
アダコテックのテクノロジーがよくわかるnote

アダコテック、という一風変わった社名の由来は、柔軟に(adaptive)様々な認識(cognition)ができる技術(technology)の頭部分をくっつけてます。

根っからのテクノロジーカンパニーなのですが、なかなか技術の中身をきちんとお伝えしきれてないなと感じています。なので、今回は、弊社の技術に興味を持って頂いた方向けに、少し踏み込んで、アダコテックのテクノロジーをご紹介しつつ、どのような開発をしているのかを紹介します!
なお、ビジネスの全体像については以下noteをぜひご参照ください!
製造業の検査を行うための画像解析は”激ムズ”である

上記のようなものが、よくあるレベルの現場の課題になります。
■表面が不均一&形状が複雑
■欠陥の種類が多い
■正常品にもそれなりにバラツキがある
というなかなかのエンジニア泣かせなもので、しっかりとした撮像環境に加え、綿密な画像の前処理とパラメータ設定が必要になります。
検査自動化を阻んできた”シックスシグマの壁”

製造業の品質基準は「シックスシグマ」と呼ばれます。100万回の作業を実施しても不良品の発生率を3.4回に抑えるという基準です。普段の生産で不良品がほとんど出ないため、不良のデータサンプルが極めて少ない。検査基準も当然100%の精度(見逃しゼロ)が絶対基準です。つまり、さきほど紹介したような難しい画像に対し、少量のデータサンプルで100%の精度が求められます。(勘の良い方は、Deep Learningのように大量のデータが求められる技術とこの課題の相性が良くないことをご察し頂けるかと思います)
「いつもと違う」を見つける革新的な手法
アダコテックが提案するのは、少量の正常データから異常を検知する手法(教師なし学習)です。製造現場にデータが少ないのであれば、正常データだけでモデルが作れるのが理想で、これを可能にするのが、HLAC*と呼ばれる極めて効率的な特徴量抽出法です。(*HLAC=高次局所自己相関特徴抽出法)
このHLACは、とても正確に、かつ、画像解析のための様々な工夫がしやすい形で、画像の特徴を表現します。画像の切り出しが不要で、位置不変性、加法性といったパターン認識に好ましい特性を持っています。
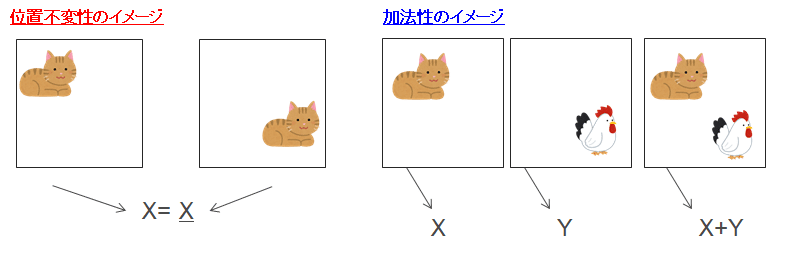
HLACの仕組みはとてもシンプル、だから使いやすい
HLACは、3ピクセル×3ピクセルの25種類のマスクパターンを用いて、極めてシンプルに画像の特徴を表現します。
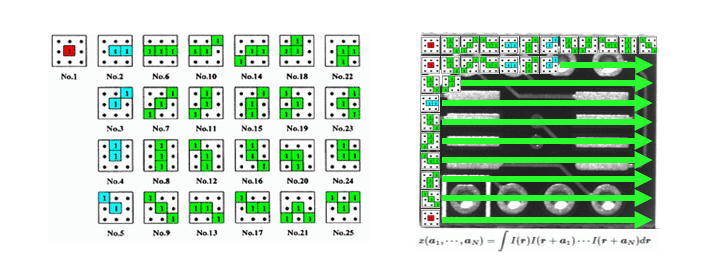
