
同一画像検知アルゴリズムの紹介 Part2

こんにちは、プロダクト開発部のyuyaです。
今回は、前回の同一画像検知アルゴリズムの紹介 Part1の続きになります。
まだ未読の方は、ぜひご覧ください。
前回はphashの工程の2まで解説しましたので、工程3から解説していきます。
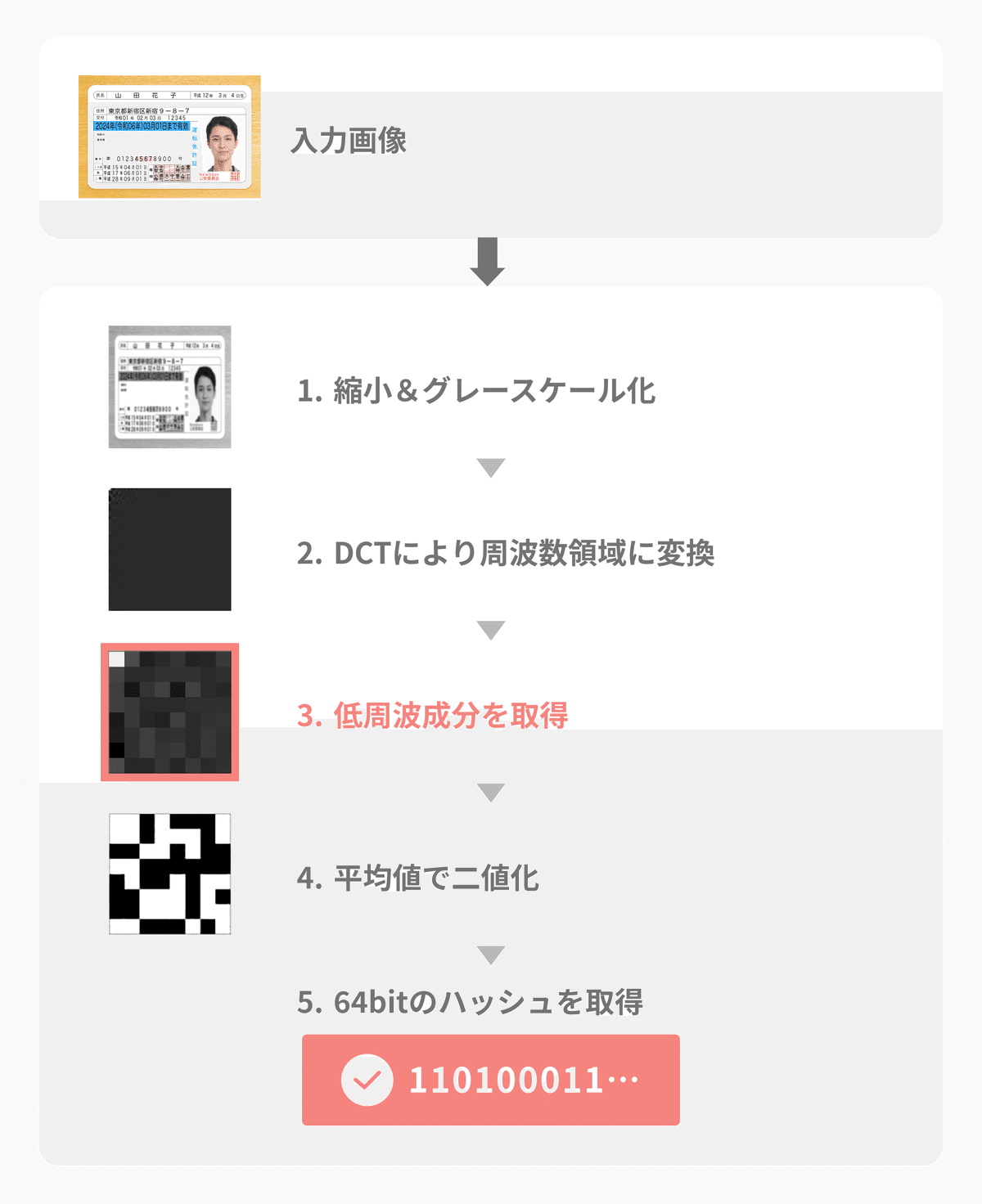
3. 低周波成分を取得
3つ目の工程では周波数領域から低周波成分を取得します。
周波数領域は基底画像に対応しているため、右下にいくほど高周波の正弦波の情報になります。
そのため、左上に低周波成分があります。
phashの工程では、周波数領域の左上にある8x8[pixel]を取得します。

