
S&P500 AIで売買してみる

サブテーマ:AI/GRUモデルを使ってバックテスト&売買実行
1 初めに
過去の23回でLightningを使ってLSTMモデルでS&P500の株価を予測するコードを紹介しました。今回は個人的に好きなGRUモデルを使ってAI学習し、その学習モデルでのバックテスト、そのバックテスト条件に基づいた"Buy"or"Sell"のシグナルを出すことができるコードを紹介してみます。
今回は、学習率の自動サーチ機能の実装、説明変数に20日、50日、200日移動平均からの乖離率を盛り込んでみました。株に興味がある人だけでなく、PYTHONを勉強してみたい方、AIに興味がある方にもおすすめです。
なお、申し訳ないのですがコード全文(最下部)のみ有料設定とさせていただいています。それでも概要は把握できるような記事としてみましたので、ぜひお付き合いください。
今回のまとめ:
①S&P500”SPY”をGRUを使って予測するモデル
過去区間ではMAE(ブレ幅)11、MAPE(ブレ幅の割合) 2%
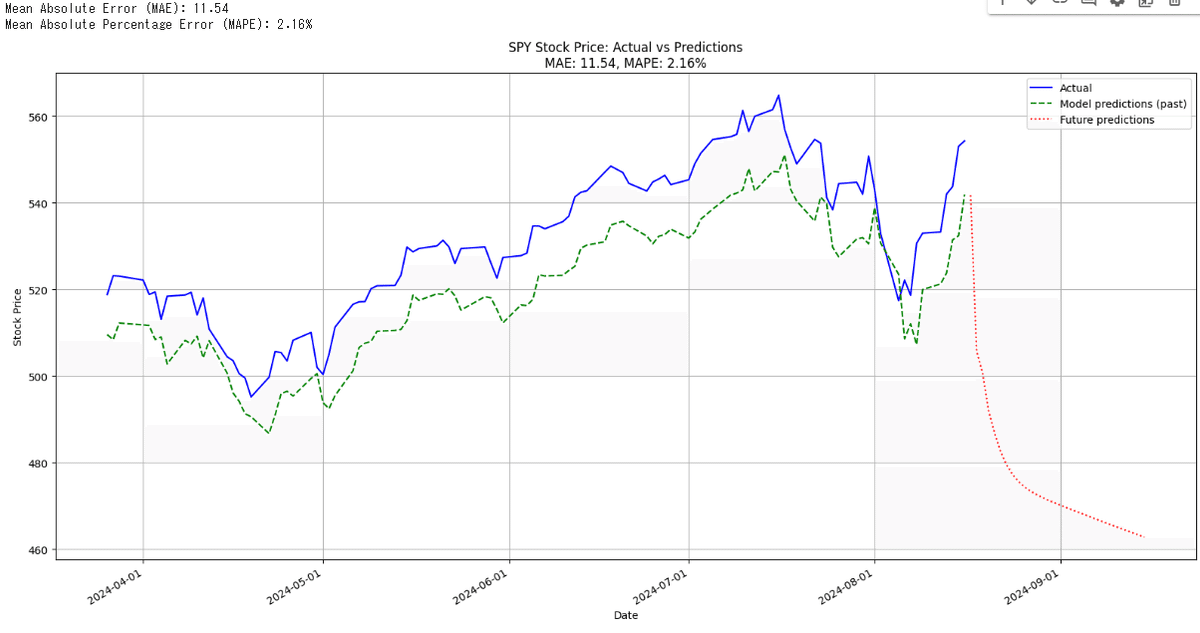
②バックテスト結果
初めは好調→途中マイナス転落→かろうじて+の実績



→Sellが多いので、Buyのみを信じてSellシグナルを厳格化して売買すると良いかも??
知人よりプログラム部分が難しくてよくわからないとご指摘をいただきました。そのためこのチャンネルでは、PYTHONを使った米国株投資に関わるさまざまな調査の結果OUTPUTにこだわった記事にします。投資に関わる身近な疑問にも答えていきますので、投資リテラシー向上にお役立ちを目指します!!
なお、全ての解析データは引き続き、PYTHONを活用してコード全文も掲載します。Googleコラボで動作確認したコードですので、まずは”コピペ”でチャレンジできます。これから勉強始めたい方にも、プログラミングで何ができるのかを知る良いチャンスとなればと思っていますので応援お願いします!!
