
複数の開発チームが協調する時

複数のチームによって一つのプロダクトを開発することは、単一のチームによって開発することと全く異なる難しさがある。
LeSSはこれに対する解答の一つだ。
スクラムはミニマムなフレームワークである。ゆえに「で、現実に目の前で起きている問題にどう対応するの?」に対する直接的な答えにはなりにくいことがある。
今日はもう少し状況を限定し、スタートアップにおいて複数のチームが一つのプロダクトを開発するための効果的なコミュニケーションについて考えてみよう。
複数の開発チーム
次のような状況を考えてみる。
会社
社員は100人程度であり、一つのプロダクトを扱っている
会社の方針(company bet)を四半期ごとに決める
開発チーム
PdM、デザイナー、エンジニアがいる
3〜6程度のチーム数、一つのチームあたりの人数は3〜9人程度
四半期ごとにチームを組み直す可能性がある
QA
開発チームとは別に品質保証を担当するチームが存在する
CS
開発チームとは別にカスタマーサクセスを担当するチームが存在する
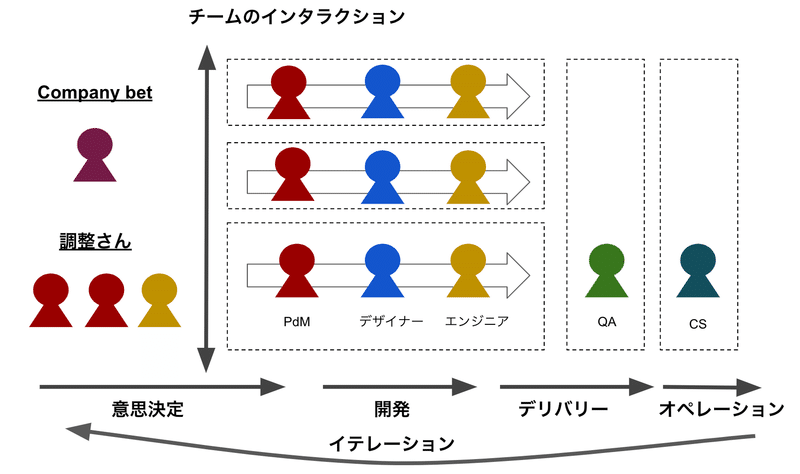
プロダクトはWebアプリかスマホアプリを想像する。
意思決定と開発チーム
意思決定の透明性
エンジニアが最も開発したくないものは「なんのために作るのかわからないもの」だろう。この問いは少人数あるいは単一チームで開発している場合にはそれほど問題にならないが、複数チームで開発しているときは重い問題として扱う必要が出てくる。
開発チームの意思決定は前段を含めると次のようになる。
company betの決定
バックログ(企画と仕様)の調整
バックログの詳細の決定
1つ目のcompany betについて、どう決めるかはともかく何らかの形でその会社が今成し遂げたいことというのは定めるだろうし、それは全社員に伝えるだろう。全メンバーが一つの方向性に対して全力を出せるときにその組織のパフォーマンスは最大になる。
3つ目の「具体的に何を作るか」はPdMが手を動かすと思うが、基本的には各チームに委ねられる。チームが独立的で強い裁量を持つ時に、そのチームのパフォーマンスは最大になる。
ここまでは良い。難しいのはその中間で、これが最も混乱を生みやすい。すなわち、2つ目のバックログ間の依存性あるいはチーム間の依存性をどうハンドリングするかだ。開発チームが「完全に」独立していることはまずない。単一のプロダクト内で複数のものを同時に開発する場合、企画・機能・実装・リソースが何らかの形で食い合う。これをどこで、誰が、どう決めるかとそれに透明性があるかどうかが組織全体の透明性に強く影響する。
なにを開発するかを予測することは難しいが、どうやって決まるかを予測可能にする工夫は十分できる。例えば、
四半期ごとにチームを組み替える=3ヶ月のタイムボックスではチームを固定して、その期間中はチームは可能な限り独立的に意思決定させる
チーム間のレビューあるいはレトロスペクティブを定期的に行う
チーム間の依存性を可視化する
チームの編成プロセスを公開する
これらはかなり意識的に行う必要がある。単一チームで開発する感覚で複数チームを扱うとコミュニケーションが大混乱に陥る。
開発フローとコミュニケーション密度
開発あるある
作業工程は企画(PdM)→デザイン(デザイナー)→実装(エンジニア)
仕様の作成が遅れる(結果、遅れる)
デザインの作成が遅れる(結果、遅れる)
デザインができた段階でPdMからリテイクをもらう(結果、遅れる)
デザインができた段階で他チームのデザイナーからリテイクをもらう(結果、遅れる)
エンジニアがその組織に在籍している理由はプロダクトに貢献したいからである。残業したいわけではないができれば開発がずるずる遅れることは避けたい(結果、頑張る)
なにを主張したいかというと、エンジニア以外のコミュニケーションミスはエンジニアの負担として返ってくる。これに強く影響するのは
開発チームの人数(=メンバーのコミュニケーションチャネル数)
