「天気の子」興行収入127憶円を408万ツイートで予測・説明する。2/3

このnoteは、合計2万字超えの分析コラムを3分割した2回目です。1回目は下記ですが、データ成形の仕方など、分析の詳細理解にこだわらなければこの2回目を読むだけでも「時系列データ分析による効果検証で何が分かるか?」を掴んで頂けることを目指して執筆しました。
【更新情報2024年5月26日】
「その決定に根拠はありますか?」
確率思考でビジネスの成果を確実化するエビデンス・ベースド・マーケティング
戦略を導く為の「エビデンスの作り方」をテーマに、これまで体系化してきたノウハウを紹介したマーケティング・インテリジェンスの書籍を出版致しました。5問の調査でTVCM(施策)→コンビニで商品を見た(要因)→売上がいくら増えたか?→年間16.67億円(効果)の様に経路ごとに構造的に効果を把握する国際特許(PCT)を出願した分析法など、確率モデルや因果推論をプロジェクトで実際に活用している方法を特典の動画講義も活用して実装レベルの知識まで提供しています。
前回のオチ
「興行収入を見守りたい」のデータを参照し、公開から59日で興行収入が127憶円を超えた9月15日までの「天気の子」の映画チケット販売数およそ964万回を推計し、
電通グループのCCI社が提供する全数ツイート調査ができるソーシャルリスニングツールのコミュニケーションエクスプローラー(以下CE)を使用して「天気の子」という単語を含む約408万ツイートを抽出して、時系列データの解析を行いました。
分析には、拙書「Excelでできるデータドリブン・マーケティング」で提供している付録の分析ツール(以下「付録ツール」)を使用しました。
販売数の説明に有効な要因として水曜と土日祝日、毎月1日(映画の日)とツイートを用いて分析したところ、興行収入の6割強がツイートによる影響ではないか?いくらなんでも、それは多すぎではないか?というオチでした。
前回はツイートを3変数に分割しましたが、今回はシンプルに1変数として分析します。
今回のオチ
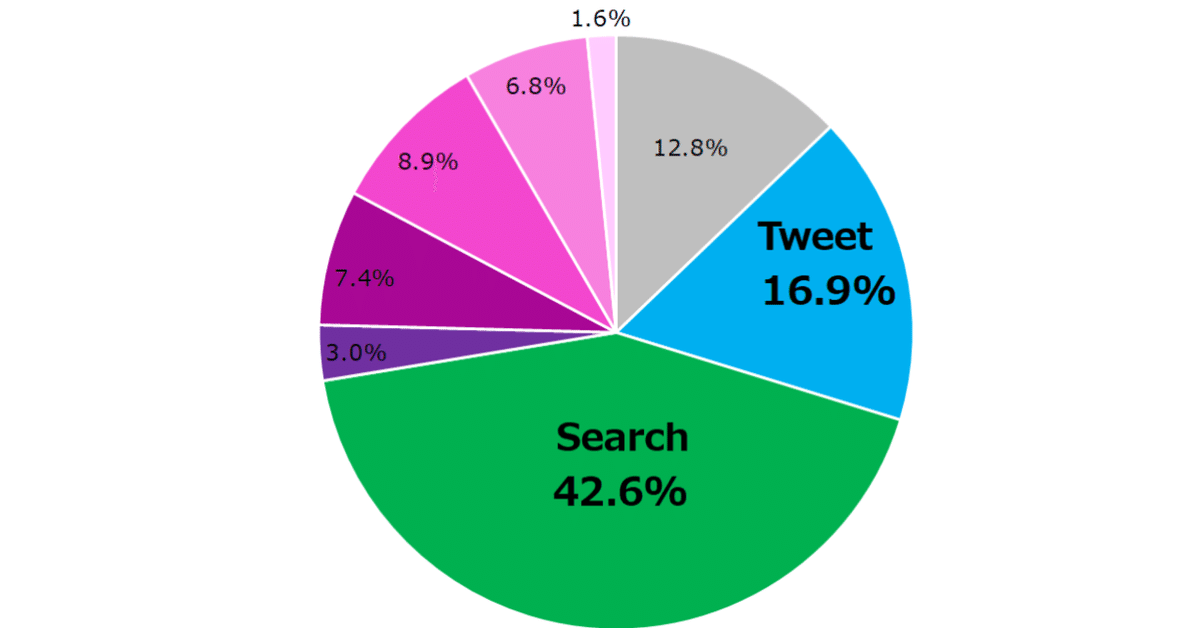
本noteのキービジュアルですが、これはのちほど紹介する回帰分析の結果から、天気の子のチケット販売数を説明する要因の割合を円グラフにしたものです。