2 豆知識
1)GRUモデルとは
GRU(Gated Recurrent Unit)モデルは、RNN(Recurrent Neural Network)の一種で、LSTM(Long Short-Term Memory)と同様に長期依存関係を学習するために設計されています。GRUは、入力ゲート、忘却ゲート、出力ゲートを持つLSTMとは異なり、更新ゲートとリセットゲートの2つのゲートのみを使用しています。
2)GRUモデルとLSTMモデルとの違い
GRUとLSTMはどちらも長期依存関係を学習するために用いられるRNNの拡張モデルですが、構造に違いがあります。LSTMは3つのゲート(入力、忘却、出力)を持つ複雑な構造で、細かい調整が可能です。一方、GRUは更新ゲートとリセットゲートの2つのみで、シンプルかつ計算効率に優れています。タスクによっては、LSTMがより効果的な場合もありますが、GRUはLSTMにくらべて計算コストが低く、軽量である点が強みです。
3 実践
1)実施内容
今回もPytorch-Lightningという比較的簡易にモデルが構築できるライブラリを用います。GoogleColabではPipコマンドでインストール・実行が可能です。解析するデータはYahooFinanceからS&P500インデックス連動ETF:SPYの価格を約20年分取得します。その結果を今回は、説明変数として20日、50日、200日の移動平均を計算し、その乖離率をそれぞれ説明変数として追加してみました。GRUモデルを用い、学習させ、30日後までのS&P500の値動きの予測結果をグラフで出力させます。
バックテストは実際にSell,Buyのシグナルを出して、売買します。それぞれの条件はコード内で設定できるように記入しています。最後にこの売買シミュレーションに沿った最新のSellorBuyのシグナル(最新の値に基づいた予測)を出すようにしています。

2)実践 GRUモデルの学習と予測
初めにPiPインストールし、必要なライブラリ等のインポートののち、株価を取得します。またそれぞれ20日、50日、200日の移動平均を計算し、その後それぞれの乖離率を計算し、カラムに入力させます。
!pip install yfinance japanize-matplotlib pytorch-lightning
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
import matplotlib.dates as mdates
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_absolute_error
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
import yfinance as yf
from datetime import date
import pytorch_lightning as pl
from pytorch_lightning.tuner.tuning import Tuner
# データの取得と前処理
end_date = date.today().strftime("%Y-%m-%d")
start_date = '2004-01-01'
df = yf.download('SPY', start=start_date, end=end_date)
# 移動平均の計算
df['MA20'] = df['Close'].rolling(window=20).mean()
df['MA50'] = df['Close'].rolling(window=50).mean()
df['MA200'] = df['Close'].rolling(window=200).mean()
# 乖離率の計算
df['Deviation_MA20'] = (df['Close'] - df['MA20']) / df['MA20']
df['Deviation_MA50'] = (df['Close'] - df['MA50']) / df['MA50']
df['Deviation_MA200'] = (df['Close'] - df['MA200']) / df['MA200']
# NaNを含む行を削除
df = df.dropna()
features = ['Close', 'Deviation_MA20', 'Deviation_MA50', 'Deviation_MA200']
その学習データを訓練データと評価データを8:2に分割します。またGRUモデルを下記のように設定しています。それぞれ関数を使っていますが、初めはコピペで実行してみて、必要に応じアレンジしてみてください。
training_data_len = math.ceil(len(df) * .8)
train_data = df[:training_data_len][features]
test_data = df[training_data_len:][features]
scalers = {}
scaled_train = np.zeros_like(train_data)
scaled_test = np.zeros_like(test_data)
for i, feature in enumerate(features):
scalers[feature] = MinMaxScaler(feature_range=(0,1))
scaled_train[:, i] = scalers[feature].fit_transform(train_data[feature].values.reshape(-1, 1)).flatten()
scaled_test[:, i] = scalers[feature].transform(test_data[feature].values.reshape(-1, 1)).flatten()
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i+seq_length])
