
【Python】pandasデータクレンジング超基礎_その1

ある日突然「Pythonでデータクレンジングして!」と言われた若手社員が、知識ゼロ状態からなんとなくpandasを使えるようになるまで勉強したことをまとめました。正確性よりは、素人目線で分かりやすく書く方向に頑張りました。
※2020/9/23追記:
①クレンジング手順をより詳細に解説した記事その2を公開致しました
②データクレンジング処理の一部を追記しました
※専門家ではないので、詳しいことはお近くのプロに聞いてください
※表現に多少不正確な部分があるかもしれませんが、ご容赦いただければと思います…。
Pythonでデータクレンジングするとは
本稿で目指すのは、エクセルを綺麗な形のCSVに整えることです。綺麗な形とは、たとえばTableauなどのBIツールや各種システムに読み込ませることができる形のことを意味します。
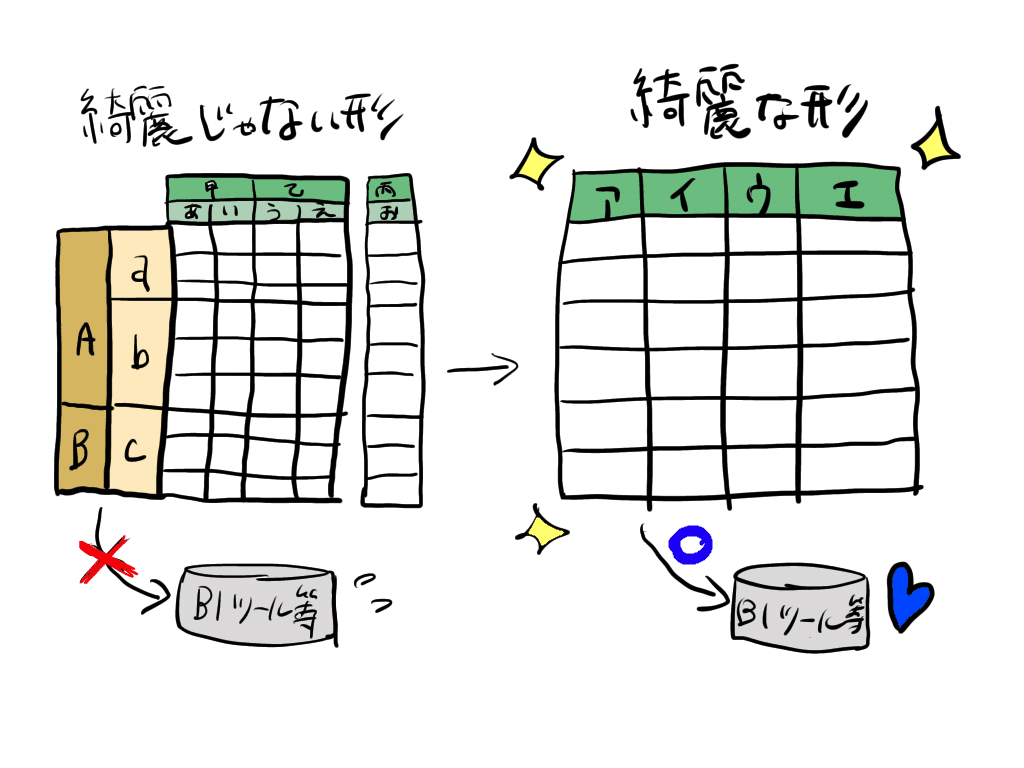
綺麗な形に整える作業は手作業でもできますが、Pythonで一つプログラムを書いておけば、同じ形式のエクセルが複数あったとき、クリック数回でクレンジングが済むので楽です。
まずはPythonを使えるようにする
では早速始めていきましょう。まずは、PCにAnacondaというものをインストールします(無料)。「Anaconda インストール」で検索して、出てきたページからインストールしてください。Anacondaには、今回やろうとしていることを実現するために必要なツールが全てパッケージされています。
インストールが完了したら、Anacondaに入っている「Spyder」を起動します。起動して開いた画面が、Pythonのプログラムを書いたり、プログラムの実行結果を確認したりする画面(エラーメッセージ等を見る画面)です。
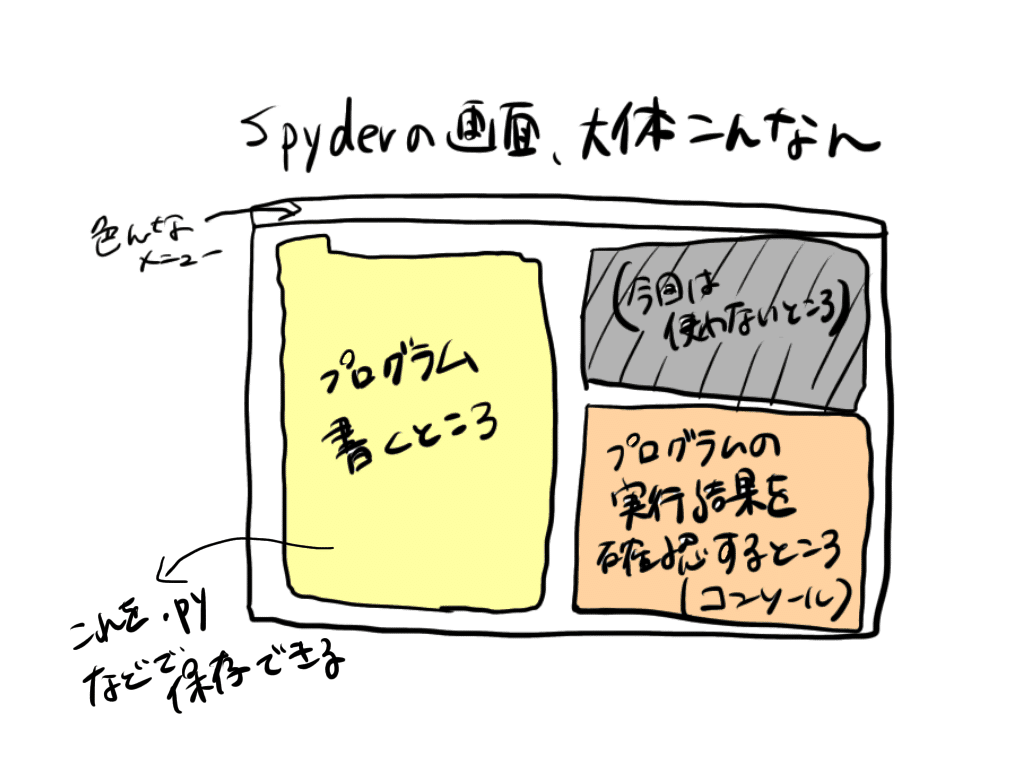
