
【反省】運動制御について改めて勉強してみたら全然分かっていなかった件

どうも、サギョウ先生です‼️
今日は、運動制御についてのお話しです。
なぜ運動制御について解説するかと言いますと
タイトルの通りでして、運動制御って普段当たり前のように使っていましたが、想像以上に複雑でした😂
いかに普段なんとなくで「理解したつもり」になっていたか。。。
反省です。。。
ということで、理解したつもりになっていた人も「全然知らん!」という清々しい人も一緒に勉強しましょう📚✍🏻
この記事では、フィードフォワード制御、フィードバック制御、順モデルと逆モデル(内部モデル)、オブザーバーモデル、最適フィードバックモデルといった概念を解説しています☝️
それぞれの更に細かな内容は別のnoteにまとめようと思いますので、今回はそれぞれの概要を理解していきましょう👍
まだまだ理解が足りていない部分も多々ありますが、少しでもみなさんのお役に立てると嬉しいです!
本題に入る前に、僕の思いを聞いてください🙇♂️

僕は作業療法が大好きでして、特に対象者の「ひととなり(ナラティブ)」を意識して、心から身体を変えていくという点が特に好きです!
一方で、臨床や学校教育の中で、ナラティブに目が行きすぎてしまい、メカニズムやエビデンスに弱い部分も感じていました、、、
そこで、作業療法士がナラティブだけでなく、科学的なメカニズムやエビデンスを身につけるための一助となるように情報発信を始めました!
「自分の介入に自信がない」「他職種の話についていけない」「患者さんに説明できない」と感じてる作業療法士はぜひ僕と一緒に勉強していきましょう🦍🔥
では、本題に行ってみましょう!
随意運動とは?

これを作られた望月久先生は神です!
運動制御について理解するためには、まず随意運動について理解しておく必要があります。
目的意識的、意図的、かつ状況依存的であり、少なくともヒトにおいてはその行動が自発的に行われたものであるという「行為主体感」を伴うのが普通である。
随意運動の定義についてはすでにご存知の方も多いと思いますので、随意運動の流れについて確認していきましょう!
①認知と行動の決定
随意運動の最初のステップは、運動をしようと決めることです。
当たり前といえば当たり前ですよね(笑)
随意運動の定義で「目的的」とか「意図的」って言っていますし(笑)
このステップには主に大脳辺縁系や連合野が関わっています。
例えば、「喉が渇いた!ペットボトルを取ろう!」と思うことがこのステップに該当します🥛
②運動プログラムの作成
次のステップは、具体的な運動の計画(運動プログラム)をします!
ここでは、大脳運動関連領野(大脳基底核や小脳などと情報交換をしながら)が関わり、手を伸ばしてペットボトルを掴むための動きを計画します。
「どの筋肉をどう動かすか」なんてことまで決めています💪
③指令の修正と伝達
生成された運動プログラムを基に、一次運動野(M1)から下行性伝導路を通じて運動の指令が脳幹や脊髄へ投射されます。
また、小脳や大脳基底核、脳幹が運動指令の微調整を行い、大きなエラーが起きず、滑らかな動きできるようにしていきます。
ペットボトルを取るときの、手の位置や速度を調整します🖐️
④運動の実行
最後に、脊髄や末梢神経を通じて筋肉に指令が伝わり、実際に動く(関節運動)のです🏃♀️
手を伸ばしてペットボトルを掴む動きがこれに当たります。
また、感覚情報がフィードバックされることで、運動の精度がさらに高まります!
別の論文のレビューでも随意運動についてまとめたいますので是非見てくださいね⬇️
さて、ここまでが随意運動の簡単な流れの確認でした。
ここからが本題でして、この随意運動を大きく2つの運動制御に分けることができます!
それが下の画像です!

では、フィードバック制御(FF)とフィードバック制御(FB)について解説していきます!
フィードフォワード制御
FFについて説明しますね。
FFとは、運動を始める前に目標の状態を達成するための運動指令を出す方法で、感覚フィードバック(運動中の誤差)を使いません。
FFの良いところは、動き始めから終わりまでの時間が短くて済むことです。感覚フィードバックを待たずに動作を完了するので、反応時間がめちゃくちゃ短くなります。
また、運動初期は感覚に頼った運動は行えません(特に動作の一発目)ので、これまでの経験から運動指令を生成しないといけません。
スポーツや緊急時など、特に迅速な反応が求められる状況で特に役立ちますね!
例えば、ペットボトルを取る動きでは、ペットボトルの位置を認識し、その位置に向かって手を伸ばす動きを事前に計画します。実際の動作中には感覚フィードバックを使わず、事前の計画に従って手の運動を開始します。
メリット・デメリット
メリット