指名検索数約4,995万回の推計データを説明変数として加えた結果、
販売数への影響はツイッターが16.9%程度に留まり、指名検索数のほうがより影響が大きいと考えられる。ツイートが6割強の興収に影響があるという前回の考察は間違えだった。
という結論に至りました。この考察を導いた分析を紹介します。
※ただし、指名検索数→販売数への影響はツイートを説明変数から外した別の分析から導く必要があります。詳しくは本文をお読み頂いた上で文末の専門的注釈事項を参照ください。
最近、マーケティング業界で話題のホットリンク社の飯高氏の書籍、「僕らはSNSでモノを買う」でも、指名検索が重要であることについて言及されています。このnoteも読んで頂ければさらに理解頂けると思います。
1回目のnoteでは、広告などの効果の定量化は避けるとしていましたが、それが知りたいという意見を多く頂戴したため、CEを使って広告とPRを表せそうな変数を成型し、それを説明変数にすることで、広告とPRがそれぞれ指名検索数をいくつ増やすか?考察しました。
その結果、
決定係数(≒予測精度96%)超えの回帰分析モデルによって、広告やPRによって指名検索がいくつ増加しているか?定量化出来ました。
また、私が好きな映画(でも、見に行くタイミングを逃した)アベンジャーズ/エンドゲームでも分析してみましたが、同様の分析結果が得られました。
「天気の子」の単語を含む約4,995万回の指名検索数を推計
Googleトレンドを使いました。同ツールで調べられるのは、対象期間の検索数の最大値を100とした相対指数のデータです。また、「天気の子」でそのまま検索した場合にはデータは出ませんが、関連キーワードとして「天気 の 子」という空白スペースを含むワードが出てきますので、そのワードで調べ直し127憶円の興収に対応する7月19日~9月15日のデータを抽出しました。
※スペースが入るのはグーグルトレンドやキーワードプランナーでたまに見られる事象です。
リスティングで使用するGoogleキーワードプランナーは、「完全一致」キーワードでの実数が月単位で取得できます。「天気の子」について調べる人は、「天気の子」単語単体ではなく、「天気の子 評判」などの複数単語の組合わせで検索することも多いと思います。これを掛け合わせキーワードと言います。「天気の子」の検索は(ブランド名単体の)完全一致キーワードと言います。
キーワードプランナーで取得した「天気の子」の2019年8月の完全一致の検索数は500万回でした。これを5倍した2500万回を8月の「天気の子」指名検索数の総数と考えます。これは、グーグルだけではくヤフーなど他の検索エンジンもあること(×2倍)と、(ブランド単体ワードの)完全一致だけでなく、ありとあらゆる掛け合わせキーワードを含めた場合は(※×2~2.5倍)ほどになることが根拠です。
Googleトレンドから抽出した検索回数の相対指数データの8月分の値が2500万回になるように補正し、指名検索数の実数を49,958,368回と推計しました。
※ECサイトなどの場合は、ブランド名単体から掛け合わせキーワードを含めた検索数を推計するための倍数をさらに増やして考えることがあります。あくまで筆者の分析経験値による目安です。実際には競合アクセス調査ツールなどを用いてより精緻に調べる場合もあります。今回は2.5倍として考えました。
指名検索数を追加して回帰分析
推計した「Search」を説明変数として加えて分析してみます。この結果を【model1】とします。
以降は文章で説明せず分析結果の画像に【model1】と付与するのみとします。

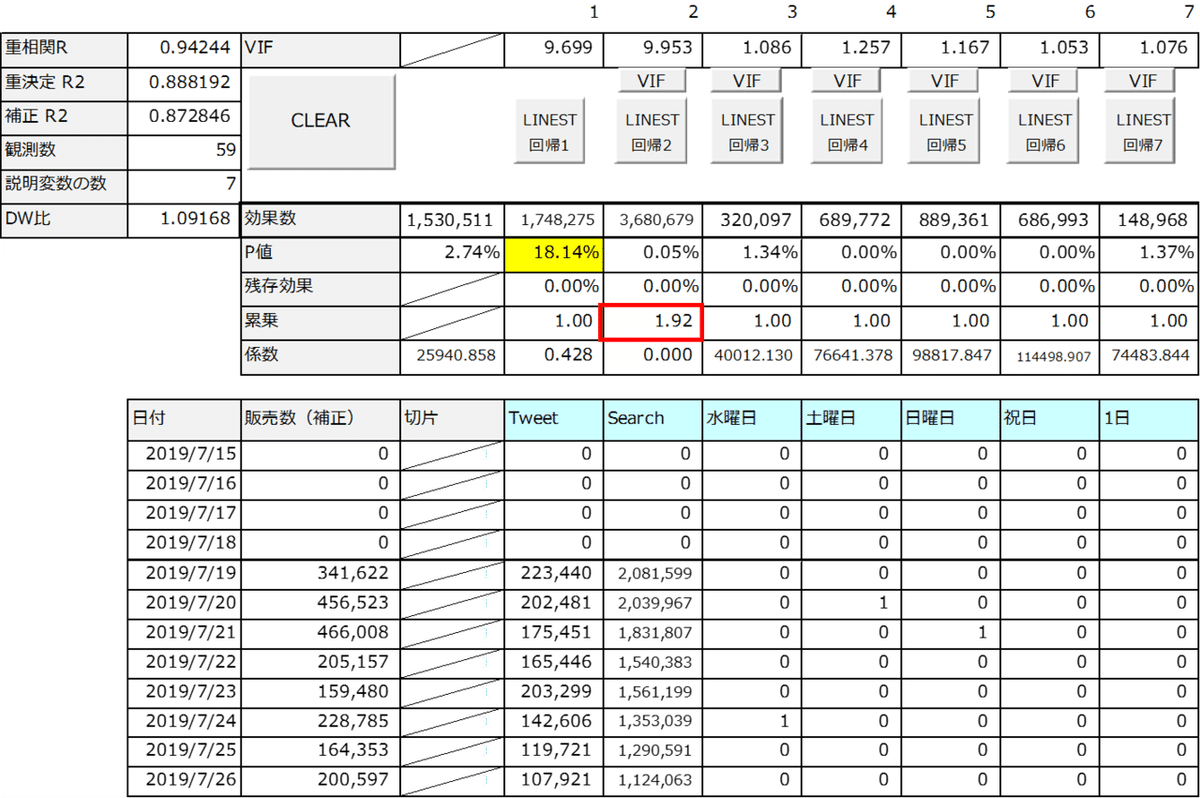
Searchの係数が負の値、-0.829になってしまいました。これは多重共線性と言う分析上のエラーのようなものです。SearchとTweetの2つの変数が非常に強い相関(相関係数0.96以上)となっているために起きている症状で、係数の値が不安定になってしまい、プラスとマイナスがひっくり返ってしまったりします。
分析に使用する説明変数の数量(ここでは7個)に応じたVIFボタンを押すと、多重共線性の可能性を検定するための値が出ます。この値が10を超えると多重共線性の疑いがあります。セルが黄色く自動着色されます。
Searchの係数の上にある累乗という値を0.01単位で大きくしながら、回帰分析をやり直していくと1.92という値から、VIFが10を下回ります。(切片の値もプラスに転じています)
【model2】
これはSearchの値を1.92乗に変形するための基準値です。2乗や3乗という数は皆さんご存知だと思いますが、1より大きな値で「〇乗」して回帰すると、Xの値が増えるほどYへの影響が逓増する非線形な影響を考慮できます。1.92乗だとこんな感じです。(下記図の赤い点線)

