
Jリーグプレイヤーの出場時間予測 コンペ振り返り

こんにちは。Nishika CTOの松田です。
先日終了した「Jリーグプレイヤーの出場時間予測」コンペについて、コンペ開催に至る背景や上位ソリューションのご紹介をしながら、振り返りたいと思います。
本コンペは、述べ413名の方にご参加いただきました。合計投稿回数の1559件と合わせて、Nishika上にて開催したコンペの中で最大となりました。
改めて感謝申し上げます。
本コンペの概要
本コンペは、Nishikaが様々な情報源から収集・加工したサッカーJリーグの選手データをもとに、翌年度のJ1リーグの各選手の出場時間を予測する、というものでした。
サッカーは、非常に能力の高い選手であってもチーム戦術やチームメイトとの相性によって活躍できる・できないの振れ幅が大きく、またJ1リーグで言えば毎年数十から百数十人の選手が移籍すること、数あるスポーツの中でも年齢による衰えの影響が大きいと言われること、怪我のリスクも大きいことなどから、各選手が新たなシーズンでどの程度活躍できるかは、非常に読みにくいところがあります。
しかし、当然ながら各チームの監督をはじめとする首脳陣は、どの選手がどの程度活躍してくれそうかを読んだ上で編成について熟慮し、移籍市場での振る舞いなどを決める必要があります。
もちろん、私含め観戦者・応援者側も、どの選手がどのくらい活躍できるか?は興味の的だと思います。
本コンペでは、そのようなサッカーに関係する全ての方々にとっての関心事であろう、新シーズンの各選手の活躍度合いを、出場時間という側面からどの程度予測できるかトライしてみよう、という目的で開催いたしました。
Nishikaにて作成・公開したデータは、選手のデータ、試合のデータ、チームのデータ、さらに監督のデータも含みます。
選手のデータが最もリッチで、所属チーム、ポジション、年齢、身長、体重、年俸、国籍といったプロフィールの他、過去数シーズンに渡っての各試合の出場時間、出場タイミング、得点、警告、退場といったデータも作成・公開いたしました。
そして、2019シーズンの出場時間を、2018以前の数シーズンのデータをもとに予測する、というタスクとしました。
予測精度の評価指標は、RMSEに設定しました。
目的変数の傾向
コンペの中身に入る前に、ターゲットである2019シーズンの出場時間の値がどのような分布のものであったか、軽く見ていきます。
まず、各選手の合計出場時間の分布をヒストグラムで示します。2018シーズンの分布も合わせて示します。
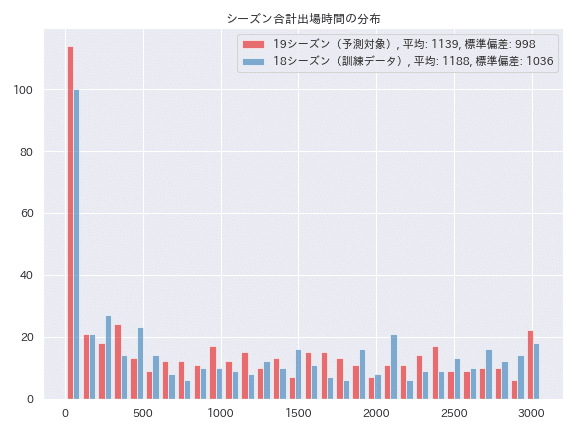
このように、正規分布のような形状では全くなく、フル出場(3060分)する選手もいれば全く出場しない選手もいる、非常に裾野の広い分布となっています。
チーム別に見てみるとどうでしょう。標準偏差で、出場時間の裾野の広さを評価します。2019シーズンですと以下のようになります。

分布の裾野が広いのはどのチームも同様ですが、チームによってかなり事情が異なることもわかります。
出場時間の標準偏差が最も小さい、つまり選手ごとの出場時間の差が比較的小さい川崎フロンターレと、標準偏差が最も大きい、つまり選手度との出場時間の差が比較的大きいFC東京の分布を比べてみます。
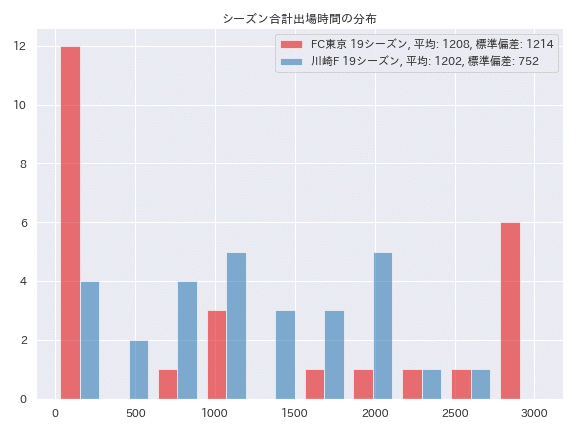
FC東京は試合に出ている選手、出ていない選手がはっきり分かれており、川崎フロンターレはどの選手もある程度出場し休んでもいることがわかります。
各チームの出場時間の上位5選手を出してみます。
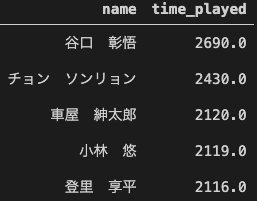
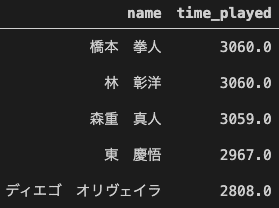
川崎フロンターレは、全試合フル出場している選手はおらず、一方FC東京は3059分の森重選手も含めると3人がフル出場しています。