初めの段階で素早く反応できる
事前に計算することで動きの精度が上がる
デメリット
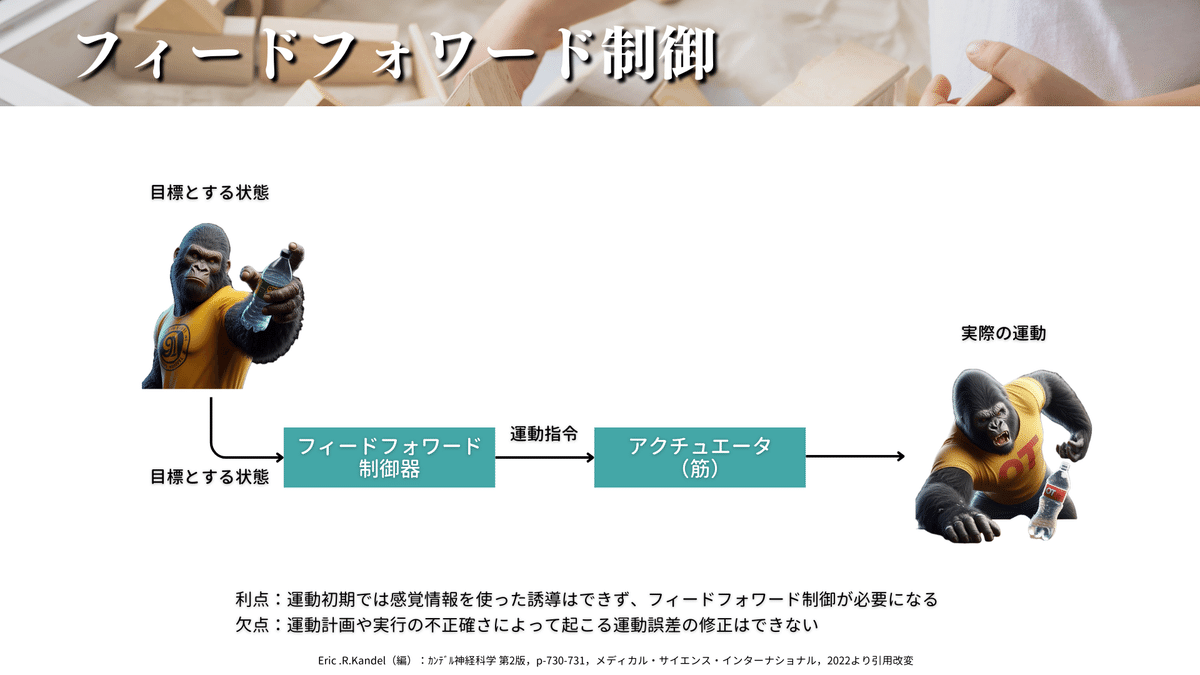
感覚フィードバックがないため、動きながらの修正が難しい
環境の変化に対応しにくい
フィードバック制御
次はFBについてです!
FBは、実際の運動と目標とする状態を比較し、その誤差を修正するための運動指令を出す方法です。
感覚フィードバック(視覚や触覚など)を使って運動を調整するので、動きの精度が上がります。
FBの良いところは、動きながらリアルタイムで誤差を修正できることです!
これで動きの精度が上がり、目標に正確に到達できます。一方で、感覚情報の処理には時間がかかるため、素早い動きには向いていません。
例えば、ペットボトルを取る動きでは、手がペットボトルに近づくにつれて視覚と触覚情報を使って手の位置や力加減を調整することで確実にペットボトルを掴むことができます。
メリット・デメリット
メリット

動きながらリアルタイムで誤差を修正できる
環境の変化に柔軟に対応できる
デメリット

感覚情報の遅延があるため、素早い動きには向かない
遅延が大きいと動きが不安定になることがある
順モデルと逆モデル(内部モデル)

さて、ここからはもう少し深くFFを見ていきましょう👀
FFは内部モデルというもの用いていまして、内部モデルにはさらに「順モデル」と「逆モデル」という2つのモデルがあります✌️
内部モデルは、運動を計画し実行する際に必要なシミュレーションや予測を行う脳の仕組みです。
まずは、イメージがしやすい逆モデルから解説していきます!
補足:逆モデルの所在について
内部モデルは主に小脳に存在するとされています。なので逆モデルも小脳で生成するとされていますが、「逆モデルは大脳皮質で生成される」「逆モデルは小脳には存在しない」といった報告もあります。また、能動的推論のようなそもそも「逆モデルも順モデルも存在しない」という意見もありますので、まだまだ研究の余地がある領域になっています。
ですので、説明の便宜上「逆モデル」「順モデル」としていますが、名称を覚えるよりもどのような流れで運動制御が行われているかを理解することをオススメします‼️
逆モデル