今からやることは、上図でいう左側の黄色い部分に、データクレンジングのためのプログラムを書くことです。例えば「A列を消せ」とか「列名をaaaからbbbに変えろ」とかいう内容を、Pythonの世界の言葉で書いていきます。エラーが出たらコンソール(上図でいう、オレンジ色のところ)で確認して、プログラムを修正します。
(ちなみに上図ではSpyderの画面が三つの小ウィンドウ(?)に分かれていますが、他の目的で使用する小ウィンドウを開いたり、それぞれを閉じたり、配置を変えたりすることもできます。今回は関係ないので考えなくて大丈夫です。)
これで、Pythonを使う環境が整いました。
Pandasを使えるようにする
今回のようにエクセルやCSVのデータをPythonで扱う場合は、pandasというライブラリを使用すると便利です。ライブラリとは…私はよく分かっていませんが、色んな呪文が書いてある魔術書みたいなものをイメージしています。
pandasを使うために必要なのは、プログラムの一行目に「import pandas as pd」と書くことだけ。意味は「今から私がpandasという種類のライブラリ(魔術書)を使えるようにします。ライブラリ(魔術書)の名前は、略してpdという名前にします」みたいなことです。pandasをpdと略すのは、これからプログラム内に何度もpandasと書くのが面倒なので、短くしているだけです。
これで、pandasが使えるようになりました。
Pandasの前提知識
さて、これからpandasという魔術書を使ってプログラムを書いていくわけですが、前提知識として、dataframe、series、listという三つの話を知っておいた方がよいと思います。
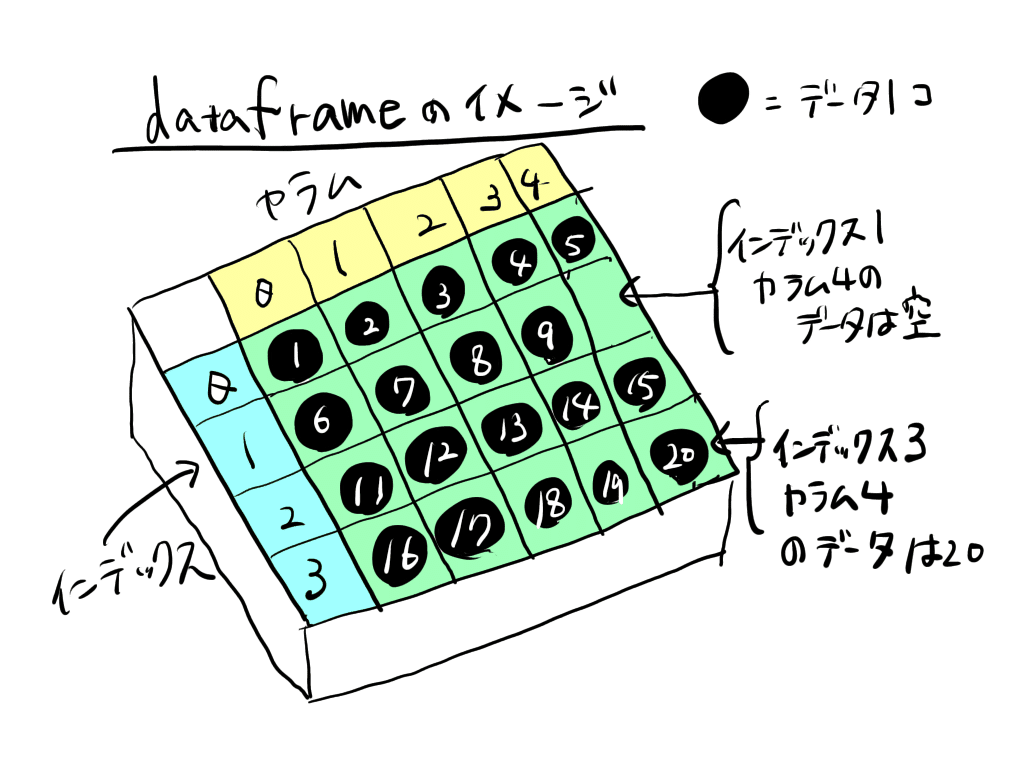
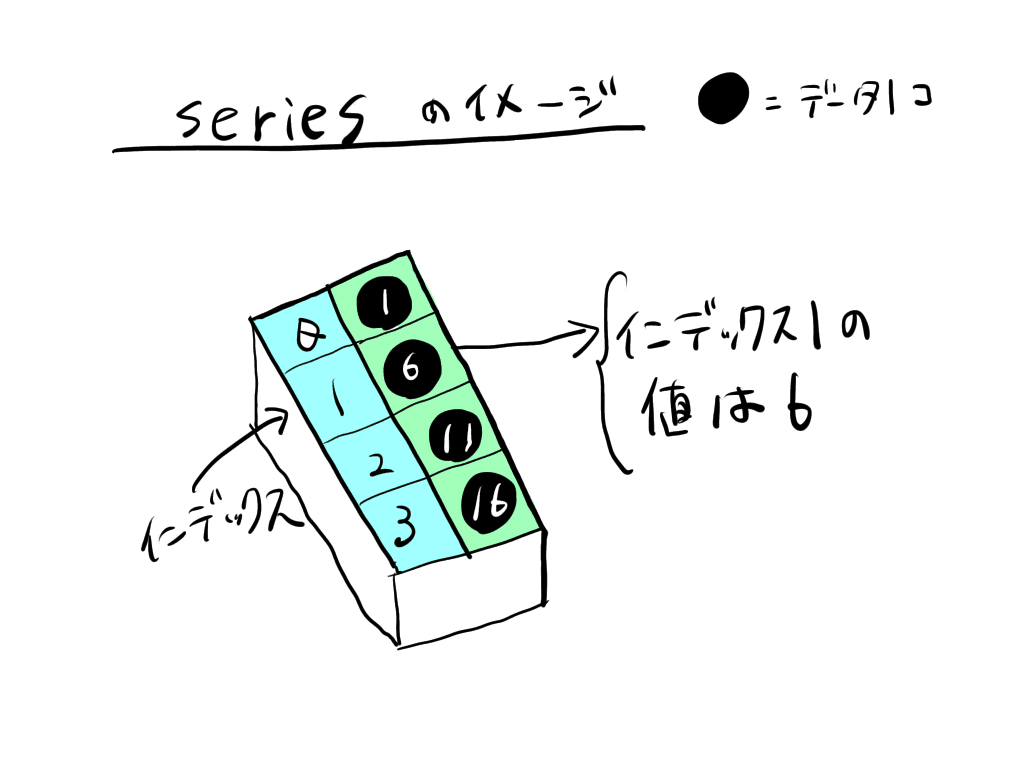
dataframe・series・listは、いずれもデータを格納しておく箱のようなものです。箱の形がそれぞれ違うので、別の名前が付いています。
dataframeは、縦軸と横軸で一意の値が定まるような箱です。