ちなみに、0.6乗だとこんな感じ(下記図の赤い点線)です。Xの値が増えるほどYへの影響が逓減する非線形な影響を考慮できます。

累乗という行の上の行は残存効果です。これは、TVCMなどの広告効果が減衰しながら持続する前提を考慮するために、もとの変数を変形する基準値です。例えば、実際に1週目に1000GRPしかTVCMを投下しなかった場合、残存効果を「50%」と考える場合は、以下の図の様にもとからある変数(ここではTVCMの投下GRP)の値に10期先(ここでは「週」)まで50%ずつの残像効果分を加えた値に変形します。
※GRPはグロス・レ―ティング・ポイントというのべ視聴率を元にしたTVCMの出稿量を示す単位です。

付録ツールでは目的変数への影響が非線形である可能性を考慮した「累乗」と10期先まで効果が減衰しながら持続する「残存効果」の基準値を探索します。切片と各説明変数の係数もパラメーターとして、予測誤差(の二乗値)を最小化する値を探索します。(Excelにあるソルバーという最適化計算ツールで実行します)
詳細なロジックは拙書をご覧下さい。
Searchの累乗を1.92以上とする制約をかけた上で、TweetとSearchの基準値(累乗と残存効果)をソルバーで探索し、その後で回帰分析を行いました。
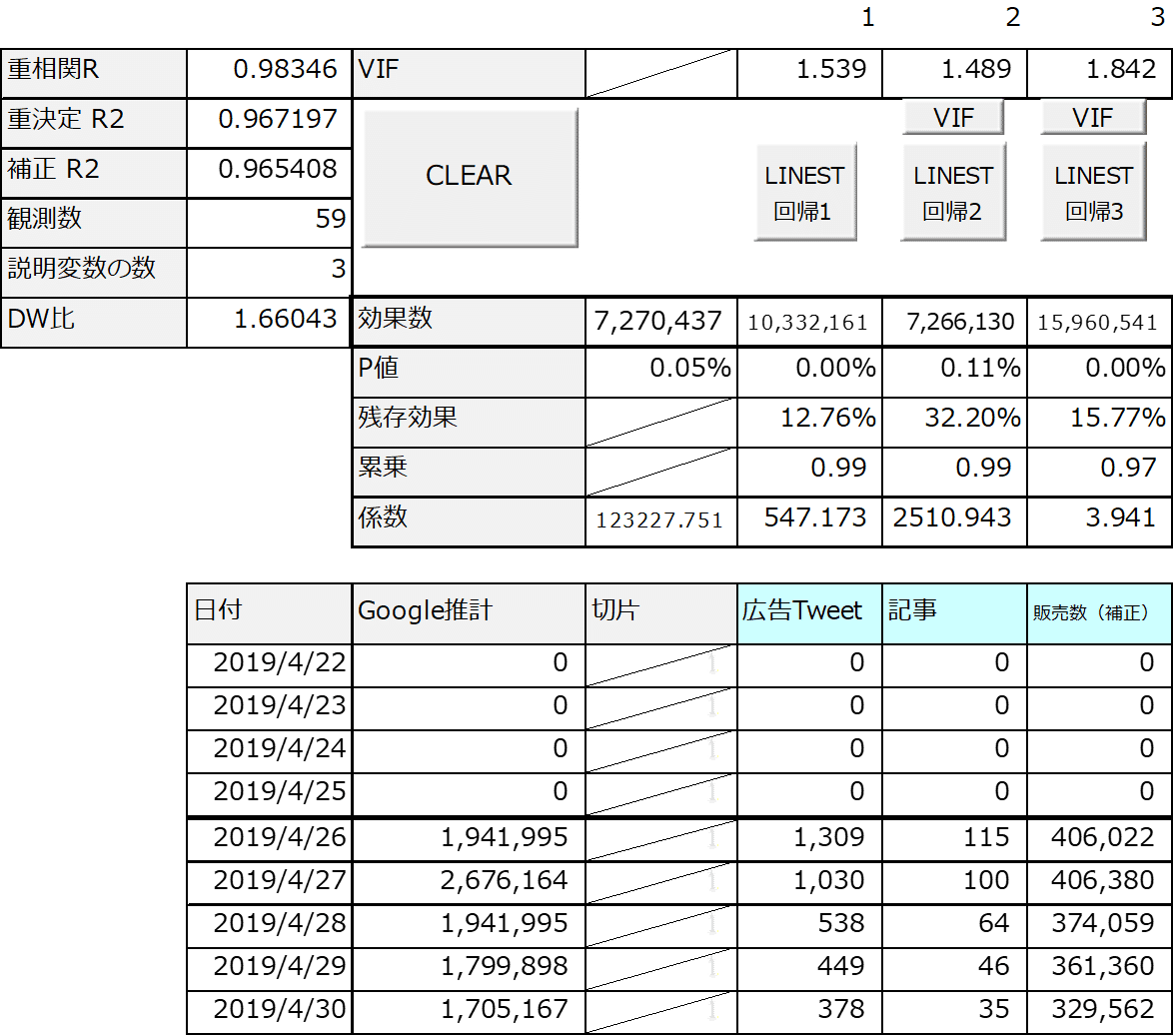
【model3】

