
ディープラーニングを用いた顔写真の写り判定機能の紹介

こんにちは、プロダクト開発部のyuyaです。
noteの記事投稿は今年の4月ぶりになるので、久しぶりです。
前回の記事では同一画像検知アルゴリズムの紹介をしておりますので、まだ未読の方は、ぜひご覧ください。
今回は、恋活・婚活マッチングサービスで必須となる、顔写真の写り判定機能の紹介をさせていただきます。
背景
恋活・婚活マッチングサービスのプロフィール写真は、非常に重要な要素であり、顔写真の写りによってマッチ率は大きく変わってきます。
しかし、実際のプロフィール写真を見てみると、不鮮明で写りが良くなかったり、顔が物で隠れて見づらかったりする写真を使用しているユーザーが少なくありません。
そこで今回は、プロフィール写真の顔の見やすさをAIで判定する機能を実装しました。
この機能によって、ユーザーに写真写り改善の促しが見込めます。
機能の紹介
顔写真から以下2つの指標を予測するモデルを作りました。
「顔の見やすさ」(以下、タスクAとする)
モザイク、ピンボケ、手ブレ、低画質、影、逆光などの要素があった場合、顔が見づらいと判定します。その際に再撮影を促すことができます。「顔が物で隠れていないか」(以下、タスクBとする)
手、マスク、スマホ、スタンプ、サングラスなどで顔が隠れていないかどうかを判定し、顔が物で隠れてしまっている際に再撮影を促します。

意図的に顔を隠しているユーザーに対しても、お知らせを出すことで、顔がはっきりしないプロフィール写真は異性ユーザーにとって好感度が低いと知ってもらうキッカケを作ることができます。
実装の解説
AI判定機能の具体的な解説をします。
今回は、顔写真画像を入力として、上記の予測をするディープラーニングのモデルを作ります。
スマホ上での処理フローは、下図のようになっています。
入力画像から顔のみを抽出しモデルに入力することで、顔の見やすさの判定結果を得ます。

スマホと学習済みモデル間のやり取り方法
スマホアプリでAI機能を導入する際、スマホデバイスと学習済みモデルのやり取りは、以下の2パターンが考えられます。
サーバーにモデルをアップロードし、スマホからサーバーへ通信する方法
メリット:スマホのストレージを圧迫しない。サイズが大きいモデルも扱える。
デメリット:サーバー費用がかかる。ネットワークの通信時間がかかる。
デバイスにモデルを組み込む方法
メリット:サーバー費用がかからない。
デメリット:スマホのストレージを圧迫する。
本機能は多くのエンドユーザーが使うため、なるべくAIによる予測速度を早くしたいと考えました。
さらにカメラ起動中、連続的にフレームが流れる環境においてもリアルタイムでAI判定を行えるようにするため、「2.デバイスに組み込む方法」を採用しました。

フレームワーク
学習済みモデルを扱うフレームワークとして、TensorFlow Liteを選びました。
TensorFlow Liteは、スマホなどのエッジデバイスに組み込むことに特化したフレームワークです。
iOS, Android, Flutterで実行可能なので、1つのモデルを作ってしまえば複数の環境で使用することができます。
また、モデルを軽量化するための量子化などの最適化手法も用意されています。
モデルのアーキテクチャ
ディープラーニングのアーキテクチャに、MobileNet V2を選びました。
こちらは、Googleが開発した畳み込みニューラルネットワーク(CNN)を用いた画像認識用のアーキテクチャです。
名前の通り、モバイル端末でのリアルタイムの推論を目的としており、モデルサイズが軽量なのが特徴です。
ストレージを圧迫しないかつ、推論速度を上げたいという今回の要件を満たせると考え、こちらを選びました。
最終層の追加
今回のモデルは、入力画像に対してタスクAとタスクBの2つの値を出力します。
推論速度やストレージ圧迫の観点から、1つのモデルで複数のタスクを解くように設計しました。
具体的には、モデルの最終層として2次元の全結合層を追加します。
また、2つの出力はそれぞれ独立した指標であり、1つのカテゴリに仕分けるような分類問題とは異なります。
そこで、独立した0~1の範囲の値を出力するために、活性化関数にはsigmoid関数を設定しました。
分類問題と回帰問題のどちらとして扱うかについて
各出力の指標を、0か1の二値をとる分類問題と、0~1の範囲内の連続的な数値をとる回帰問題のどちらとして扱うべきかを考えます。
タスクAである「顔の見やすさ」の指標では、「やや見づらいかも...…」というように、「見やすい」と「見づらい」のどちらにも分けられない画像が多くありました。