seriesは、ある一つの軸で一意の値が定まるような箱です。
listは、値の羅列です。
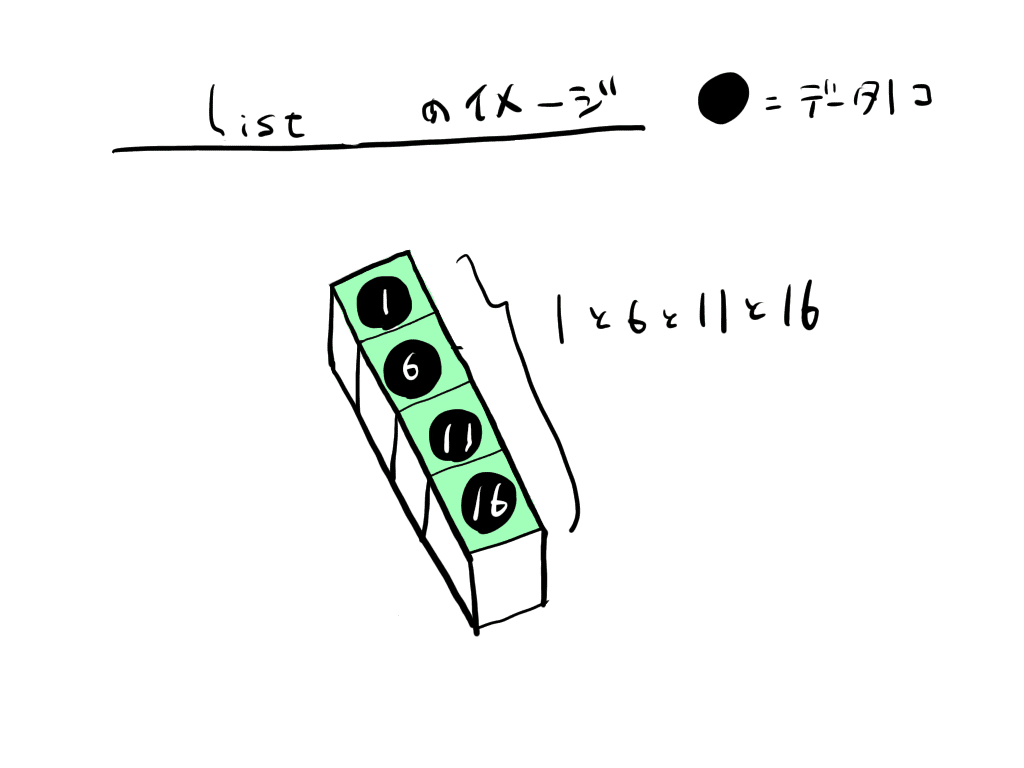
エクセルやCSVのデータをpandasで処理するときは、dataframeに入れるのが一般的です。
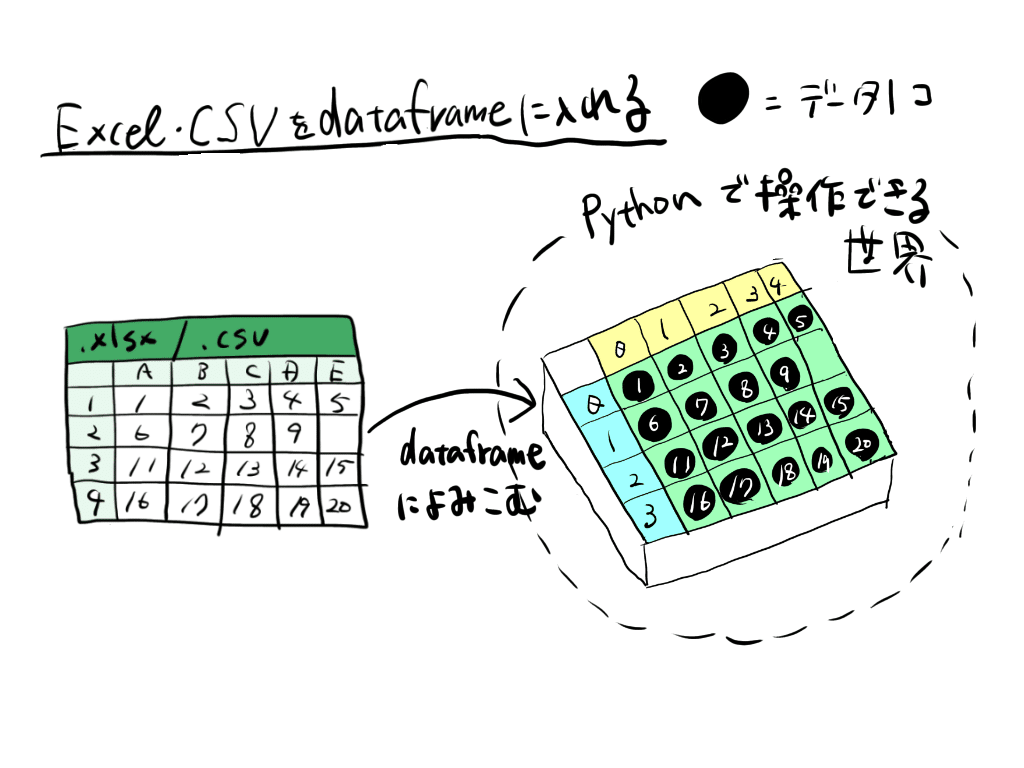
またdataframe・series・listには、任意の名前を付けることができます。「dataframe_1」とか「series_1」とかいう感じです。一般的にdataframeについては、略して「df」と名付けることが多いので、本稿もそれに倣います。
エクセルファイルの読み込み
いよいよプログラムを書いていきます。まずはPythonへエクセルファイルを読み込みましょう。以下のように記述すると、「⚫︎⚫︎⚫︎⚫︎ディレクトリにある☆☆☆.xlsxの▲▲シートを、dfという名前のdataframeに読み込んでください」という意味になります。
import os
os.chdir(“⚫︎⚫︎⚫︎⚫︎“)
df = pd.read_excel(“☆☆☆.xlsx”, sheet_name = “▲▲”)
1行目のimport osはosという魔術書を使うための記述で、2行目を実行するために必要な記述です。2行目では、このファイルを取得するディレクトリを指定しています。⚫︎⚫︎⚫︎⚫︎には、読み込みたいエクセルが保存されているフォルダのパスを記述してください。パスを記述する時は、バックスラッシュ(\)を二つ続けて書くようにしてください。一つのままで実行するとエラーになります。
dataframeのカラムとして使用したい行を任意で指定したい場合は、次のようにheaderの行数を指定してください。エクセルで言う1行目なら0、2行目なら1、というように、エクセルとdataframeで行番号がズレている点に注意です。
df = pd.read_excel(“☆☆☆.xlsx”, sheet_name = “▲▲”, header = 5)
