説明が記載されています。
このチュートリアルでは用意されたデータでSale Priceを予測していくことになります。(以下ページに記載されています)
2. Pythonで目的変数と説明変数の相関をみる
まずはダウンロードしたファイルを読み込んでデータ量などを確認してみます。
#おなじみのライブラリ
import numpy as np
import pandas as pd
#ダウンロードしたファイルを読み込む
train_data = pd.read_csv('train.csv')
#データの確認
train_data .info()#実行結果
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1460 entries, 0 to 1459
Data columns (total 81 columns):
約80この特徴量があることがわかります。
相関係数で目的変数のSale Priceと相関の高い特徴量を抽出してみます。
#読み込んだデータの相関係数を抽出する
corr_data = train_data.corr()
#抽出した相関係数で0.5より大きいものと0.5より小さい(正の相関・負の相関がありあそう)なものを抽出して表示する
corr_data_high = corr_data[(corr_data['SalePrice']>0.5) | (corr_data['SalePrice']<-0.5)]['SalePrice']
corr_data_high#実行結果
verallQual 0.790982
YearBuilt 0.522897
YearRemodAdd 0.507101
TotalBsmtSF 0.613581
1stFlrSF 0.605852
GrLivArea 0.708624
FullBath 0.560664
TotRmsAbvGrd 0.533723
GarageCars 0.640409
GarageArea 0.623431
SalePrice 1.000000
Name: SalePrice, dtype: float64
だいぶ絞り込めました!
(実際はもう少し対象を広げてモデル作成すると思いますが、今回はこれでいきます)
相関の高い特徴量同士の相関も見てみます。
#カラム名のみリストで抽出
columns = corr_data_high.index.values
#抽出したカラム名で高い相関がありそうなデータを表示する
corr_data2 = corr_data.loc[columns][columns]
corr_data2[(corr_data2>0.7) | (corr_data2<-0.7)]#実行結果のキャプチャ
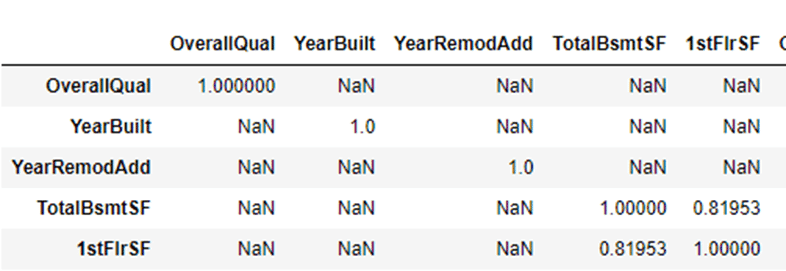
TotalBsmtSFと1stFlrSFは相関が強そうですね。
この辺は、予測モデルの結果を見ながらどちらかを削除することを検討してもよいかもしれません。
3. 相関の高いデータをTableauで可視化して、外れ値も除去する
無料版のTableau Publicは、以下よりダウンロードできます。
ファイルを保存するときに一般公開されるようになっているので、機密性の高いデータ(個人情報、顧客情報など)は扱わないように十分に気を付けてください。
Tableau Publicをインストールしたら、訓練データのファイルをTableau Publicにドラッグアンドドロップすると読み込まれます。
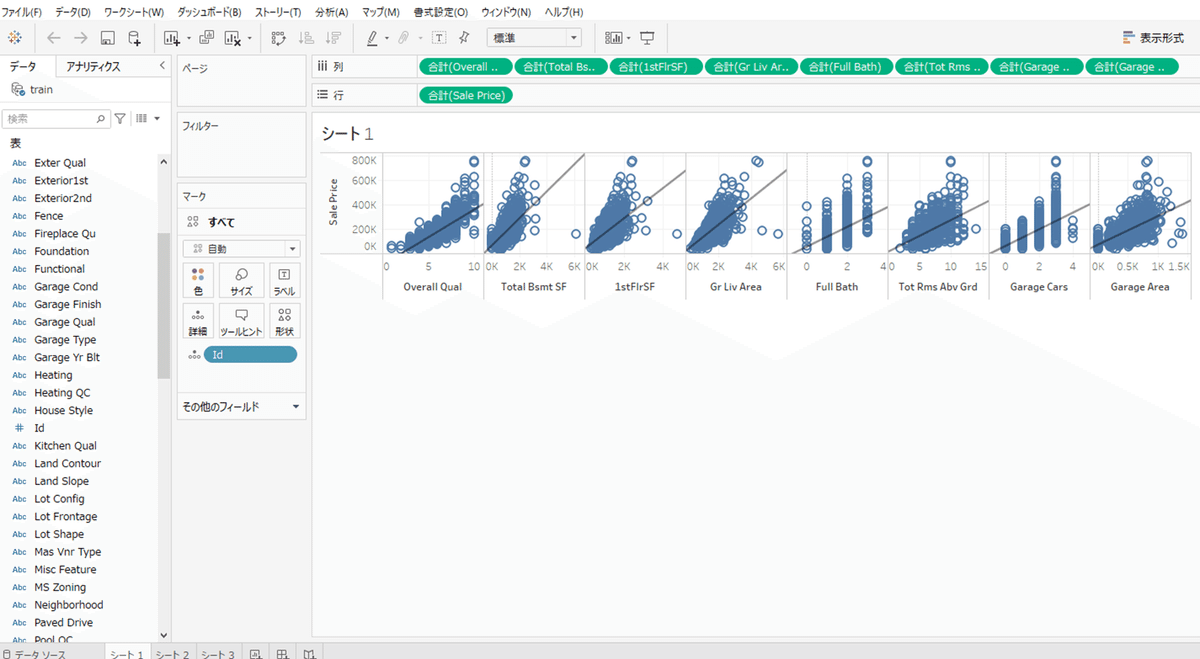
シートを開いて、以下手順で画像のような表示されます。
1. 列に先ほどPythonで抽出したカラムを行にドラッグする
2. 列に目的変数のSale Priceをドラッグする
3. ツールバーの「分析」をクリックして「メジャーの集計」をオフにする
4. アナリティクスのタブをクリックして傾向線をドラッグして線形を選ぶ
右肩上がりの傾向ですね!