上記で赤・青・緑と色が塗られた箇所の輝度値の相関を計算していきます。たとえば、画像の特徴を掴むためには、25種類のマスクパターンを画像に対してスキャンし、25種類のマスクパターンがどこに、いくつあるのか、数え上げていくような仕組みで特徴量を表現します。後段の処理は、以下の通り主成分分析によって正常な範囲をモデル化しています。
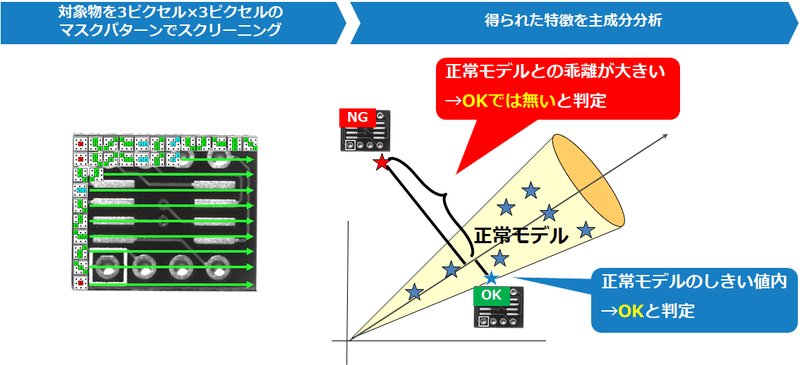
現場思考で生まれた技術 - Deep Learningとの違い
アダコテックとしては、こと”検査”という課題においては、Deep Learningのような複雑な計算をするよりも、HLACという汎用的な特徴量を使用したほうが、データ量も計算量も少なく、ロジックもシンプルで試行錯誤がしやすいので現場で使いやすいという発想で考案されています。
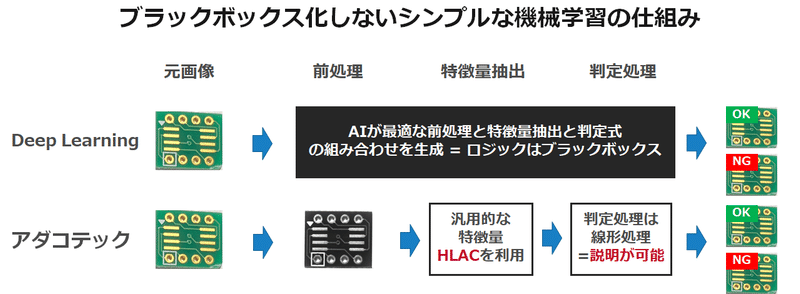
上記のようにDeep Learningを用いると、データ量が増え、計算が複雑化してしまうところを、HLAC特徴抽出法を用いることで、データ量を少なく、かつ、シンプルな形で実現しています。ロジックが説明可能であり、計算量も少ないので汎用でパソコンで動くという利点も、製造業のお客様に評価頂けているポイントで、世界的な製造業のお客様にも多数採用頂いています。
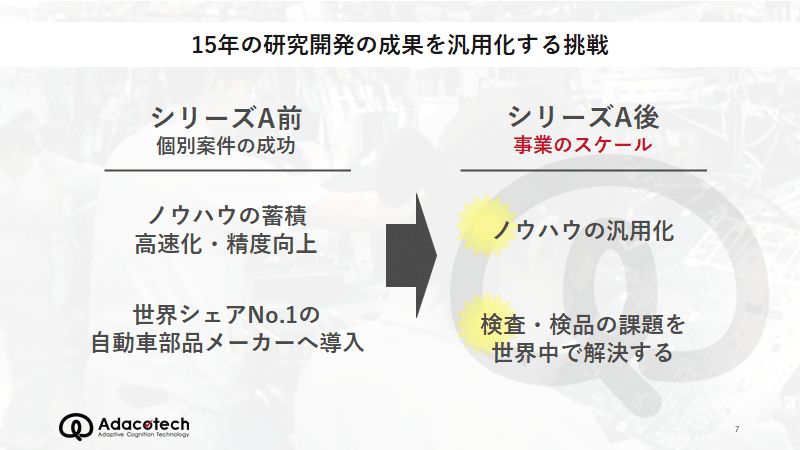
プロダクト開発の背景
いま、アダコテックは転換期にあり、これまで15年かけて研究開発してきた成果をより多くの方に届けるために、ノウハウを汎用化する挑戦をしています。これまではお客様の課題解決が、創業者の伊藤・伊部の画像解析のノウハウに依存しておりましたが、そのノウハウをアプリケーションに搭載することで、事業としてのスケールを目指しています。
プロダクト - ノーコードで実現する新しい検査体験
プロダクトの構成は以下2つに分かれています。
①機械学習アプリ:クラウド上で画像データをもとに異常検知モデルを生成
②エッジアプリ :工場ラインで異常検知モデルを実行する
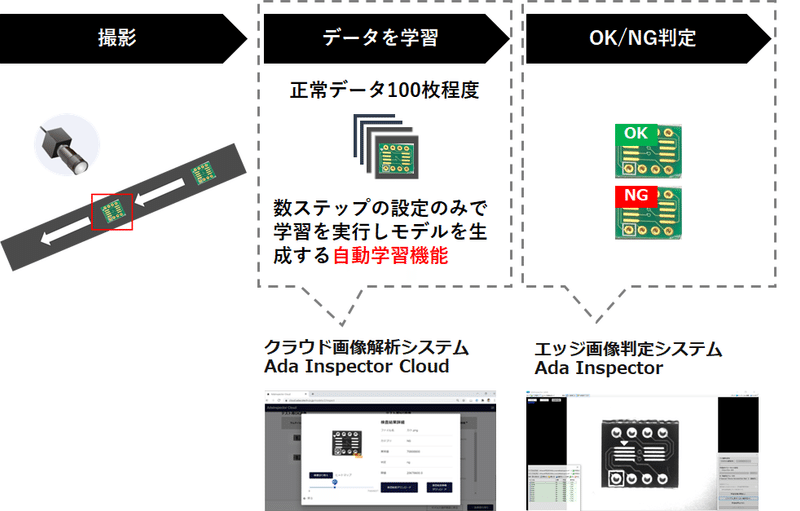
目玉となっているのが自動学習機能です。
製造業の検査・検品を、AIを活用した画像解析により自動化する場合には、検査対象となる製品画像の前処理の最適化、複数パターンの組合せによる学習手法の最適化処理、性能と処理速度を実現するためのプログラミング能力等が開発者には求められます。また、構築したシステムの検査精度を最大化するためにパラメータの調整や精度の評価も不可欠で、実用化に至るまでこれらの作業を試行錯誤的に繰り返す必要があり、エンジニアの熟練した技術やナレッジが要されます。「AdaInspector Cloud」は、難易度の高い検査・検品の自動化システムの構築と製造現場での実行を、 プログラミングの必要なくかつ簡潔かつ直感的な操作で実現するシステムです。(ぜひ面談ではデモを披露させてください!)