ところで、サッカーに限らずチームスポーツでは、「勝っているチームはいじらない」という原則?があるやに聞いたことがあります。
逆に、負けが混んでいるチームは、なんとか苦境を打開しようと選手の入れ替えを試す(監督やコーチを替えてしまうことも多いですが・・・)ことが多い印象もあります。
実際のところどうなんでしょうか。2019シーズンの順位とともに、出場時間の標準偏差をプロットしてみます。横軸が順位、縦軸が標準偏差ですが、横軸は左の方が上位であることに注意してください。
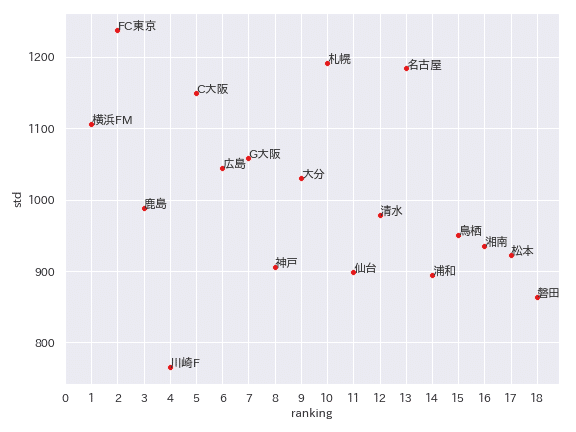
回帰分析まではしていませんが、なんとなく上位のチームの方が標準偏差が大きい、つまり出場する選手がある程度固定されている傾向にあるようです。
ただ、1点特殊事情を指摘しておくと、アジアチャンピオンズリーグ(ACL)というアジアのクラブNo1を決める大会があり、前年のJ1リーグなどで好成績を収めたチームが出場権を得ることになっています。
このACLに出場するチームは非常に試合日程がタイトになるため、疲労の蓄積を避けるため、勝敗に関わらず選手を入れ替えながらやりくりする傾向にあります。
2019シーズンの場合、鹿島、広島、浦和、川崎FがACLに出場しています。
上位チームであっても鹿島や川崎F、広島の出場時間の標準偏差が小さいのは、ACLの影響で選手を入れ替えながら戦っていたのではないか、と言えます。
・・・ちょっと脱線してしまいました。このように色々興味深い分析ができる当データですが、コンペの経過・結果の話に戻りたいと思います。
上位ソリューションの概要
1st place solution (yumizz)
上位ソリューションでは、テーブルデータにおける機械学習モデル構築では常道の、集約特徴量などの特徴量生成はどれも行われておりました。
かつ、いずれも最終的には決定木系のモデル構築手法(XGBoost, LightGBM, CatBoost)およびそれらのアンサンブルを採用されており、その中で細かな差を分けた要因は、前処理の手法だったと思われます。
1st solutionの前処理では、以下のような工夫をされていました。
※以下Discussionより転記
・J1、J2によって試合数が違うので、年間の成績等は年間の試合数で割って、1試合あたりの~に変換
・前年度J1やJ2に登録されていなかったため欠損値になっているデータは、前後の年の成績・出場時間で補完
・海外等の他リーグでの成績・出場時間が反映されているものがチラホラ
→リーグのレベルによって、出場時間は大きく変化すると予想できるので、これらデータは使わない。※前後の年にJリーグに所属していれば、それらで補完
・その他欠損値がある選手は、成績が近い選手で補完
他にも、ある年だけデータのない場合は、前後の年の成績で補完する(データがないのは海外移籍しているケースが多く、日本に在籍していれば前後の年程度の成績が期待される)など、的確なドメイン知識に基づいた前処理が細かくスコアを押し上げていたのではないかと推察します。
次に特徴量についてですが、1st solutionのLightGBMにて構築したモデルの特徴量の重要性をプロットすると、以下のようになりました。
※以下弊社にて出力した図

重要度Top3は以下となりました。
team_prev1time_played_rate: 前シーズンの合計出場時間の、チーム別に合計した時間中の割合
prev1_time_played_team_std: 前シーズンの合計出場時間の、チーム別集団におけるZ得点
prev1_time_played: 前シーズンの合計出場時間
上記の他に、サッカーのドメイン知識を踏まえ、仮説通りに予測に有効性を発揮した特徴量として、team、team×positionでgroupbyしたときの各特徴量(salaryなど)のランク、偏差がありました。これはチーム内の同ポジションとの競争の激しさを表す指標で、納得性があります。