また、タスクB「顔が物で隠れていないか」においても、画像ごとに物による顔の隠れ具合が異なりました。
例えば、顔下全体にマスクをしている場合は明らかに顔が隠れていますが、顎にマスクをしている場合はそこまで顔が隠れていません。
「見やすい」と「明らかに見づらい」のような両極端の二値分類問題として扱うことも考えたのですが、どちらにも属さないデータの評価ができないことは、モデルの解釈性の低下に繋がってしまいます。
そのため、タスクA・タスクBともにすべてのデータに対して、正確に予測を行うために回帰問題として扱うのが適切だと判断しました。
損失関数の定義
モデルの損失関数は、回帰問題で一般的に用いられる平均二乗誤差(Mean Squared Error)にしました。
平均二乗誤差とは、正解値と予測値の誤差を二乗して算出するため、誤差が大きいほど過大に評価するという特徴があります。
今回の写真判定機能の導入を想定した場合に、大きく間違った結果を表示してしまうとエンドユーザーに違和感を与えてしまいます。
そのようなケースをなるべく防ぎたいので、大きな誤差を出さないように学習できる平均二乗誤差は最適な指標だと考えました。
平均二乗誤差は外れ値の影響を受けやすい面もありますが、今回の学習データはすべて自分で正解ラベルを設定するため、過剰な外れ値はデータに含まれないと考え、外れ値による悪影響は少ないと判断しました。
学習を成功させるためのアプローチ
ファインチューニング
ImageNetという大規模画像データセットで、学習済みのMobileNetを用いファインチューニングを行いました。
ファインチューニングにより、少ないデータでも精度を高められ、学習時間の短縮が見込めます。
データ拡張
人力での正解値の設定には限度があるため、データ拡張により学習データの多様性向上を試みました。
顔写真に対して、「水平反転」と「回転」をランダムに行い、学習データを増やします。
「回転」は、顔写真として一般的にあり得る角度(-45〜45度)で行いました。
以下図のように、1枚の画像に対して3枚のデータを生成し、学習データを4倍に増やしました。

実験データ
正解値の設定
プロフィール写真から顔が映る箇所を切り抜いた画像に対して、タスクAとBの正解値を設定します。
正解値の基準を分かりやすくするため、正解値は以下のような5段階で設定しました。

データ数
実験には、以下の合計1494枚のデータを用いました。
学習枚数:1184枚(データ拡張により4736枚)
検証枚数:310枚
各指標の正解値ごとのデータ数は、以下のグラフの通りになります。

実験環境
モデルの学習時には、SageMaker Training Jobを使いました。
こちらを使うと、学習時のみ高コストな学習用インスタンス(GPU)を起動し、学習終了時に自動で停止されるため、無駄なコストが発生しないメリットがあります。
また、学習スクリプトと学習データが疎結合になっているため、各々を変更する作業が容易であり柔軟に実験を調整できます。
学習結果
検証データでもっとも精度が良かった学習のepochごとのLoss値をグラフにしました。

はじめの2epochは最上位レイヤーにあたる全結合層のみのパラメータを更新するようにし、それ以降のepochはアーキテクチャ全体の上位約1/3のレイヤーのパラメータを更新するように学習しています。
短いepoch数で学習が収束しており、これはファインチューニングやデータ増強によるものと考えられます。
後半のepochで学習データと検証データの精度に差が出ています。
これはデータ数が多くなかったことや、正解値を主観的に設定したことにより、学習データでは表現できないデータが検証データにあったと考えられます。
モデルの評価と考察
検証データのMAE(Mean Absolute Error/平均絶対値誤差)とR2(決定係数)を算出しました。
MAEとは、各データの正解値と予測値の差の絶対値を平均した値になります。
R2は0~1の範囲の値をとり、値が大きいほどモデルがより良い予測を行うことを示しています。
一般的にR2の値がおよそ0.7以上の場合は良いモデルと評価されます。
検証データ
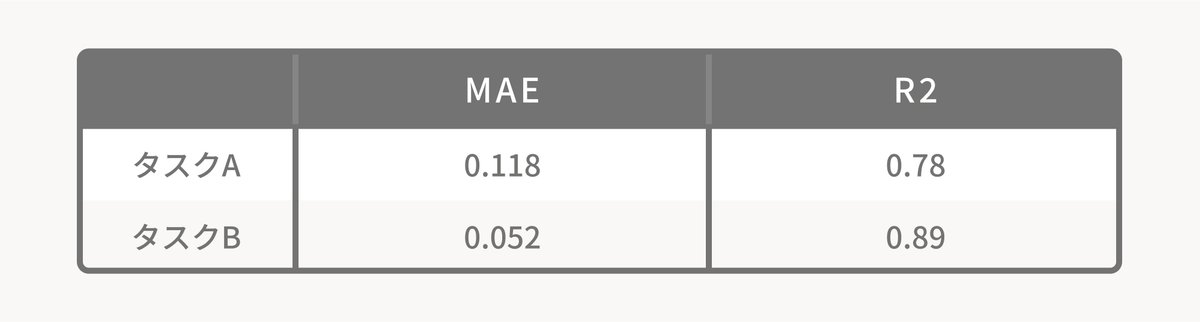
検証データにおいてどちらのタスクでもR2が0.7を超えているため、良い精度で予測を行うことができるモデルといえます。
タスクAに比べタスクBの精度が高くなっているのは、タスクBの正解値の多くが、"0"か"1"に属しており、5つの基準に分散されているタスクAと比べて問題の難易度が低かったためと考えられます。
問題の難易度が高いと思われるタスクAに注目し、各正解値におけるMAEをグラフにしました。
こちらは検証データのみを用いた結果になります。