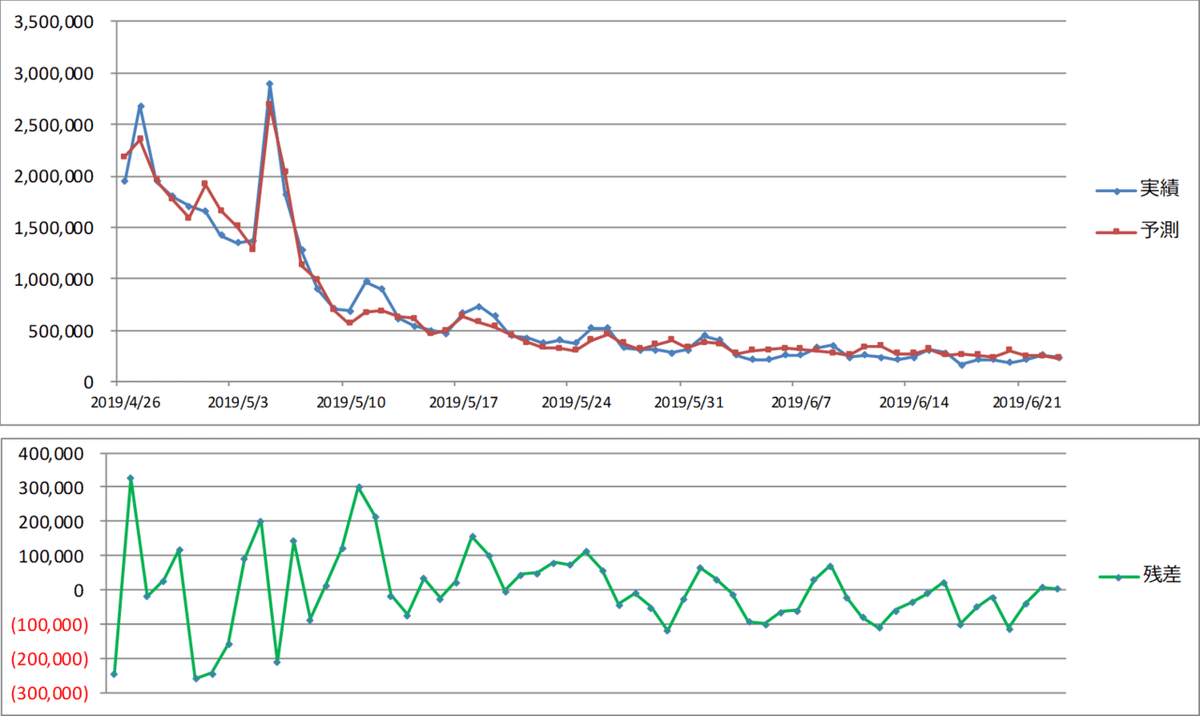
Searchの残存効果が25.29%に変わりました。VIFの値が10を下回っていますが、「Tweet」の係数のP値が有意水準としていた10%を上回りました。予測精度の目安となる決定係数(補正R2)は0.874135です。販売数の実績と予測値の折れ線グラフのプロットは下記となります。

キービジュアルはこのmodel3の結果から、切片、Tweet、Search、3つの曜日と祝日と映画の日が興収の何パーセントの増加に寄与したか?を求め、円グラフにしたものでした。


前回のnoteは興行収入の6割強がツイートによる影響ではないか?多過ぎるのではないか?というオチでしたが、今回の分析結果ではツイートによる影響は16.9%となり、大幅に減りました。これは、
交絡因子
による影響です。交絡因子とは、因果関係を把握したい原因と結果の双方に影響がある要因のことです。因果関係の把握を定量化して考察する際の障害となります。
身近な例で説明します。健康診断に行く(原因)と健康指標が良くなる(結果)のか?因果関係を考察するとします。すべての国民のうち、健康診断に行った人と行かなかった人に分けて、比較することで、健康指標を比べ、その差を健康診断の効果とする考察が考えられるかもしれませんが、
間違えた考察となる可能性が非常に高いです。

このケースで考えられる交絡因子は「健康意識」です。健康意識が高い人ほど健康診断に行く人が多いので、健康診断に行った人は、健康意識が高い人に偏ります。行った人、行かなかった人を分けた単純比較だと、健康意識が高いこと(原因)で健康指標が良い(結果)影響が加味されてしまい、本来興味のある健康診断による因果効果が分からなくなります。
こうしたバイアスを補正するため、例えば、アンケートなどで健康意識をスコア化して、スコアごとに行った人と行かない人に分けて健康指標を比較する方法(層別分析)や、より専門的なマッチング法といった方法を用いて交絡因子の影響を調整する方法などがあります。こうした因果推論について、一般向けに分かりやすく説明されている原因と結果の経済学をオススメします。
本コラムで活用している回帰分析においても、予測をメインにするのではなく説明、すなわち効果の把握に軸足を置く場合は交絡因子を意識する必要があります。
「天気の子」の検索数とツイート数と販売数の関係で考えてみます。円の大きさは回数の多さを表しましたが、ツイート(原因)→販売数(結果)の因果関係を回帰分析から考察する場合は、5,000万回近く発生していた指名検索数が交絡因子となっていると考えます。

指名検索数のように、原因と結果に対して影響のある交絡因子をモデルの説明変数から欠落させると、その分他の説明変数などに上乗せされるイメージです。だから、1回目のnoteではツイートの効果が過大となり、販売数の6割強に影響しているのではないか?という結果となっていました。
ちなみに、交絡因子はひとつではないことが殆どです。下記の図の様に広告やPRが、原因(ツイート)と結果(販売数)の双方に影響する交絡因子となっていることも考えられます。

広告やPRの効果を推定するための変数を作成
「広告」や「PR」によって指名検索は増えるのか?その影響を定量化するため、説明変数を加えてみます。
「天気の子」を含むツイートのうち、TVCMなどの広告や販促について言及しているであろうツイートを抽出し成型しました。TVCMなど広告の出稿量が多い時は、ツイート数も増えると仮説しました。抽出に使用したキーワード条件は下記となります。