また、意外に有効性を示した特徴量に背番号もあったとのことで、前年の出場時間や年俸に現れない、チームとしての選手への「期待」が背番号に反映され、結果出場時間に反映されたのではないかと推察されます。
コンペ終盤は、特徴量を追加してもCVは上がれどLBは上がらず、CVとLBの乖離に悩まされたとのことです。
最終サブミットは保守的なものと挑戦的なものを選ぶ戦略をとり、CVもPublicLBもそこそこ良いものと、CVは悪いがPublicLBが最も良いものの2つを選んだところ、後者がPrivateLBでは上位になった、とのことでした。
2nd place solution (Oregin)
2nd solutionでも、最も力を入れたのは前処理だったとのことでした。
※以下Discussionより転記
前処理については、最初はいつもの通り、欠測補完とターゲットエンコーディング程度の学習データで実施していたのですが、それでは不十分だったので、以下のような前処理を行って特徴量を追加しました。
【eventデータ】
出場記録
選手毎にフル出場, 途中出場, 途中退場,途中出場途中退場, 出場停止,ベンチ入りの回数を集計し、試合数で割って正規化しました。
【trainデータ】
・選手名、登録ボジション、国籍
sklearnの LabelEncoderで、数値化。
国籍については、Nullの場合は日本として補完。
・チーム名、過去シーズン在籍チーム
辞書を作成し、数値化。
また、過去のシーズン在籍チームについては、’・'の有無で、チーム移籍有無を表す特徴量として追加。
・生年月日
年を抽出して誕生年の特徴量を追加。
・ユース出身
0または1で数値化。
・過去シーズン出場試合数、得点数、出場時間
欠測を-1で補完。
・過去シーズン所属リーグ
欠測を0で補完。
・推定年俸
欠測を中央値で補完。
2nd solutionのLightGBMにて構築したモデルの特徴量の重要性をプロットすると、以下のようになりました。
※以下弊社にて出力した図

重要度Top3は以下となりました。
rat_full_play: フル出場した試合数の全試合数に対する割合
rat_full_play_second: シーズン後半の、フル出場した試合数の全試合数に対する割合
prev1_time_played: 前シーズンの合計出場時間
最終的には、Public LBが最良のサブミットを選び、Private LBでも最も良い結果だったとのことです。
個人的に参考になると感じた試みとして、バリデーションについて、初めに年度を気にせずランダムにkfoldを適用してみたところ、精度が向上しない / CV・LBの相関が崩れる、という事態に直面し、最終的には2018年度のデータを検証データとするホールドアウト法を採用したということでした。
基本的なバリデーション戦略は、手元のtrain, validデータの関係をコンペのtrain, testデータの関係と合わせる、というのは初学者としては参考とすべき点と思います。
また、アンサンブルの重みやハイパーパラメータの値については、各々過去のコンペで有効だった値を採用したとのことで、コンペの実戦経験を積み重ねることの重要性を感じさせるお話しでした。
3rd place solution (Lain)
3rd solutionでは、publicLBが振るわなかったため、publicLBに過適合してprivateLBで順位落とすことを何よりも避ける、privateLB重視戦略をとったとのことでした。
従って特徴量生成・選択には細かな注意が払われ、CVとLBができるだけ同じになるように生成を行ったとのことです。例えば、Target EncodingとCount Encodingは、CVしか上昇せず採用しなかったとのことでした。
※以下Discussionより転記
Target EncodingとCount Encodingは行わない
prev[1-3]_time_playedの変動のパターンをカテゴリ化(up->down etc…)