正解値0におけるMAEは約0.05と低い値となっており、写りが良い写真において高い精度で予測ができているといえます。
正解値0の精度が高くなった理由としては、他の基準値と比べてデータ数が多かったことや、「見やすい」データは学習によって判別しやすいものだったことが考えられます。
対して、正解値0以外のMAEは、正解値0と比較して大きな値になりました。
こちらの原因として、「見づらい」の指標は定量化しづらく、5段階に振り分けたデータのなかには、それらの間の値に属するデータも含まれているためと考えられます。
例えば、正解値を0.5と設定したデータのなかには、厳密には0.4や0.6であろうデータがあるはずです。
もっともMAEが高くなった正解値0.5は中心の値であり、「見やすい」か「見づらい」かもっとも曖昧なデータのため、予測難易度が高く誤差が生じやすかったのではないかと考えられます。
それでもMAEがもっとも高い値で0.25となり、誤差としては隣合う正解値に留まる範囲内のため、ユーザーに表示する値としては違和感が少ないものであると考えられます。
また、タスクAの正解値0における予測値の分布をグラフにしてみました。

予測値0.3を超えるデータがほぼないことから、写りが良い写真を悪いと誤判定することが限りなく少ないことがわかります。
「写りが良い写真」と「写りが悪い写真」をそれぞれ正しく判定することは、基本的にトレードオフの関係にあります。
今回の機能では、「写りが悪い写真」を見つけること以上に、「写りが良い写真」を「悪い」と誤判定しないことが、ユーザーの誤解を防ぐためにもっとも重視すべきことです。
本モデルは「写りが良い写真」の判定精度がもっとも高く、UXの観点から良いAIモデルができたと考えられます。
ビジネス視点を持ったモデル評価について
ビジネスでAIモデルを扱う際には、「モデルの評価と考察」の冒頭の表で算出したようなデータ全体に対する評価指標の値を見るだけではなく、後半で行ったようなモデルの予測の傾向を分析し、それが導入するプロジェクトに適応しているかどうかを考えることが重要になります。
また、MAEのような非エンジニアにもわかりやすい指標を用いることで、ビジネスチームにモデルの性質を伝えやすくなります。
ビジネスサイドと意思疎通しやすい評価を行うことも、AIプロジェクトでは重要だと考えています。
今後の方針
今後の方針として、本機能を導入後にエンドユーザーの写り改善効果を検証する予定です。
性別や年齢ごとの最適な対応の分析や、新たな課題を見つけていきたいです。
また、各マッチングサービスのプロジェクトごとの要件に合わせ、類似機能のモデルを開発する予定です。
まとめ
スマホに組み込んで扱える、高精度なディープラーニングモデルの開発に成功しました。
サーバーとの通信が不要のためランニングコストがかからず、カメラ使用中にリアルタイムでも動作できます。
正解値の指標が5つあるので、警告を出す閾値の判断を管理者側ができるため、使い勝手も良いと思われます。
本機能によってユーザーのプロフィール写真の質が上がると、マッチング率の向上が予想され、それによるユーザー数増加が見込めます。
今後もAIを使った機能を適宜開発し、より良いサービスを作っていきたいです。
Newbeesでは一緒に働く仲間を募集しています
Newbeesはフルリモート&フレックス勤務を導入し、場所にとらわれない自由な仕事のやり方が可能です。詳細は以下をご覧ください。