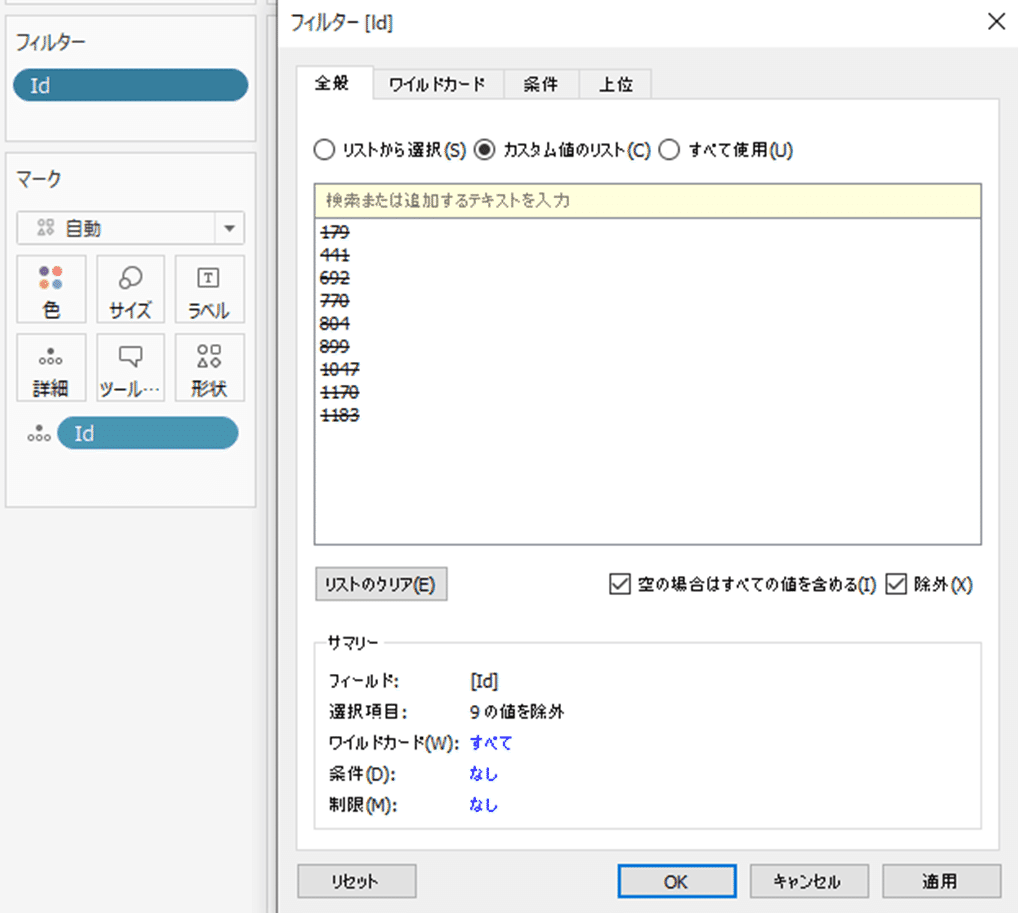
傾向線から外れているデータを範囲で指定して、除外を選択するとフィルターに指定したデータが入り除外されます。

除外されたIDをコピペすると、除外するIDが取得できます。
4. まとめ・感想
今回は、Tableauだけで試してみようと思ったのですが、
データ量が多いとビジュアライズ作成に時間がかかってしまったり、そもそもテーブルデータの扱いには限界を感じたので、
表計算・統計はPythonで処理して、ビジュアライズ作成はTableauでやることにしました。
Pythonでもビジュアライズ作成はできるのですが、コード書くのに慣れてないと大変で、その点ではドラッグアンドドロップで感覚的に扱えるTableauが便利だと個人的には感じます!
ツールの特性を生かしながら、生産性の高い仕事ができるようになりたいと思う今日この頃です。
2021年のAIクエスト(https://aiquest.meti.go.jp/)に参加したのですが、Power BIを使う人が多かったのでTableauの利用者ももっと増えたらいいなぁと思っています!
最後までお読みいただきありがとうございました!
最後に
SMKT事業部では、データアナリスト・データエンジニアを募集しています。
是非こちらもご覧ください。
▽その他募集職種こちらから▽
●●●
✉ サービスに関するお問い合わせ ✉
パーソルプロセス&テクノロジー SMKT事業部
smkt_markegr_note@persol-pt.co.jp