本来はTVCM出稿量についてはビデオリサーチ社などのシンジケートデータを使用することが一般的ですが、今回はこれで代用します。広告統計データはマス媒体を扱い、シンジケートデータを契約しているエージェンシーや、CMを出稿できる事業主には馴染みがあると思いますが、そうした環境にないかたは扱ったことが無いと思います。
分析する方の門戸を拡げるために、ツイート数を広告の影響を表す変数として代用できないかチャレンジしてみます。
また、CEにはツイッターだけでなく、ニュースやブログの記事数を抽出する機能もあります。「ニュース・情報」というカテゴリーに限定し(ブログなどは除外)して「天気の子」の単語を含むWEB記事数を抽出しました。これをPRの効果を説明するための変数として活用します。

この2つの変数を現状のモデル(目的変数はチケット販売数)の説明変数として追加し、分析してみます。
【model4】

「広告Tweet」の係数はマイナスになり、再びVIFの値が10を超えてしまい、多重共線性の疑いが出てしまいました。
広告Tweetの変数を外して分析し直しました。P値は96%超えています。記事の効果数は21,477しかありません。
【model5】

記事が交絡因子である、つまり販売数とツイートの双方に影響することが、あらかじめ分かっている場合は、P値が有意水準を上回っても気にせず、交絡によるバイアスの影響を除去する役割を最優先にするため、説明変数として採用します。今回はVIFが10を超えるのを避けることを優先し記事の変数を外しました。
(59日の日別の)時系列データを回帰分析しましたが、広告やPRは、天気の子の販売数に対して直接的な影響がない模様です。
model3を目的変数を売上とした際の最終分析結果としました。
【model3】※再掲

※【model3】のTweetの係数のP値が20%を超えています。P値が20%だから、全く意味のない分析だと言い切れるものではありません。Searchの累乗の値をより大きく変化させてmodelを作りなおすことでSearchの効果を抑制し、Tweetの係数が上がりP値が下がっていきます。恣意的にP値を下げるためだけに、変数を加工してモデルを作りなおすことは可能ですが、これは恣意的に検索の効果を過小評価し、Tweetの効果を過大評価することにつながるため、今回はmodel3を最終分析結果とします。
指名検索数を目的変数として分析
指名検索数が販売数に大きな影響を及ぼすことが分かったので、次は指名検索数を目的変数として分析します。
この分析の主たる目的は広告やPR、販促が、指名検索数を増やすか?です。
付録ツールを使うことでサクサクとモデルを作り直し、モデルを進化させていく様子を動画でお見せします。

LINEST1を押したときは説明変数はTweetのみのモデル、LINEST2を押した時はTweetと広告Tweetのモデル、LINEST3を押した時はTweetから記事までの3つの変数を使ったモデルといった具合で回帰分析が行われます。
4つ目のRADWIMPSは8月5日のダミー変数です。1回目のnoteで言及していましたが、この日に「興行収入60憶円」を突破したニュースが出て、「RADWIMPS」による主題歌のひとつ「大丈夫(Movie edit)」を使用した特別映像が公開されました。これにより指名検索が増えている模様でした。5つめに加えた変数は「販売数」です。
LINEST5(説明変数5個)のモデルを作った後、ソルバーを使って、「累乗」と「残存効果」の値を予測誤差を最小化する関数でグリグリと探索しました。その後で回帰分析を行った結果が下記です。上記の動画の最後の画面と同様です。モデルを作り直すたびに、決定係数(補正R2)が上がっていきました。
【model6】

決定係数(補正R2)は0.979409となっており、時系列の予測と実績のプロットもあてはまっています。

この時の効果数の割合を表とグラフにします。

指名検索数の30.6%がTweetによって説明でき、31.4%が販売数によって説明できるという結果です。ツイート408万回によって、1,530万回の指名検索数が増えているということは、ツイートが1回増えると、指名検索数が3.75回増える関係です。感覚的にも腹落ちできる数値です。
「広告(広告Tweet)」「PR(記事)」「販売数」が原因と結果、双方に影響のある交絡変数であり、それを入れることで、(原因)Tweet→(結果)指名検索数の介入効果を概ね正しく推定できていると考えます。