ファイルが読み込まれているか確認したい場合は、コンソールにdataframeを表示することができます。必要な記述は以下の通りです。
print(df)
dataframeの上から10行だけ試しに表示してみる、ということもできます。記述は以下の通りです。
print(df.head(10))
これでエクセルファイルの読み込みとその確認ができました。
クレンジング処理の前に知っておくべきこと
さて、ファイルを読み込んだらクレンジングを行うのですが、その前に知っておいた方がよいことがあります。それはdataframe内の場所をどのように指定するかということです。
エクセルなら、操作したいセルをマウスで選択できますが、dataframeではそうもいきません。VBAのように、操作対象のセル(または列など)をプログラムの中に記述する必要があります。この記述ができないと、クレンジング処理を行いたい対象のセルや列や行がそもそも指定できないので、処理を正しく実行することができません。
dataframeの場所指定で特に大事なのは、loc, iloc, at, iatの4つだと思います。
loc, ilocは行や列の指定に使用します。locは行または列の名前で指定する方法、ilocは番号で指定する方法です。locでもilocでも、範囲での指定が可能です。
df.loc[‘aaa’:’ddd’, ‘AAA’] →インデックスがaaaからdddまでの行のAAAカラム
df.loc[:’ddd’, [‘AAA’, ‘CCC’]] →インデックスが先頭からdddまでの行の、AAAカラムとCCCカラム
df.iloc[:, 2] →全行のカラム2のみ
df.iloc[2:4, 6:10] →2〜4行目の、6〜10列目
at, iatは単独のセルの指定に使用します。atは行または列の名前で指定する方法、iatは番号で指定する方法です。
df.at[‘aaa’, ‘AAA’] →インデックス名がaaa、カラム名がAAAのセル
df.iat[0,1] →0行目、1列目のセル