y.append(data[i+1:i+seq_length+1, 0]) # Only predict the Close price
return np.array(X), np.array(y)
sequence_length = 50
X_train, y_train = create_sequences(scaled_train, sequence_length)
X_test, y_test = create_sequences(scaled_test, sequence_length)
class StockDataset(Dataset):
def __init__(self, X, y):
self.X = torch.tensor(X, dtype=torch.float32)
self.y = torch.tensor(y, dtype=torch.float32)
def __len__(self):
return len(self.X)
def __getitem__(self, idx):
return self.X[idx], self.y[idx]
class GRUModel(pl.LightningModule):
def __init__(self, input_size, hidden_size, num_layers, dropout=0.2, learning_rate=1e-5):
super().__init__()
self.save_hyperparameters()
self.gru = nn.GRU(input_size, hidden_size, num_layers, batch_first=True, dropout=dropout)
self.linear = nn.Linear(hidden_size, 1)
self.train_losses = []
self.val_losses = []
def forward(self, x):
out, _ = self.gru(x)
out = self.linear(out)
return out
def training_step(self, batch, batch_idx):
X, y = batch
y_hat = self(X)
loss = F.mse_loss(y_hat, y.unsqueeze(-1))
self.log('train_loss', loss)
return loss
def validation_step(self, batch, batch_idx):
X, y = batch
y_hat = self(X)
loss = F.mse_loss(y_hat, y.unsqueeze(-1))
self.log('val_loss', loss)
return loss
def on_train_epoch_end(self):
self.train_losses.append(self.trainer.callback_metrics['train_loss'].item())
def on_validation_epoch_end(self):
self.val_losses.append(self.trainer.callback_metrics['val_loss'].item())
def configure_optimizers(self):
return torch.optim.AdamW(self.parameters(), lr=self.hparams.learning_rate)次に学習率サーチを実行します。
Lightningでは比較的簡単に学習率サーチが実行可能です。サーチした最適な学習率を用いて本番のパラメーターに代入しています。もし学習率サーチが不要であったり、毎回一定で実行したい場合には、学習率サーチ部分を消して、コメントアウトした#optimal_lr =1e-4 #サーチ学習率を使用しない場合を有効にすることとで学習率が設定可能です。
# 学習率サーチ
trainer = pl.Trainer(max_epochs=10, accelerator='auto')
tuner = Tuner(trainer)
lr_finder = tuner.lr_find(model, train_loader, val_loader, min_lr=1e-6, max_lr=1e-1)
# 最適な学習率
optimal_lr = lr_finder.suggestion()
print(f"Optimal learning rate: {optimal_lr}")
# 学習率サーチ結果のプロット
fig = lr_finder.plot(suggest=True)
fig.show()
# モデルに最適な学習率を設定
#optimal_lr =1e-4 #サーチ学習率を使用しない場合
model.hparams.learning_rate = optimal_lr

次に、実際に改めて実際にモデルを”model=”を組み立て、trainer=&trainer.fitで訓練します。(学習結果および予測結果は前回と同じため省略)
model.hparams.learning_rate = optimal_lr
trainer = pl.Trainer(max_epochs=10, accelerator='auto')
trainer.fit(model, train_loader, val_loader)

予測の結果、8/18時点で株価はまた大きく下がる予測が出力されました。正直なところこの結果を信じるのではなく、より精度が高くなる方法を詰める余地が多分にあるためそちらを工夫してみるのもおすすめです。*モデルの層構造、ドロップアウト率、学習率は最適なのか、学習回数、説明変数の変更(今回は5日、20日、200日の乖離率ですが、他のインジケータを使用する等)を検討してみるとより精度が向上するかも??