prev[1-3]_time_playedをbinning化して組み合わせる(1->3->2 etc…)
Categoryごとにaggregateした特徴量
数値同士の演算
また、Adversarial Validationという、train, testデータにlabelをつけてtrainかtestかを判別する分類器を構築し、これが精度良く判別できるほど特徴量に乖離があることを利用して特徴量を取捨選択する手法を適用されていました。(Adversarial Validationについては、u++さんのブログ記事が詳しいので、参照ください)
結果、見事にPublic 14th -> Private 3rdにshake upされ、戦略は成功したと言えます。
3rd solutionのLightGBMにて構築したモデルの特徴量の重要性をプロットすると、以下のようになりました。

重要度Top3は以下となりました。
prev1_time_played_mul_salary: 前シーズンの合計出場時間×年俸
group_position_meandiff_rat_full_play: フル出場した試合数の全試合数に対する割合の、ポジション別集団の平均との差分
group_position_zscore_rat_full_play: フル出場した試合数の全試合数に対する割合の、ポジション別集団におけるZ得点
出場時間や出場試合数とともに、年俸が予測に有効であるというのは、年俸の高い選手はそもそもパフォーマンスが高い選手である・年俸の高い選手はパフォーマンスに依らず試合に出さないわけにはいかない、という両方の側面が考えられますが、いずれにしても納得のいく結果です。
最終サブミットは、他の上位ソリューションと同様、CVが良いもの、CVとLBが近しいものの2種類を選択されたとのことです。
おわりに
今回のタスク設計については、学習データから予測地点までが1年離れていること、またデータ量が少ないことから、難しいタスクだった、CVとLBの乖離に悩んだという声が多くございました。
Jリーグの選手の出場時間を予測するという、サッカーに関係する方であれば多くが興味を抱くであろうテーマを選定できた一方、適当な難易度・十分なデータの量の確保というところでは悩ましいものがありました。
一方で、今後の展望ですが、コンペに参加いただいた皆様により、前処理やモデル構築の手法における予測精度の改善は相当程度やり込まれたと考えます。
従って、ここからより高い精度の予測を実現するには、説明変数となるデータをよりリッチにすることが特に重要と考えられます。
今回ご提供が難しく断念しましたが、有用だと考えているデータは、各選手の得意なプレイに関するデータです。
例えばドリブルの得意な選手が生きるのは、スペースを広く活用する戦術をとるチームであるし、裏に抜けるプレイを得意とする選手が生きるのは、DFの裏へ鋭いパスを出せる選手がいてこそ、といったことがあります。
他にも、より高い精度の予測を実現するためにこういうデータが有用なんじゃないかというご意見、データをお持ちの方、Nishikaまでご連絡いただけますと、本コンペのPhase2という形で活用させていただくかもしれませんので、よろしくお願いいたします!
今後も、データや課題設定の面白いコンペの開催に努めていきたいと思います。
改めまして、本コンペにご参加いただいた皆様、誠にありがとうございました!
【新コンペのご案内】
現在Nishikaでは、判例の個人情報の自動マスキングというコンペを開催しています。
個人情報のマスキングは、判例文に限らず様々な分野でニーズがあり、社会的意義の高いテーマだと考えています。
自然言語処理の中でも固有表現抽出にあたるタスクとなり、あまり過去に開催の例がないものになっていると思いますので、奮ってご参加いただければと思います。
BERTを使ったチュートリアルもご用意しておりますので、自然言語処理・固有表現抽出に初めて触れるという方も、是非ご参加ください。

この記事が気に入ったらサポートをしてみませんか?