
TimeSeriesKMeansで時系列クラスタリングをしてみた

時系列データはその特性を調べるために深く掘り下げる必要がある。時系列クラスタリングはひとつの方法で、ChatGPTに教えてもらったのでメモ。
時系列クラスタリング
時系列クラスタリングは、データセット内の時系列データの異なるトレンドやパターンを識別し、類似するトレンドを持つ時系列データを同じクラスタにグループ化することができます。これにより、データの構造や関係を理解し、さらに分析や予測を行うための洞察を得ることができます。
時系列データのためのパッケージ「tslearn」には「UCR_UEA_datasets」という名前で100種類以上のサンプルデータが含まれてる。今回は「Plane」というデータセットを利用。データの詳しい説明は提供されていないようだが、カラム列が時系列を表しているらしい。
最適クラスタ数を確認
TimeSeriesKMeansを使用して1から10までのクラスタ数でクラスタリングを試し、結果をプロット。
エルボー(肘)のように曲線が折れ曲がる点が適切なクラスタ数。
このデータセットでは、4〜5が適切なクラスタ数か。
import matplotlib.pyplot as plt
from tslearn.clustering import TimeSeriesKMeans
from tslearn.datasets import UCR_UEA_datasets
import numpy as np
# データセットをロード
X_train, y_train, X_test, y_test = UCR_UEA_datasets().load_dataset('Plane')
# 時系列データを1つのデータセットにマージ
X = np.concatenate((X_train, X_test))
# クラスタ数の範囲を設定
cluster_range = range(1, 11) # ここでは1から10までのクラスタ数を試します
# 各クラスタ数でのk-meansクラスタリングのコストを計算
inertia = []
for n_clusters in cluster_range:
km = TimeSeriesKMeans(n_clusters=n_clusters, metric="euclidean", verbose=True, random_state=42)
km.fit(X)
inertia.append(km.inertia_)
# エルボー法の結果をプロット
plt.figure()
plt.plot(cluster_range, inertia, marker='o')
plt.xlabel('Number of clusters')
plt.ylabel('Inertia')
plt.title('Elbow Method For Optimal Number of Clusters')
plt.show()
時系列クラスタリングの結果
クラスタ数=4でTimeSeriesKMeansの時系列クラスタリング。
結果を可視化すると、確かに4種類のトレンドが存在するように見える。
実際にはそれぞれのクラスタが示すトレンドをさらに詳しく調べる必要があるのかも。
# k-meansクラスタリングの実行
n_clusters = 4
km = TimeSeriesKMeans(n_clusters=n_clusters, metric="euclidean", verbose=True, random_state=42)
y_pred = km.fit_predict(X)
# クラスタリング結果の可視化
plt.figure()
for cluster_idx in range(n_clusters):
plt.subplot(n_clusters, 1, cluster_idx + 1)
for series_idx in range(len(y_pred)):
if y_pred[series_idx] == cluster_idx:
plt.plot(X[series_idx].ravel(), "k-", alpha=0.7)
plt.plot(km.cluster_centers_[cluster_idx].ravel(), "r-")
plt.tight_layout()
plt.show()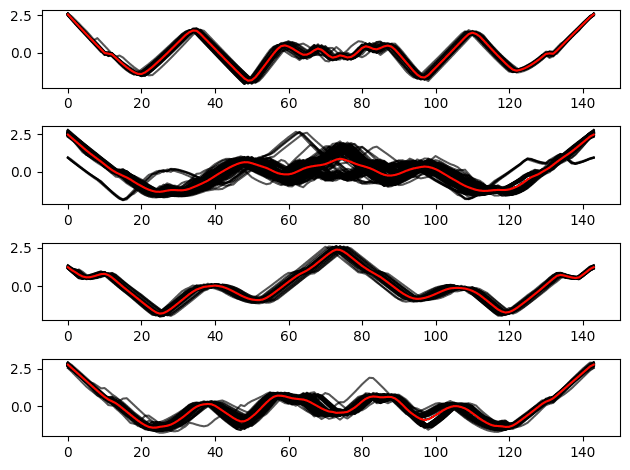
この記事が気に入ったらサポートをしてみませんか?