
#WWDC2020 に期待する発表

いよいよ来週。初のオンライン開催。消費者としての期待ではなく(つまり新製品とかではなく)、いちデベロッパー目線から期待している発表について書く。
機械学習ベースの音声処理サポートの拡充
機械学習/ディープラーニングを用いた画像処理機能についてはiOS標準のAPIでもかなり充実してきたが、音声の方はまだまだこれからという印象。
画像処理でいえばVisionフレームワークのレイヤーに相当するのがiOS 13で登場したSoundAnalysisフレームワーク。
何が嬉しいって、機械学習/DLモデルに音声を入力するための面倒な前処理をラップしてくれる。とくに音声処理は画像処理よりめんどくさい印象がある。
SoundAnalysis + Create MLで話者認識(2019年6月に開催された勉強会向けにつくったデモ) #iOS13https://t.co/qpExce47Ss pic.twitter.com/r2Dg27ueeH
— Shuichi Tsutsumi (@shu223) February 27, 2020
しかしこのSoundAnalysis、今のところ音声分類(Sound Classification)タスクしかサポートしていない。画像処理が画像分類タスク以外に画像検出やセグメンテーション、Style Transfer、類似度計算等々あるように、音声にもイベント検出(テンポや小節の頭の検出)や音源の分離、音源方位の推定等々さまざまなタスクがある。
SoundAnalysisだけでなく、Create ML, Turi Createも現状Sound Classificationしかサポートしてないので、このあたりで新機能の発表を期待している。
あとSound Classificationにしても、現状は自分でデータセットを用意してモデルを自作するしかないが、「人の声が入っているかそうでないか」「大人の声、子供の声、それ以外」「男性の声、女性の声」等々、汎用性が高いものはSoundAnalysisフレームワーク内に標準搭載するか、公式Core MLとして配布するかしてほしい。
Neural Engine APIもしくはReport
GPUに対するMetalみたいにがっつり専用フレームワークが出てくるところまでは期待していないが、たとえばXcodeのGPU ReportでGPUのフレームレートや負荷状況がわかる、みたいにNeural Engineで処理が行われているか確認できるようになるとか、
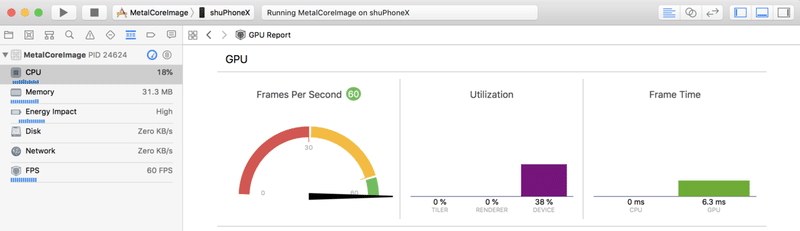
Neural Engineで処理されるレイヤー、そうでないレイヤーといった情報が確認できる公式ドキュメントが出るとか、何かしらNeural Engineに関して開発者側にも口を開けていく動きがあるといいなぁと。
U1チップに関する何らかのAPI
デプス@AVFoundation
ARKitではセグメンテーション用のマスクデータを毎フレーム取得できるが、AVFoundationでは(リアルタイムでは)取得できない。(保存した静止画から取得することはできる)
Create MLでセグメンテーションモデルをサポート
あとはCreate ML/Turi Createでセグメンテーションモデルの学習をサポートしてくれたら、モバイルデバイスで機械学習モデルつかってやりたいことのほとんど(要出典)がTensorFlowやPyTorchまで潜らなくても、高いGPUマシン買わなくてもできるようになるhttps://t.co/wfxmGpy2rs
— Shuichi Tsutsumi (@shu223) May 4, 2020
GAN系とかは現実的にまだまだモバイルデバイスには重いし、多くのアプリで汎用的に使える機能で考えると、物体検出、セグメンテーション、姿勢推定で結構カバーできるんじゃないかなぁと。
— Shuichi Tsutsumi (@shu223) May 4, 2020
で、物体検出とセグメンテーションはわりと独自データセットでカスタムモデルつくりたいケースが多いかなと。
Core ML ToolsのGUI的なやつ
Turi CreateのGUIがCreate ML、みたいな感じで、Core ML ToolsのGUIがあってもいいんじゃない?と。モデルの変換がドラッグ&ドロップで済む、みたいな。input_namesに渡す名前とかは候補を抽出してくれてドロップダウンリストで選べる、みたいなイメージ。
ARKitの3Dオブジェクト検出の強化
ARKitの3Dオブジェクト検出は、肝心のスキャン側が中途半端なので、まともに使えないし、デプス使わずにこの機能は苦しいと思う(今のところスキャン時の設置場所に縛られてる)。ARKit 2.5ではARObjectScanningConfigurationだけでもデプス使うようになったらいいなぁ
— Shuichi Tsutsumi (@shu223) September 23, 2018
「デプスを使わないことで幅広いハードで動く」を売りにスタートしたARKitだけど、今はLiDARなんていうハードを超限定する機能も入れちゃったわけだし、そろそろ3Dオブジェクト検出にテコ入れしてほしい。
Exporting an object's mesh data scanned with #LiDAR.
— Shuichi Tsutsumi (@shu223) May 27, 2020
新型iPadのLiDARでスキャンした物体のメッシュデータを切り出してエクスポートする試み#ARKit 3.5 pic.twitter.com/KG6tyRgGBB

最後まで読んでいただきありがとうございます!もし参考になる部分があれば、スキを押していただけると励みになります。 Twitterもフォローしていただけたら嬉しいです。 https://twitter.com/shu223/