
【無料eBook付】AIプロジェクト失敗を避ける10のポイント

昨今はDX推進の活動の一環として、AI導入についても再度積極的に検討しよう、という企業様が増えているように思います。
今回が初めての導入という企業様もいらっしゃいますが、以前にも導入を検討した/導入したが、思うような成果が出ず、本格的な検討はそれ以来だ、という企業様も多いです。
本記事は、以下のようなお悩みをお持ちの、AI導入を検討されている企業のご担当者様を読者に想定しています。
- 過去にAI導入を一度失敗してしまった経験があり、なぜ失敗したのかを明らかにしてから次の取り組みに進みたい
- はじめてのAI導入なので不安。何に気をつければ良いのか知りたい
- AI導入に必要なリソース・コストを把握した上で、必要十分な人員や予算の確保を上長に諮りたい
こんにちは。Nishika CTOの松田です。
日々のお客様とのお話で、「AIプロジェクトはどういう点に気をつけておいたら良いのか」という趣旨のご質問をいただくことが多くございます。
いつも弊社よりご回答している内容をリストアップしますと、以下の10ポイントとなります。
- AI導入が目的化していないか常に確認する
- 精度100%をAIだけで実現しようとしない
- AIの精度を上げたいのか、AIの判断の根拠を知りたいのか、どちらが重要か決める
- AIの性能を開発前に見当をつけたいなら、AIに与えられるデータを見る
- AI導入に期待する効果を徹底的にすり合わせる
- 兎にも角にも現場を巻き込む
- 「データはある」の中身について、開発者と依頼者の認識齟齬を防ぐ
- コロナ禍のような有事の際は、サンクコストに囚われずにモデル再構築に踏み切る
- 本番環境の壁はPoCよりも高いことを知る
- AIならではの運用体制を用意する
今回、eBookの形で上記ポイントをまとめ、公開いたします!

以下、その一部を抜粋してご紹介いたします。
AIの精度を上げたいのか、AIの判断の根拠を知りたいのか、どちらかが重要か決める
「AIがなぜその判断をしたのか知りたい」というのは当然のニーズです。
しかし、多くの場合、AIの解釈性とAIの精度は、トレードオフの関係にあることに注意してください。
AIの精度を高めようと思えば思うほど、複雑なモデルが選ばれる傾向にあります。
AIを代表する技術、ディープラーニングがその典型です。
しかし、複雑なモデルは人間による解釈が難しいというデメリットがあります(だから、性能が高くなるのですが)。
精度向上を目的に開発を進めた後、解釈性を求めてしまうと、モデルは一から作り直しとなってしまいます。
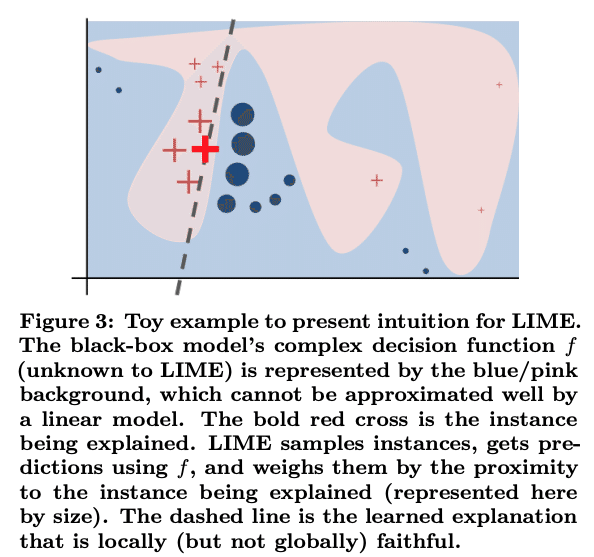
近年、AIの解釈性を担保する方法も活発に研究されています(LIME, SHAPなどが代表的です)。
LIME

SHAP


ですが、これらの手法は元のモデルを完全に説明するものでなく、悪く言えば「人間が解釈できる別の劣化モデルに何とか当てはめている」と言うことができます。
結論としては、AIの精度よりも解釈性を重視したいのであれば、検討初期からディープラーニングの導入を諦め、線形モデルや決定木のような「分かりやすい」モデルの導入を優先すべきです。逆に、できる限り高い精度のAIを導入したいのであれば、解釈性はある程度犠牲となることを覚悟しましょう。
兎にも角にも現場を巻き込む
AI導入による効果が出ると確信が得られた場合でも、実際に効果が実感されるまでにはハードルがあります。
AIを実際に利用する現場に受け入れてもらえるかどうか、がハードルの1つです。
例えば、AIに与える教師データを作成するプロセスが、現場の負荷の大きい作業を前提としている場合です。
これでは、AI導入によって実感できる効果よりも、業務負荷を強く感じてしまい、いずれAIの学習が行われなくなってしまいます。
AIの開発だけに集中するのではなく、現場の負荷を考慮し、データの作成プロセスを型化し、可能な限り自動化することを併せて検討するべきです。
期待効果や業務負荷への影響が少ないとしても、現場を巻き込んでAI開発を行なっていくことは重要です。
AI開発に現場を巻き込んでいくことで、当事者意識が生まれたり、「AIが育っていく様が嬉しい」という感情を持っていただけたりします。
一方で、現場の協力が得られていない状況では、たとえ性能の良いAIでも、ごく稀に予測が外れた一事をとりあげて反発される、といったトラブルが起こってしまったりします。
現場にとってのAI導入の効果・負荷はもちろんのこと、積極的な巻き込みが総じてトラブルを避けることに繋がります。
「データはある」の中身について、開発者と依頼者の認識齟齬を防ぐ
「データはありますか」という問いはAIの開発で必ずなされますが、この短い問いは非常に奥が深いです。
「あると言っているのはどういうデータか」の点で、AIを開発する側と開発を依頼する側でしばしば認識の齟齬が出ます。
- 実は紙データだった
- あると言っていたデータはエクセルで、各自のPCに各自の管理方法で入っていた
- データの入力ルールが人によって違っていた
- データが上書きされていて過去の蓄積が分からなかった
もちろん、開発者と依頼者の間に認識の齟齬が全くない、ということは現実的にあり得ませんし、その齟齬を埋めることも開発者の仕事の1つです。
しかし、齟齬の頻度が高かったり、予測に重要なデータの質が悪かったりすると、期待していたAIの開発は覚束なくなります。
開発に着手する前に、データの質量に関する解像度を上げておくべきです。
おわりに
以上、抜粋して3つのポイントをご紹介しました。
全体では10ポイントございますので、AIプロジェクトの推進はこんなにも気をつけるべきことがあるのか、という印象を受けられるかもしれません。
しかし、正しい導入を行えばAIは必ず効果をもたらしてくれるものです。
以下からフルバージョンのeBookを入手いただき、先人と同じ轍を踏まないAI導入を実現していただければと思います。
この記事が気に入ったらサポートをしてみませんか?