3)実践2バックテストと”Sell””Buy”シグナル出し
つぎにバックテストを実行しその残額の推移をプロットしてみます。
初期額、所有額の何%を投資するか、何%増える予測でBuy、減る予測でSellかを設定できるようにしています。最適な組み合わせを探してみてください。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from sklearn.metrics import accuracy_score
class TradingStrategy:
def __init__(self, model, scaler, sequence_length, initial_balance=10000,
transaction_fee=0.001, buy_threshold=0.01, sell_threshold=0.01,
position_size=1.0, stop_loss=None, take_profit=None):
self.model = model
self.scaler = scaler
self.sequence_length = sequence_length
self.initial_balance = initial_balance
self.transaction_fee = transaction_fee
self.buy_threshold = buy_threshold
self.sell_threshold = sell_threshold
self.position_size = position_size
self.stop_loss = stop_loss
self.take_profit = take_profit
def simulate_trading(self, data):
self.model.eval()
balance = self.initial_balance
position = 0
entry_price = 0
trades = []
portfolio_values = [self.initial_balance]
for i in range(self.sequence_length, len(data)):
input_data = torch.tensor(data[i-self.sequence_length:i]).unsqueeze(0).float()
with torch.no_grad():
prediction = self.model(input_data)
predicted_price = self.scaler.inverse_transform(prediction[:, -1, 0].numpy().reshape(-1, 1))[0][0]
current_price = self.scaler.inverse_transform(data[i, 0].reshape(-1, 1))[0][0]
# Check for stop loss or take profit
if position > 0:
if (self.stop_loss and current_price <= entry_price * (1 - self.stop_loss)) or \
(self.take_profit and current_price >= entry_price * (1 + self.take_profit)):
revenue = position * current_price * (1 - self.transaction_fee)
balance += revenue
trades.append(('sell', i, current_price, position, revenue, 'SL/TP'))
position = 0
continue
if predicted_price > current_price * (1 + self.buy_threshold) and balance > 0:
shares_to_buy = (balance * self.position_size) / current_price
cost = shares_to_buy * current_price * (1 + self.transaction_fee)
balance -= cost
position += shares_to_buy
entry_price = current_price
trades.append(('buy', i, current_price, shares_to_buy, cost, 'signal'))
elif predicted_price < current_price * (1 - self.sell_threshold) and position > 0:
revenue = position * current_price * (1 - self.transaction_fee)
balance += revenue
trades.append(('sell', i, current_price, position, revenue, 'signal'))
position = 0
portfolio_value = balance + position * current_price
portfolio_values.append(portfolio_value)
return trades, portfolio_values
def generate_trading_signals(self, data):
self.model.eval()
signals = []
for i in range(self.sequence_length, len(data)):
input_data = torch.tensor(data[i-self.sequence_length:i]).unsqueeze(0).float()
with torch.no_grad():
prediction = self.model(input_data)
predicted_price = self.scaler.inverse_transform(prediction[:, -1, 0].numpy().reshape(-1, 1))[0][0]