loc, ilocも、行と列に一つずつの値を入れれば、at, iatのように一つのセルを選択することもできます。
データクレンジング処理
いよいよクレンジングを行います。ここでは、今回私がよく使用したクレンジング処理をまとめておきます。
カラム削除...drop
例:dfのカラム1, 3, 7を削除したものを、df2と定義する
df2 = df.drop(df.columns[[1, 3, 7]], axis = ‘columns’)
※カラム番号を挟むカッコが二重になる点に注意
行削除...drop
例:dfの行2, 4, 8を削除したものを、df3と定義する
df3 = df.drop([2, 4, 8])
dataframeのlistへの変換
例:dfの0行目・10-15列目の値をリストに入れる
new_list = df.iloc[0, 10:15]
※活用先としては、例えばカラム名編集で編集後の値としてリストを指定できる
カラム名編集その1…rename
例:「あいう」というカラム名を「アイウ」に、「かきく」というカラム名を「カキク」に書き換える
df.rename(columns = {‘あいう’:’アイウ’, ‘かきく‘:’カキク’})
カラム名編集その2(ある行の値をカラム名に丸ごと置き換える)
例:20行目を既存のカラム名と丸ごと置き換え、新たにdf4と定義する
new_col_name = df.iloc[20].tolist() →dfの20行目をリストnew_col_nameに入れる
df.columns = new_col_name →dfのカラム名に上で作成したリストを使用する
df4 = df.drop(20) →カラム名として使用した20行目が不要であれば消す
セルの値の書き換え
例:1行目・2列目のセルに、3行目・4列目のセルの値を入れる
df.iloc[1, 2] = df.iloc[3, 4]
カラム追加とその中身の指定…insert