正弦波の情報を64x64[pixel]から8x8[pixel]のみ取得するため、全体の正弦波の1/64しか抽出しないことになります。
これだけで画像の特徴が抽出できるのか不安になりますが、周波数領域で画素に高い値が入っているのは、ほとんど左上です。
目を凝らしてみると、明るい画素が左上に集まっていることが少し分かるかと思います。
つまり、画像を構成する正弦波のほとんどが低周波成分になります。
知覚しやすい情報は低周波成分に集まる
Part1で、信号を正弦波の重ね合わせで作るアニメーションをお見せました。
このアニメーションを見ると分かる通り、序盤にあたる低周波の合成段階で完成形となる信号のおおまかな形が作られています。
このように、人が知覚しやすい情報は低周波成分に集まります。

高周波成分を削るメリット
また、不正ユーザー画像対策という観点でも、低周波成分のみ取得するメリットがあります。
不正ユーザー画像の加工パターンの1つである、顔と文字の加工は、画像全体から見たら微小な変化になります。画像内の局所的な違いは細かい波の変化になるため、周波数領域では高周波成分にこの変化が集まります。
低周波成分のみを取得するphashでは、局所的な加工を無視できるため、このような加工画像に対し類似度を高くすることができます。
以下の顔加工画像は、オリジナル写真の目を大きくした画像です。
ハミング距離が0となるため、同一判定が可能です。

4. 平均値で二値化とハッシュ値の取得
最後の2つの工程を解説します。

はじめに取得した低周波成分8x8[pixel]の平均値を算出します。
この時に、波がない左上の白い画素は平均値が大きく変わってしまうため、計算から省きます。
計算した平均値を仮にAとし、平均値Aよりも明るいか暗いかで画素値を0か1に二値化します。
平均値Aよりも暗かったら0で、明るかったら1となります。
最後に、二値化した画像を左上から順に読み込み、64桁のハッシュ値を取得します。