開発の難しく面白いポイント
アダコテックは独自のAI技術が、競争力の源泉になっています。この強みを最大限発揮できるサービス作りが開発のミッションですが、最大で数ギガのファイルをアップロードして処理したりする流れを、安定的かつストレスなく提供し続けることが難しさの一つです。今後のサービス拡大にも備え、ソースコードやデータベースが肥大化する前に最適な単位に疎結合・高密度にアップデートし続けることが求められます。また、製造業のお客様のワークフローは様々ですので、局所最適になる個別化は避けつつも、本質的な機能については開発して取り込んでいくというバランス感のあるサービス作りが肝となっています。また、もう一つの特長として、Webエンジニアも機械学習に携わる機会が多く、AIに関する知識を吸収できる機会も多いのもアダコテックでエンジニアをする面白さです。
進化を続けるHLAC技術と今後の開発の方向性
アダコテックには、画像解析の世界的権威である大津展之先生(工学博士 産総研 名誉リサーチャー)はじめ、3名の技術顧問のもと、R&Dを継続しています。直近でも、最新論文がICPR2020に採択されました。画像前処理を最適化するための技術であり、今後AdaInspector Cloudに実装することで、更なる精度向上が期待できます。これ以外にも、精度向上や汎用化に繋がる複数の研究テーマがありますが、HLACだけでなく、最先端のDeep Learning技術との組み合わせなども含め研究を続けていきます。
一方、サービスとしては昨年末にβ版をリリースし、当面は、正式版に向けた開発を続けていきます。現在はユーザーの最も深いペインを解決するためのMVPが準備できた状況で、これから顧客と向き合いながら様々な機能を追加していく予定です。たとえば、検査するだけではなく、欠陥の種別ごとに識別を行い、リアルタイムでどのような不良が発生したのかを製造部門にフィードバックできるような仕組みを開発中です。その他にも、クラウド上に研究開発用のサーバーを立て、より専門性の高い解析や他技術との組み合わせも模索するなど、様々な取り組みがありますが、β版に対するユーザーの声を拾いながら試行錯誤していきます。
検査の世界は広く、現在は国内の自動車部品産業をメインターゲットにしていますが、今後は、電子部品・医療器具・繊維・電化製品・食品など、検査に深くペインを掲げる業界への展開や、海外のマーケット(独・米のような人件費が高い製造国が最初のターゲット)へ展開する計画で、展開に合わせてプロダクトの可用性をさらに高めていくのもテーマです。
最後に
少しでもご興味をお持ちいただけた方へ。以下の職種を絶賛募集中です。
「まずは話を聞いてみたい」ということでも歓迎です。下記のリンクからご連絡いただくか、直接私までDM頂けると嬉しいです!