例:dfの15列目として、「名前」という名称のカラムを追加し、値にlist_nameという名前のリストを使用する
list_name = [“田中”, “山田”, “鈴木”]
df.insert(15, “名前”, list_name)
カラムとインデックスを逆にする(転置)…T
例:dfのカラムとインデックスを逆にしたdataframeをdf5と定義する
df5 = df.T
各行をN行ずつ複製する…append, sort_index
例:dfの各行を3行ずつにしたdataframeをdf6と定義する
df6 = df.append(df).append(df)
df6 = df6.sort_index()
※2行目の処理sort_indexを行わない場合、表が縦にくっついた形になる
dataframeどうしを縦にくっつける…concat
例:同じカラム名を持つdf7とdf8を縦にくっつけ、インデックス番号を一つの表として振り直したものをdf9と定義する
df9 = pd.concat([df7, df8], ignore_index = True)
※ignore_indexを記述しないか、Falseにすると、元のdataframeのインデックスが引き継がれる
dataframeどうしを左右(横)にくっつける…concat, axis=1
例)dataframeのdf_leftとdf_rightを左右に結合
df=pd.concat([df_left, df_right], axis=1)
for文を使用してリストを作成する…for i in range(N)
例)値「1, 2, 3」を5回繰り返したリストを作成する
lis_1=[] -->ブランクのリストを作成
lis_2=[1, 2, 3] -->値1, 2, 3のリストを作成
for i in range(5):
lis_1=lis_1+lis_2
print(lis_1) -->実行結果は[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
シリーズ同士を演算し新たなシリーズを作成する