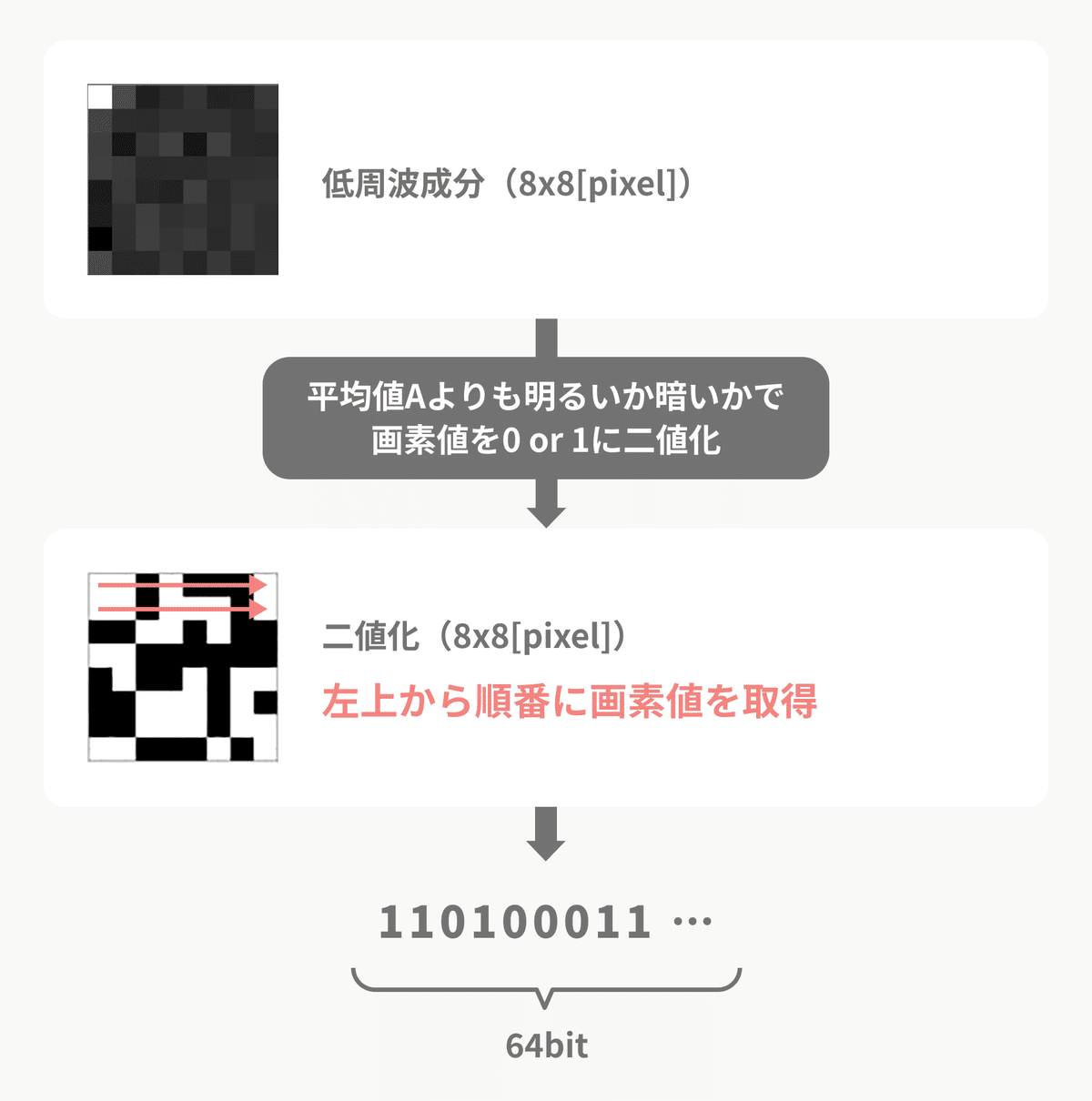
以上のphashの工程によって得られたハッシュ値は、低周波成分にあたる64個の各正弦波が平均より多いか少ないかの情報が入っています。
前述した通り、知覚しやすい特徴は低周波成分に集まるため、このハッシュ値が画像を大まかに表す特徴量となります。
5. phashの検証
不正ユーザーの加工パターンを模したサンプルを使って、phashの検証をしました。
本システムではハミング距離4以下を同一画像として運営側に表示しているため、距離4以下の場合は同一判定成功とします。
サイズ変更

オリジナル画像と、画像サイズを0.75倍、0.5倍した画像のハミング距離を求めました。
いずれも距離0となったため、サイズ変更に対し検出性能が高いと言えます。
色調変更

多少の明るさ変更の場合は距離4となり同一判定可能です。
大きく色調が変わると、距離は離れてしまいます。
トリミング

トリミング加工も同様に、多少の加工なら距離4となり同一判定可能です。
大きくトリミングされると、距離は離れます。
文字と顔の加工

名前/生年月日/住所の番地/顔写真(目の大きさ)の4点を変更した画像に対して、距離2となりました。
「3.低周波成分を取得」の章で顔写真(目の大きさ)のみ変更した場合も距離0であったことから、文字と顔の加工に対して検出性能は高いと考えられます。
異なる画像

異なる画像同士の場合、多くは距離4を超えるため、同一判定されません。
6. 誤検出について
本システムでは、数万件の不正ユーザー画像の中から同一画像を検索しています。
年確画像は「書類を撮る」という共通した条件のため、同じ形式の書類を同じ写りで撮った画像において、ハミング距離が近くなり誤検出されるケースが稀にあります。
その対策として、不正ユーザーの傾向的に、加工されにくい文字が同じである場合のみ同一判定することで、誤検出を減らしております。
まとめ
今回は、phashを用いた同一画像検知アルゴリズムを紹介しました。
人間がパッと見て同じとわかる画像に対して、高い検知性能を示しました。
課題としては、過度な加工を施された不正ユーザー画像による検知失敗や、写りが似ている場合の誤検出が挙げられます。
さらなる精度向上のためには、DeepLearningによって最適化されたモデルが必要であると考えております。
ここまで読んでいただき、ありがとうございました!
Newbeesでは一緒に働く仲間を募集しています
フルリモート勤務を導入し、場所にとらわれない自由な仕事のやり方が可能です。詳細は以下をご覧ください。