
Photo by
na081501015
機械学習②Irisdataを見てみる

機械学習でよく使われるIrisのデータみる
Irisdataは、R言語でもよく使われるdataで懐かしいと思った。
from sklearn.datasets import load_iris
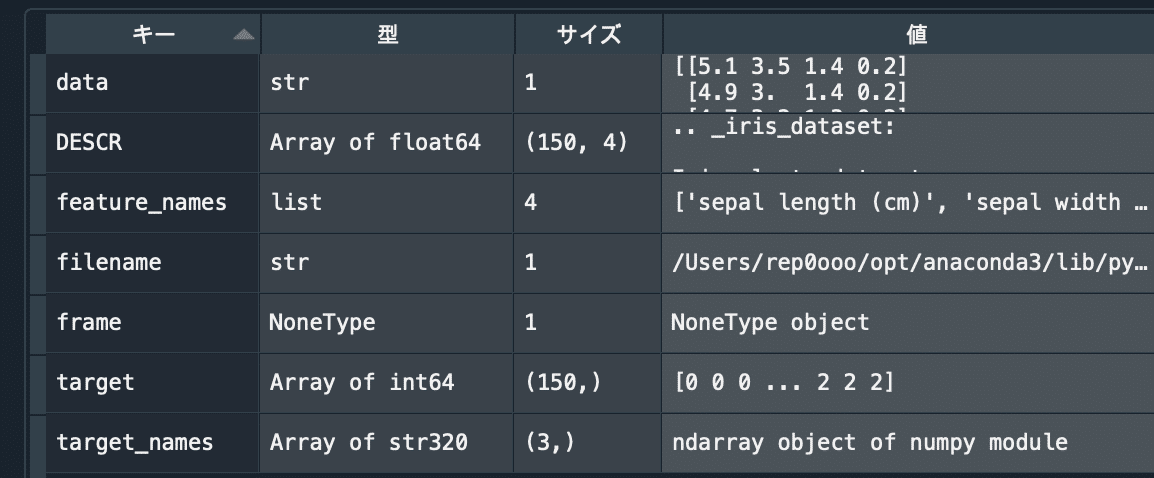
iris_dataset = load_iris()dataの中身は下記。
dataはIris150個の花びらの長さと幅、ガクの長さと幅をセンチメートル単位で測定したもの。
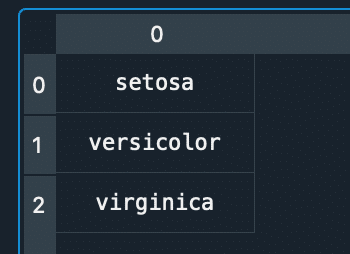
targetとtarget_namesで0はsetosaを、1はversicolorを、2はvirginicaを意味する。

機械学習はじめ「訓練データ」「テストデータ」を分ける
機械学習モデルの性能を評価するには、ラベルを持つ新しいデータ(これまでに見せていないデータ)を使う必要がある。これを実現するには、集めたラベル付きデータ(ここでは150のアイリスの測定結果)を2つに分けるのが一般的である。一方のデータを機械学習モデルの構築に用いる。こちらを訓練データ(training data)もしくは訓練セット(training set)と呼ぶ。残りのデータを使ってモデルがどの程度うまく機能するかを評価する。
random_state=0の理由:train_test_split関数は、分割を行う前に擬似乱数を用いてデータセットをシャッフルする。データポイントはラベルでソートされているので、単純に最後の25%をテストセットにしたりすると、すべてのデータポイントがラベル2になってしまう。3クラスのうち1つしか含まれていないようなデータセットでは、モデルの汎化がうまく行っているか判断できない。だから、先にデータをシャッフルし、テストデータにすべてのクラスが含まれるようにする。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
iris_dataset['data'], iris_dataset['target'], random_state=0)この関数を使うことによって、テストデータと訓練データを分けられる。

75%訓練データで、25%テストデータである。
データをプロットしてみる
# X_trainのデータからDataFrameを作る、
# iris_dataset.feature_namesの文字列を使ってカラムに名前を付ける。
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
# データフレームからscatter matrixを作成し、y_trainに従って色を付ける。
grr = pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)pd.plotting.scatter_matrixは教本とは異なるので注意すること。仕様が変わっている。
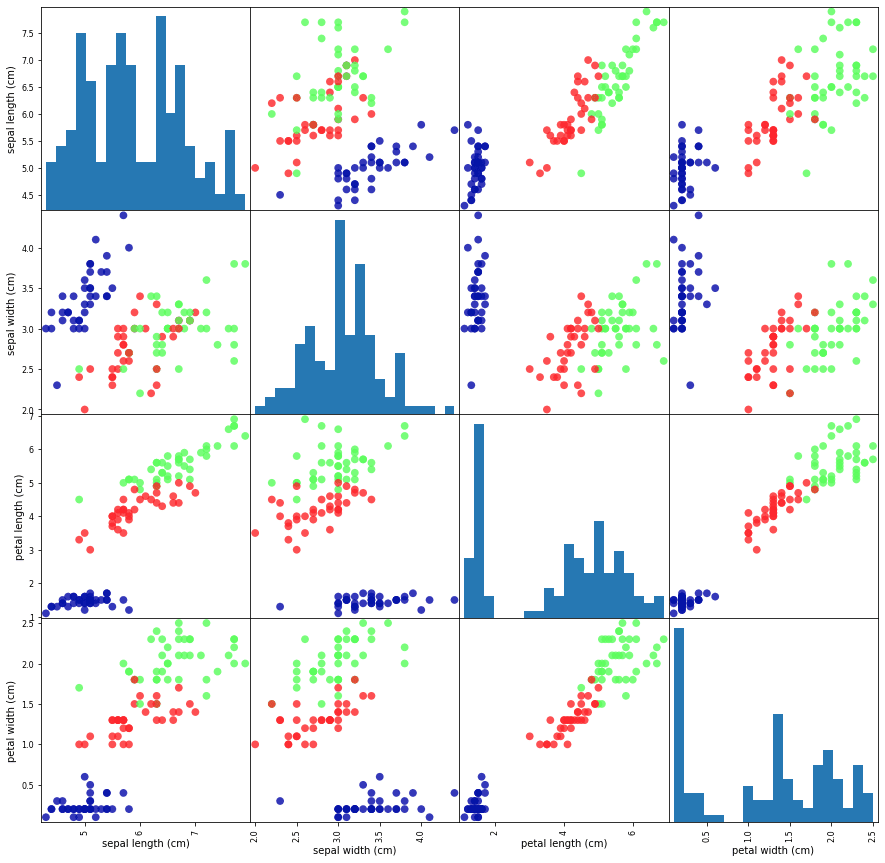
緑と赤と青の3クラスがよく分離しているので学習しやすそう。ということが見える。
次回は実際に機械学習をしてみる。
この記事が気に入ったらサポートをしてみませんか?