例)ser_1の各値からser_2の各値をマイナスした値で新たなシリーズを作るser_1=pd.Series([1,2,3])
ser_2=pd.Series([1,1,1])
ser_3=ser_1-ser_2
※ser_3は、[0, 1, 2]というシリーズになる
セルから文字列を抽出する…str
例)dataframeであるdfの、カラムCol1の1行目にある文字列「YAMADA_TARO」から「YAMADA」のみを取得する
df_2=df['Col_1'].str[:6] -->Col_1の左から6文字目までを含むdf_2を定義
print(df_2.iloc[1]) -->df_2の1行目を取得。実行結果は「YAMADA」
※右からN文字、と指定したければ.str[:-N]と記述
リストの任意の位置の値を削除する…pop
例)リストlis_1の最初の値を削除する
print(lis_1) -->実行結果は["a", "b", "c", "d"]
lis_1.pop(0)
print(lis_1) -->実行結果は["b", "c", "d"]
CSV吐き出し
クレンジングが終了したら、結果をCSVに吐き出します。最初にエクセルファイルを読み込んだ時と同様、まずディレクトリを指定してからCSV吐き出しの記述をします(import osは済んでいるものとします)。
os.chdir(“○○○○“)
df.to_csv(“☆☆☆.csv”, encoding=‘utf_8_sig’, index=False)
上記は、○○○○ディクトリに☆☆☆.csvファイルを吐き出す記述です。吐き出すデータに日本語が混じっている場合は、encoding=‘utf_8_sig’を付けておくと文字化けを防げます。インデックスを含めたくない場合はindex=Falseも記述します。
おわりに
pandasでデータクレンジングするにあたり、自分が最初に欲しかった基礎知識を備忘兼ねまとめてみました。少しでもお役に立てば幸いです。
最近髪をばっさり切りました。