逆モデルは「目標とする運動を行うために必要な運動指令を生成する」モデルで、いわゆるイメージ通りのFFですね!
特定の運動目標に対してどの筋肉の動きが必要かなどを計算します。
例えば、ペットボトルを取るために腕をどう動かすかを決めています🫵🏻
ちなみになぜ「逆」モデルかと言いますと、これからの運動(未来)を過去の経験に遡って(逆)、予測していくからです🕰️
逆モデルは比較的イメージしやすいかと思います!
問題は次の順モデルですね!分かりやす解説していきますね😁
順モデル

順モデルは、「ある運動指令がどのような動作を引き起こすかを予測する」モデルです。
ん???
運動指令が実際にどんな結果を生むかを予測します。
これで予測と実際の結果を比較して、必要に応じて運動指令を修正します。
んんん???
いや、よくわからんっ!
ってなりませんか?(そう思うなら書くなよw)
まず、順モデルの「順」の意味から紐解いていきましょう!
さっきの逆モデルとは反対の意味になりまして、これから起きる運動や得られるであろう感覚(未来)を予想するため、「これから起こっていくこと=時間的な順序に従う」となり、順モデルと言います。

なぜ未来が予測できるかと言いますと、現在の状態(身体図式など)と運動指令(逆モデルからの遠心性コピー)が分かっていれば、次にどんなことが起こり得るかは予測できるからです!
分かりやすくするなら
未来(予測)=今の自分(身体図式)+運動指令(遠心性コピー)
↑これが順モデル
ちなみに次に解説するオブザーバーモデルは、この順モデルとめちゃくちゃ関係が深いので、またそちらでも詳しく説明しますね!
とりあえずここでは、これから起こること(時間的な順序に従った)を予測しているモデルということを理解しておきましょう👍

1つ例を挙げるなら(上図)、ペットボトルを取る動きでは、逆モデルが手を伸ばすための運動指令を出すのに対して、順モデルはその指令に基づいてこれから起こる手の動き(こんな感じで手が伸びるだろうな〜)を予測します。
実際の動作と予測した運動(とそこから予測される感覚)が一致しているかを確認し、必要に応じて運動指令を修正します(モニターしている)。
順モデルと逆モデルは、運動の計画と実行を効率的に行うためにめちゃくちゃ重要で、運動制御の中心的な役割を果たしています🕺
順モデルがイマイチわかりにくかった方もご安心ください!
次のオブザーバーモデルでさらにわかりやすく解説していきます🫡
オブザーバーモデル

オブザーバーモデルについてです✨
※上図を見ながら読み進めてくださいね!
オブザーバーモデルは、感覚フィードバックと予測(順モデル)を統合して運動の精度を高めるためのモデルです。
このモデルの最大の目的は、感覚運動遅延の保証と運動の精度向上です👍
逆モデルとFBしかなかった場合、一回運動を行なって感覚フィードバックとしてエラーが入ってこないと運動の修正ができないわけです。。。
これだとめっちゃ困りません???
初めてやることは絶対に1回以上は失敗しないといけないなんて・・・
(毎回ペットボトルをとる時に、取りこぼしてたらもう飲みたくなくなりますよね😱)
でも、実際は予想よりも重かったペットボトルも落とさずに掴めるわけですよね?(「あれ?思ったより重い」とは思うかもですが)
これはオブザーバーモデルのおかげなわけです!!!
このモデルでは、逆モデルの遠心性コピーに加えて、順モデルの「順動力学的モデル」と「順感覚モデル」が使われます。(あと感覚フィードバック)
待って、待って🫸
ん???
順・・・何モデル???
分かりやすくするって言ったよね?
そうなんです順モデルはさらに2つに分かれるんです💦
ただ、これが意外と分かりやすくてですね!
順動力学的モデルは、運動コマンドを遠心性コピー入力として受け取り、運動の力学的(位置・速度・力など)な結果を予測します。
つまり、「この筋肉を動かして、こんな関節運動をしていくよ〜」みたいな動力学的な運動コマンドが逆モデルから入力(遠心性コピー)されることで、「こんな運動をするのね」と運動を予測するわけです🏃♀️
そして、その運動コマンドを予測する(順動力学的モデル)ことで、起こるであろう感覚の予測も可能になります!
これを順感覚モデルと言います👍
ここで大切なのは、遠心性コピーから入る情報はあくまでも運動情報(動力学的情報)であり、感覚情報は入っていません。でも、手が動いたらどんな感覚が起きるかな?と予測することはできます!(細かい話をすると運動司令を効果器へ伝える皮質脊髄路には感覚成分が含まれています)
これによって順感覚モデルは成り立っているということですね😉
さて、ようやくここから本題のオブザーバーモデルの説明です!