current_price = self.scaler.inverse_transform(data[i, 0].reshape(-1, 1))[0][0]
if predicted_price > current_price * (1 + self.buy_threshold):
signals.append(1) # Buy signal
elif predicted_price < current_price * (1 - self.sell_threshold):
signals.append(-1) # Sell signal
else:
signals.append(0) # Hold signal
return signals
# 戦略の初期化
strategy = TradingStrategy(
model=model,
scaler=scalers['Close'],
sequence_length=sequence_length,
initial_balance=10000,
transaction_fee=0.001,
buy_threshold=0.01,
sell_threshold=0.01,
position_size=0.5, # 利用可能な資金の50%を使用
stop_loss=0.05, # 5%のストップロス
take_profit=0.1 # 10%の利益確定
)
# シミュレーション実行
trades, portfolio_values = strategy.simulate_trading(scaled_test)
バックテストの実行結果、途中まで確実に資産が増えていきましたが、2022年はマイナスでした。その後の上昇はとらえられてますが、正直、現状の条件ではBuy&Holdのほうが良いリターンではあります。
最後に実際のBuy,Sellシグナル出しです。
# シグナル生成
signals = strategy.generate_trading_signals(scaled_test)
# シグナルの可視化
plt.figure(figsize=(16, 8))
plt.plot(test_data.index[sequence_length:], test_data['Close'][sequence_length:], label='Actual Price')
plt.scatter(test_data.index[sequence_length:][np.array(signals) == 1],
test_data['Close'][sequence_length:][np.array(signals) == 1],
color='green', marker='^', label='Buy Signal')
plt.scatter(test_data.index[sequence_length:][np.array(signals) == -1],
test_data['Close'][sequence_length:][np.array(signals) == -1],
color='red', marker='v', label='Sell Signal')
plt.title('Trading Signals')
plt.xlabel('Date')
plt.ylabel('Stock Price')
plt.legend()
plt.grid(True)
plt.show()
# シグナルの統計
buy_signals = signals.count(1)
sell_signals = signals.count(-1)
hold_signals = signals.count(0)
print(f"Buy Signals: {buy_signals}")
print(f"Sell Signals: {sell_signals}")
print(f"Hold Signals: {hold_signals}")
# 最新の取引シグナル
latest_signal = signals[-1]
if latest_signal == 1:
print("Latest Signal: Buy")
elif latest_signal == -1:
print("Latest Signal: Sell")
else:
print("Latest Signal: Hold")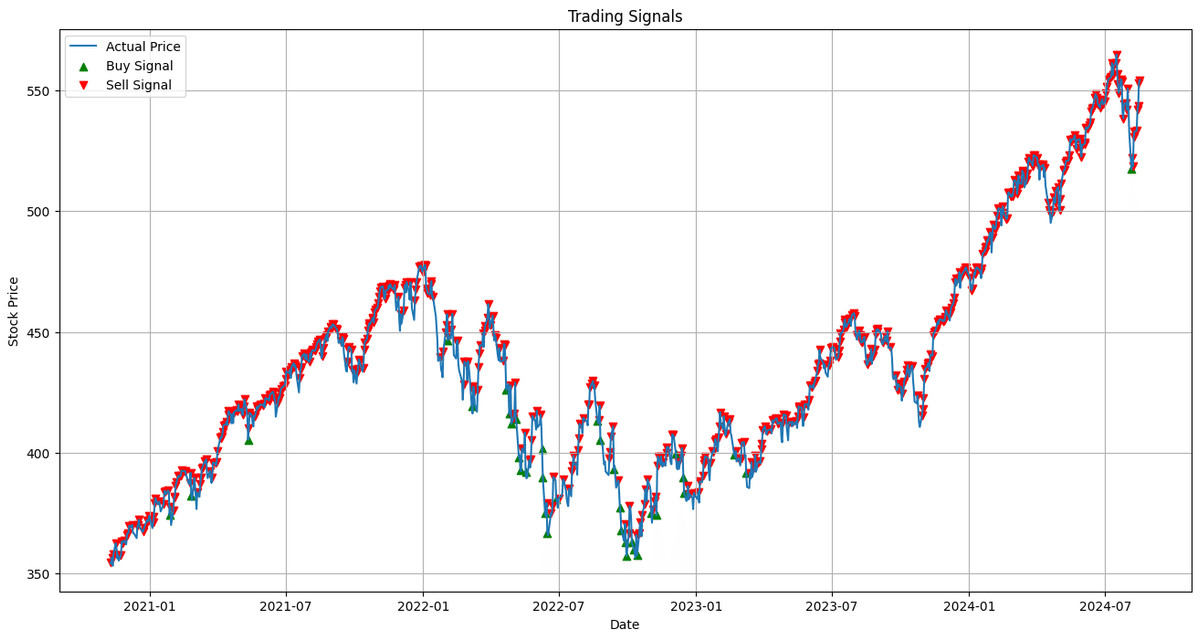

実際の売買シグナルが多くでる傾向で、Buyシグナル35回に対し、Sell611回とBuyが少ない結果でその分セルが上昇をとらえきれず売却したため利益が少なくなっていることがわかります。ただBuyシグナルは割と信じてよい箇所ででている気がします。Buyシグナルでかって、Sellシグナルを厳格化する、ロスカットを見直すことでもしかすると利益の出るモデルに仕上がるかもしれません。興味を持たれましたら是非コードを触ってみてください。
4 まとめ
今回ニューラルネットワークによる時系列予測をGRUモデルを使って、S &P500の今後の予測を行うコード(学習率サーチ&移動平均からの乖離率を説明変数として使用)と、その学習結果を使ってバックテストおよびシグナルを出すコードを紹介しました。
入門編としてのコードで調整代は多分にあると思いますので、興味を持たれたらぜひトライしてみてください。
今後も引き続き、投資リテラシー&プログラミングに関連した話題を提供していきますので応援よろしくお願いします。
*今回の結果は過去の結果を解析したものであり、今後の将来を保証するものではありません。実際の投資にあたってはご自身の判断でお願いいたします。
記事の感想、要望があれば下記X(旧Twitterまで)
*今後の記事に活用させていただきます!!
以下、過去記事、AI時系列予測等のご紹介
他サイトですがココならで、A I(LSTM)を使った株価予測の販売もやってます。こちらではFREDから、失業率や2年10年金利、銅価格等結果も取得しLSTMモデルで予測するコードとなってますので興味があれば見てみてください。またその他2件も米国株投資とは直接関係はありませんがプログラム入門におすすめです。
チャンネル紹介:Kota@Python&米国株投資チャンネル
過去の掲載記事:興味PYがあればぜひ読んでください。
グラフ化集計の基礎:S &P500と金や米国債を比較してます。
移動平均を使った時系列予測
コード全文:
ここから先は
¥ 3,000
この記事が気に入ったらサポートをしてみませんか?