しかし、今回の分析の目的は違いました。ツイート→指名検索の因果効果ではなく、
「広告やPR、販促が、指名検索数を増やすか?」です。
興味があるのは赤い線の因果関係です。この際、ツイートを入れてしまうと、中間変数といって、広告とPRの効果から水色の線の経路の効果が引き算されてしまうイメージです。
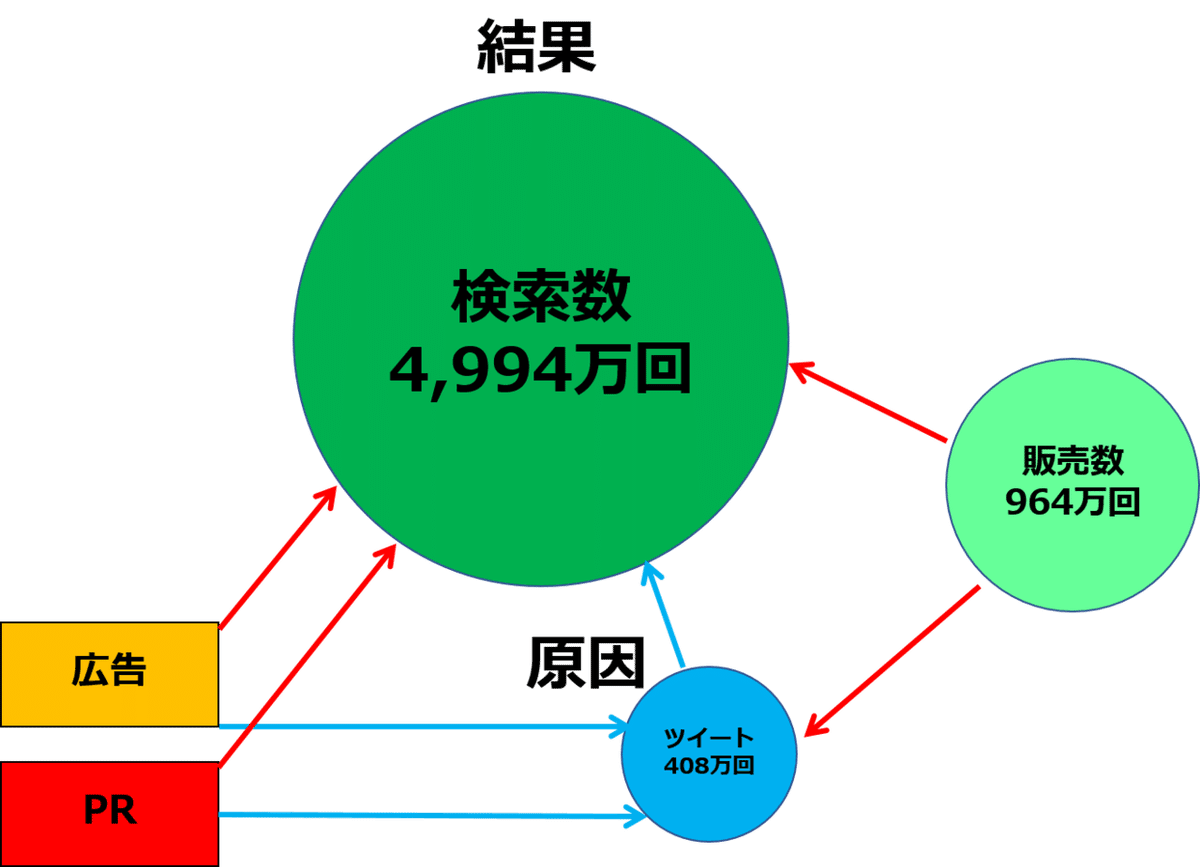
興味のある原因と結果の因果関係の間に位置する中間変数を説明変数を加えてはいけません。
ツイートの変数を外して、先程動画で示した、ソルバーによる累乗と残存効果の探索も行い、分析し直しました。
【model7】

決定係数(補正R2)は0.960980となっており、時系列の予測と実績のプロットもあてはまっています。

この時の効果数の割合を表とグラフにします。
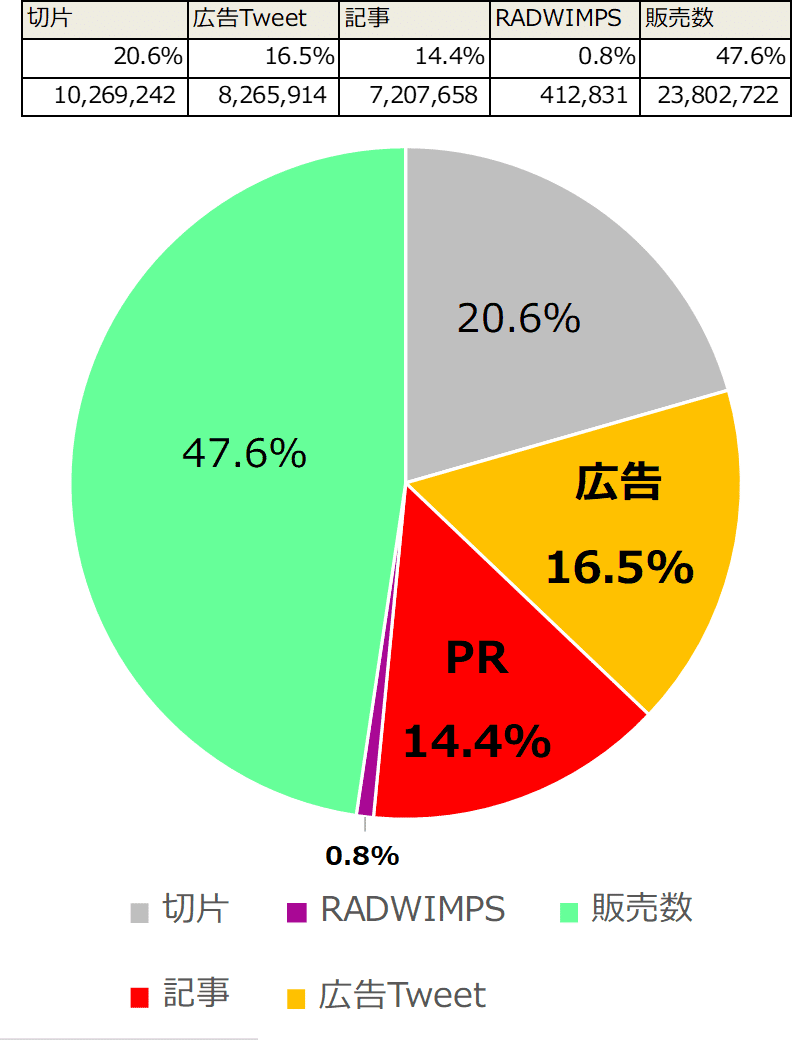
広告・PR・販促それぞれの指名検索数への貢献を定量化
広告によって、826万回増加、PRによって720万回増加、販促(RADWIMPS)によって41万回の増加を定量化できました。しかし、、、
広告について言及したTweet数
WEBの記事数
これを説明変数とした分析から「広告(全体)」や「PR(全体)」による効果を解釈して良いでしょうか?
ご説明しますので、まずはこの図をご覧ください。

今回使用した変数は「広告に関するTweet数」と「WEB記事数」だけですが、それぞれが背後にある「TVCMなど」「PRイベント」などの要因の影響を強く受けている可能性があります。
「PRイベント」や取材が多ければ、記事数も多いという強い関係が成立すれば、「WEB記事数」は背後にあるPRイベントなどを含めたPR全体を象徴する変動をしているかもしれません。同様に「広告ツイート数」は背後にある背後にあるTVCMなどを含めた広告全体を象徴する変動をしているかもしれません。
ほかに分かりやすい例を挙げます。下記はGoogleトレンドから抽出した相対指数と、全体の推計値です。補正係数の導き方(8月分を2500万回に合わせる)はすでに説明済みです。