この図を順番に説明してきます。
オブザーバーモデルとは
①逆モデルにて運動指令が効果器へ投射されつつ、遠心性コピーを順モデルに送る(前の状態推定)
②順動力学的モデルが、遠心性コピーと現在の身体状態(身体図式)からこれから起こる運動を(動力学的に)予測する
③順動力学的モデルの予測に基づき、順感覚モデルが運動によって得られるであろう感覚フィードバックを予測する
④実際の感覚フィードバックと順感覚モデルを比較する
⑤エラーが生じた場合には、感覚にもとづいた修正を行い最適な運動の予測をする(最終的な状態推定)
⑥これまでの手順を何度も繰り返していくことで精度の高い運動を素早く行っていく(運動学習)
これらの手順によって、素早い対応が可能となっています✨
結果(運動遂行完了)が分かってから運動を修正するよりも、ある程度運動を予測(状態推定)して予測とズレたら(感覚フィードバックをもとに)リアルタイムで修正する方が圧倒的に速いのは容易に想像つきますよね😚
このオブザーバーモデルのおかげて、感覚情報の遅延やノイズが補正され、運動の精度と安定性を高めることができているということですね!
最後は、このオブザーバーモデル(FF)を用いたFBの解説です✏️
最適フィードバック制御

最適フィードバック制御は、課題目的達成に関連した誤差だけを修正し、課題目的達成に関連しない誤差は許容することで、最小限の介入で運動を制御する方法(最小介入原理)です🫰
これによりエネルギー効率を高め、運動の精度を向上させることができます!
運動するわけですから、なるべくコスト(労力・不正確さ)は小さくしたいですよね😂
(無限に体力があるなら別ですがww)
先にも述べましたが、最適フィードバック制御は、最小介入原理に基づいて運動を修正していきます。
例えば、ペットボトルを取る動き(上図)では、ペットボトルまでリーチする距離(横軸)がずれてしまうと取ることができなくなるので修正対象となります。一方で、ペットボトルの高さの範囲内(キャップでも中央でも底面でも)であればどこでも取ることができるので、縦軸のエラーは許容し、コストを小さくすることができます💰
このように、FBが常に運動指令によって発現したすべての運動(今回の例ではペットボトルを把持する際の縦軸のズレ)を邪魔しない軌道に戻すのではなく、課題目的達成(ペットボトルを取ること)に対する邪魔(今回はリーチのズレ)を減らすように働くことが、最適フィードバック制御にとって重要な要素となっています🫡
ちなみに、最適フィードバック制御ではFFとFBを厳密には区別しておらず、オブザーバーモデルの情報をもとに状態推定を行なっているようです!
最適フィードバック制御は、運動の効率を最大化し、エネルギーの無駄を減らすためにとても重要な運動制御ですね🏃♀️
まとめ
随意運動がこれだけスムーズにできているのは、今回紹介した運動制御がしっかりと働いてくれているからです‼️
フィードフォワード制御、フィードバック制御、順モデルと逆モデル(内部モデル)、オブザーバーモデル、最適フィードバック制御と主な運動制御には触れましたので、これらをしっかりと理解していきましょう!
あえて脳の部位には触れていませんが、この情報をさらに脳科学・神経科学ベースで理解できると、脳卒中の患者様がなぜうまく運動が行なえていないのか?が少しでも理解できるかもしれません🧠
また、今回の記事で分かっていただきたいことは、FFとFBは別々に考えるというよりも、同時に処理してお互いに助け合いしながら運動を素早く適切に制御しているということです!
運動制御に感謝しながら、今日もペットボトルを取ってみましょう(笑)
では、また!
参考文献:
McNamee, D., & Wolpert, D. M. : Internal Models in Biological Control. Annual Review of Control, Robotics, and Autonomous Systems, 2, 339-364.2019
望月久 (編):バランス障害リハビリテーション 障害像を明確にとらえるための基礎論と評価・治療の進め方, メディカルレビュー社, 2021
望月久:神経系理学療法領域におけるバランスの捉え方の今日的課題. 理学療法ジャーナル52(9):791-800, 2018
Eric R. Kandel(編):カンデル神経科学 第2版, メディカル・サイエンス・インターナショナル, 2022
Ann Shumway-Cook,et.al:モーターコントロール 研究室から臨床実践へ 原著第5版.医歯薬出版株式会社.2020
この記事が気に入ったらサポートをしてみませんか?