----------------
Engineer
・フロントエンドのリードエンジニア
・バックエンドエンジニア
・PM
Apendix:技術スタック、システムアーキテクチャ

開発言語、ライブラリ
バックエンドのメイン言語をPython3にしています。サーバの要件に応じて、DjangoとFlaskを使い分けています。また機械学習のパラメータ分散最適でGo言語を採用しました。フロントエンドのフレームワークはReact & TypescriptSPAとしてサービスを実装しており、軽量かつ独立性の高いアーキテクチャを実現しています。
CI/CD
ソースコードのバージョン管理はGitHubを利用しています。CodeDeployを使って、GitHubにpushするとdevelop環境に自動デプロイする仕組みを作っています。その他、自動テストやコードのチェックなどにGithub Actionsを利用しています。
分析基盤
ログはfluentbitを使って、S3に置かれます。KPIなどはAthenaを使って取り出して、可視化はQuicksightを使っています。
インフラ
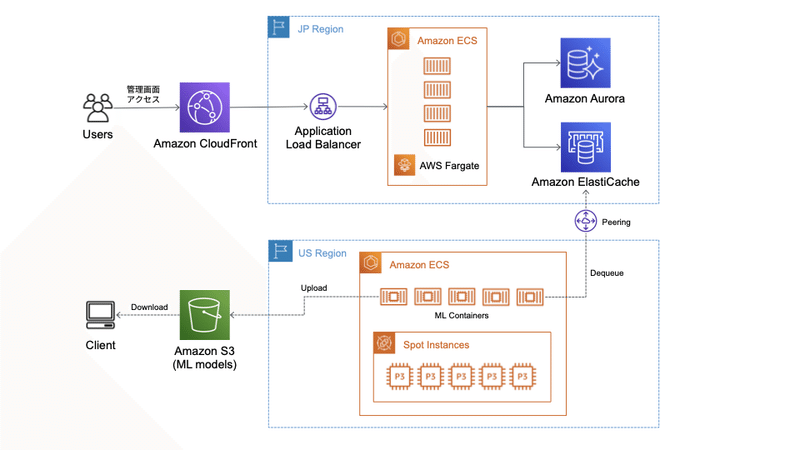
Web アプリケーションのフロントエンドは React を用いた SPA になっており、コンテンツを Amazon S3 に配置して Amazon CloudFront で配信する形式です。バックエンドの WebAPI は Amazon ECS on AWS Fargate で動いており、データベースは Amazon Aurora を用いています。
機械学習基盤はシステム要件上 CPU に負荷をかける処理が多いため、AWS Fargate ではなく Amazon EC2 ベースの Amazon ECS を用いています。Web アプリケーションと機械学習基盤との処理とのやりとりは、Amazon ElastiCache(Redis)でジョブキューを受け渡す形式です。ジョブキューをインプットとして AWS Fargate が起動し、機械学習用のサーバーを起動。学習に必要なファイルは Amazon S3 を用いて配置・参照します。
Web アプリケーションを構成するコンポーネントは東京リージョンに配置されていますが、機械学習側のコンポーネントは安価な US リージョンに配置。さらにスポットインスタンスも活用することでコスト削減につなげています。
また、Multi-AZ 対応を行っており耐障害性を高めています。セキュリティ面としては Amazon GuardDuty の導入を進めており、異常なアクセスを検出して早期に対応できる体制を構築中です。AWS CloudTrail は既にOrganizations 適用済みで、操作ログを全て取得できるようになっています。
【以上、2021年2月21日時点】
この記事が気に入ったらサポートをしてみませんか?