24,979という補正係数をかけ合わせているので、相対指数と推計値の変動(折れ線グラフにした時のギザギザ)は同一です。回帰分析は、説明変数の変動によって目的変数の変動を説明する分析なので、変動が同じ変数であれば、回帰分析をした際の効果数も同一となります。Googeトレンドの値と推計値を入れ替えても効果数(目的変数にどれだけ影響を及ぼすか?)は変わらないです。
ただし、係数の値は変わります。Googleトレンドを説明変数とした場合は、検索全体推計値の係数と比較して24,979倍になります。また、効果数という統計用語はありません。回帰分析の結果から導いた係数から各説明変数によって目的変数にいくつ影響を及ぼすかを示した値を独自の用語です。
例えば指名検索数の1割のデータを収集できたとします。1割の変動が全数の変動と完全に同一の場合、それはすなわつ1割データが代表性のある標本になっています。そのデータを説明変数とした回帰分析の結果(効果数)は指名検索数の1割による効果と捉えてはいけません。指名検索数全てによる影響と捉えるのが正解です。
よって、「広告ツイート」と「記事数」が背後にあるTVCMやPRイベントの影響を強く受けている場合「広告ツイート」と「記事数」が「広告(全体)」と「PR(全体)」を象徴する変動を描いていると考えられますので、回帰分析によって導いた効果数は広告全体とPR全体による影響と捉えるほうが適切です。
それをより確実に調べるには広告統計やPRの実行の時系列を詳しく調べ「広告ツイート」と「記事数」の変動と照合する検証が必要ですが今回それはしていません。しかし、決定係数0.96を超える当てはまりの良いモデルができたので、確からしい気がします。他の映画作品で分析しても同じような結果が得られるか?確かめてみたいと思います。
「アベンジャーズ/エンドゲーム」で分析
楽しみにしていたのに見る機会を逃してしまった作品「アベンジャーズ/エンドゲーム」。過去に書いた「指名検索が多い映画は興行収入も多い説(映画編)」noteでは、この作品の興収を予測しました。
今回は、広告・PRが指名検索数をどれだけ増やすのか?天気の子と同様に分析しました。
各変数の集計方法、推計するための補正係数の使い方、分析日数、全て天気の子と同様に行いました。
【model8】

2作品の円グラフを並べてみます。若干「アベンジャーズ/エンドゲーム」のほうが広告とPRの貢献割合が多いようです。

広告Tweet、記事、販売数、それぞれ1単位あたり、指名検索数を何回増やすのか?整理してみました。

記事数の1単位あたり増加数は2作品とも非常に近しい値です。広告Tweetは2倍以上、販売数は1.3倍以上、アベンジャーズのほうが高くなっていました。アベンジャーズのほうがコアファンがいて、観た人1人あたりの検索数が多くなったのでしょうか?
ビデオリサーチ社やインテージ社などが保有するシンジケートデータにはTVCM接触3回以上のリーチ3,000万人など、推計できるものがあるので、リーチ1人あたり検索数0.2回増えるのか?0.5回増えるのか?できればそこまで落とし込みたいところです。 PRの費用は定価の無いフィーですし、こと映画については舞台挨拶など、監督や俳優の稼働も費用として試算すべきか?推計は難しいのですが、広告については広告統計データを使えば双方の作品の広告費を同じ基準で推計できます。どちらの広告が費用対効果が良いか定量的に比較出来ます。
指名検索数は重要な指標
ここまでの分析で分かったことの要点をまとめます。
・指名検索数は売上の4割強を説明する重要な変数だった。
・広告とPRは映画の販売数への直接的な影響は見られなかった。
・しかし、広告とPRは指名検索数を増やしていた。
映画は、公開前のティザー広告が重要です。公開前は映画のチケット販売数を目的変数とした効果検証ができませんが、指名検索数をKPIとして、TVCMなどの各施策を1円あたり指名検索をいくつ増やすのか?定量化して全ての施策を横並びで評価することができます。分析モデルを元にして同じ費用で効果を最大化したり、同じ効果で費用を最小化する施策の予算配分の最適化計算までを行うことを推奨します。
ここでは紹介しませんが、その手法は拙書にくわしいです。
指名検索数を指標として広告やプロモーションの効果を定量化して最適予算配分を試算することは、映画業界に限らず、全ての「調べて買われる」商品やサービスに有効な手段だと考えています。過去、そうした論考をnoteしていました。
ただし、コンビニやスーパーで売っているような、下調べなどせずに直観的または衝動的に購入される食品や日用品などは指名検索数ではなく、購買数を目的変数として分析したほうが良いと思います。
競合と自社の広告効果をいくつの指名検索を増やしたか?で比較する。
最近、ブレインパッド社のデータビジネスエバンジェリストの佐藤氏にお会いできる機会がありました。以下は4年前、電通グループ所属時に氏と対談させて頂いたマーケジン記事です。時系列データ解析を競合分析に適用する方法を「競合アトリビューション®︎」と名付け、商標を登録していました。
競合アトリビューション®︎は電通ダイレクトマーケティング社の登録商標です。
映画のように、日別で時系列の販売推計値が公開されている業界は稀です。しかし、指名検索数はGoogleのツールなどで調べられます。それを目的変数として、競合の出稿データや、外的要因(季節要因など)など、説明要因のデータを集められれば、それをもとに分析モデルを作り、得られたモデルから効果を推定し、自社の広告と競合他社の広告の効果を定量的に比較することが出来ます。過去行なった分析では、TVCMの指名検索リフトの効率が良いブランドは業績も伸びていた。など様々な発見がありました。
ツイートやWEB記事の収集は有料ツールを使うのが便利です。私はいくつかソーシャルリスニングツールを併用していますが、最近はもっぱらCEを使ってツイートの全数をゴリゴリと分析してます。「あなたの番です」の分析noteでは言語解析エンジンをガリガリ使って分析しました。
CEユーザーダントツでこのツールをマニアックに使ってると思います笑。1週間お試しアカウントもあるので皆さんも使ってみてはいかがでしょうか?
次回の3回目はツイートデータを活用したデータドリブン・マーケティングの極意(あくまで私の主観です)です。
これまで示した2回のように分析による示唆ではなく、その手があったか!?的な「打ち手」のヒントになるはずです。僕が個人アカウントで回してきたツイッター広告の運用データも出します。
質の良い仮説をみつけるために
ソーシャルリスニングについては、自社ブランドのフレーズで抽出したツイートやWEB書込みのデータを定点観測するだけだったり、暗中模索でテキストマイニングしているような場面を見かけます。質の良い仮説をみつけるためにはコツが必要です。
データの調理法を知る
例えば、これまで紹介した時系列解析というワザを知るか否かでも得られる示唆の幅に大きな差が出ます。時系列の変動という情報から売上や指名検索数が何によって説明されるかを構造的に理解したり、需要予測に活用出来ます。
ソーシャルリスニングは消費者の本音が、など安易に言われたりもしますが、そんなに簡単に有益なヒントはみつかりません。ツイッターもインスタもfacebookも、多少なり演出された発言も多いですし、まったく発言しない方も多いので。ツイッター、インスタグラム、facebook、tiktok、それぞれのSNSヘビーユーザーは全体を代表する標本とはならず、こういう人が良く投稿するといった偏りが生まれています。因果推論の分析で用いる傾向スコアを使って偏りを補正するワザもあります。
人間を見に行くチカラ
どの様な背景からその発言がされているのか?何を読み解くか?本音を読みとくには、視点を養う訓練しかありません。インサイトのプロが書いた本を読むとかです。
予約時期なのですが、著者の松本氏のnoteや日経ビジネスなどの寄稿を含めた様々な文献や同氏が所属するデコム社が展開する、調査データサービスを知っていて、それと連動する内容とあるので、オススメします。
以上
大変長くなりました。お読み頂き誠にありがとうございました。
【告知】※更新する可能性があります。
宣伝会議の8回の講座が12月20日から始まります。
高いスキルを持つデータサイエンティスト(希少人材で高スペック)やデータエンジニアリングは得意だが消費者理解や仮説力は苦手な方ではなく、自社の顧客やビジネスを最も理解していて仮説力があるマーケターが分析リテラシーを高めることが日本のマーケティングの現状において最も生産性を高めることだと思っています。(それだけ、分析が苦手なマーケターが多いです)そこで、Excelでできる演習を豊富に用意します。基礎的なことから、今回紹介した分析もやります。最終回には刀の森岡氏今西氏の書籍、確率思考の戦略論
で紹介されていた需要予測モデル(ガンマ・ポアソン・リーセンシーモデル)の演習もやる予定です。ご興味頂けそうなかたはぜひ、ご検討下さい。
また、仮にこの講座が埋まってしまった後も、企業向けにある程度カスタマイズしたマーケター向けの研修プランを提供しますので、マーケティングに関わる事業主、広告代理店、コンサルティング会社、PR会社、ソーシャルメディアマーケティング会社、ITツールベンダー、調査会社、様々な企業団体の皆様が対象です。ぜひお気軽にご連絡ください。
■ツイッター■
■研修お問合せ■※ページ下部に問い合わせフォーム有
専門的注釈事項
【model3の結果について】本来、(回帰分析による)多重共線性を避けるためには「変数のいずれかを外す」または「変数を合算」します。ここでは交絡の影響の除外が主な目的であるため、前者はあてはまりません。リッジ回帰などの手法を用いて通常の回帰分析のモデルと比較するなど、複数のモデルから有効なモデルを採択する必要があると認識しています。Tweetを見たであろう人数と検索をした人数。という共通単位で合算することもあります。また、付録ツールではDW比(ダービン・ワトソン比)を計算しており、系列相関がみられます。新たな変数(前回行ったネガティブツイートなど)の追加による改善や、コクラン・オーカット法を用いる必要があると認識しています。このnoteは統計の予備知識のない方を対象に書いたものであるため、かなり割愛した説明となっており、本来補足すべき内容が欠落しているかもしれません。拙書では回帰分析の際に留意すべき事項として、多重共線性、不均一分散、説明変数のはずれ値、オーバーフィッティング、欠落変数バイアスと内生性、時系列データに適用する場合の留意事項として系列相関と見せかけの回帰について解説させて頂いております。【指名検索数の介入効果について】model3で指名検索数はツイートの背後にある交絡と捉えています。ツイートの介入効果を確からしく推定するための分析になっていますが、指名検索数の介入効果を知るためにはツイートは指名検索数と販売数の間に位置する中間変数となるため、説明変数からツイートを外した別のモデルをかり判断する必要があります。
追加情報(2023年12月18日更新)
クッキー規制で目減りする効果計測の課題を解決法をnoteにしました。無料で使えるMETA社の高機能なMMM(マーケティング・ミックス・モデリング)ツール「Robyn」を徹底解説する2時間強のYouTube講義を公開しました。
【更新情報2024年5月26日】
「その決定に根拠はありますか?」
確率思考でビジネスの成果を確実化するエビデンス・ベースド・マーケティング
戦略を導く為の「エビデンスの作り方」をテーマに、これまで体系化してきたノウハウを紹介したマーケティング・インテリジェンスの書籍を出版致しました。5問の調査でTVCM(施策)→コンビニで商品を見た(要因)→売上がいくら増えたか?→年間16.67億円(効果)の様に経路ごとに構造的に効果を把握する国際特許(PCT)を出願した分析法など、確率モデルや因果推論をプロジェクトで実際に活用している方法を特典の動画講義も活用して実装レベルの知識まで提供しています。