あるメンバーが「同時に」持っている案件の数
「手が空いているから」あるいは「まだ行けそう」という理由でいろいろな物に手をつけることをやめて、隣の席のメンバーと話す頻度を増やそう。
チーム間の依存性
チーム間の依存性を可視化すると言ったが具体的にはどうするか。例えばこういうやり方をとることができる。
メンバー1人に対して、名目上のチームを1つ割り当てる
メンバー1人に対して、実貢献したチームを割合で出す(出し方は何でも良い、自己申告とか)
この時
あるメンバーについて、名目上のチームと実貢献したチームが全く異なっている場合、メンバーを移動させた方が良い
あるメンバーについて、実貢献したチームが複数あるような場合、おそらくオーバーワークである、負担を分散するようにチームビルドをするか、採用を検討したほうが良い
複数のメンバーについて、実貢献したチームが複数あるような状態の場合、コミュニケーションが相当に混乱している可能性がある、チームを組み替えるかチームの独立性を高めるような体制にする必要がある、あるいは取り組むべき課題が分散しすぎているかもしれない
同じプロダクトを作っている以上、あるチームと別のチームが何らかの形で依存することはありうるし、自然なことでもある。独立性を担保しつつ、どうやって協調するのが良いかというバランス感覚が重要である。
デリバリー
開発とQA
手動で確認するか自動でテストするかはともかく、ユーザーに届くサービスが開発者の意図したものであることは極めて重要である。
不具合はそもそもユーザー体験を損なう
分析にノイズが乗り、本来の目的である仮説検証ができなくなる(ユーザーの反応が良くなかったとしてそれは企画自体に問題があるのか、それとも不具合のせいなのか)
どこまで作ったらエンジニアから別の人の手に渡すべきだろうか
エンジニアやりすぎ:不具合が1件も出ないようにエンジニアが手動デバッグを延々行うのはやりすぎである。エンジニアのリソースを無駄にしている
エンジニアやらなすぎ:未完成あるいは不具合多すぎの状態でエンジニアの手を離れるのはやらなすぎである(後で全く同じ確認をする必要がある)。テスターのリソースを無駄にしている
実装完了時点での品質保証のSLOとも言えるが、これもバランスの問題である。ミラティブでは、テスターあたりの不具合発見件数で概ねのバランスを取るようにしている(いつかテックブログに書く、かも)。
開発チームの数は採用できたエンジニアの人数と会社の残キャッシュでだいたい決まる。QAにはどれだけの人数を割くべきだろうか。基本的には上記のバランスが取れる最大値、つまり開発チームの数と比例する。
リリース頻度
デプロイ頻度は多いほうが好ましい(four keys)、これはあまり異論はないと思う。では、ユーザーがサービスに触れる瞬間=リリースの頻度はどうだろうか。
開発チームは独立的に開発するし、デプロイも独立にできると思うが、開発した機能が提供するユーザー体験が独立するとは限らない。一つのプロダクト内の機能であれば同一のユーザーに提供しているのだからむしろ独立するほうが少ない。
機能のリリースはチーム間の同期が必要である
リリースがアドホックに行われるとコミュニケーションコストが増える
定期的に行われるイベントはコミュニケーションコストが圧倒的に小さい。リリース頻度にばらつきがあることは予測を困難にし、チームのコラボレーションを阻害する。
オペレーション
問い合わせ対応
機能をリリースしたあとに開発者がなにもしないということはありえない。日常的なユーザーからの問い合わせに対する対応、そして予測不可能な障害や不具合に対する対応が(ないほうが望ましいとしても)存在する。
サービスの規模が小さいときは問題にならない。ユーザーからの質問に開発者が答えればそれで良い。問題はサービス規模が大きくなったときで、例えばそのサービスを利用するユーザーが1000万人いて、1人あたり100年に1回(!)お問い合わせをすると、1日あたり274件(!)の問い合わせが存在する。
対応フェーズは4段階に分かれる。
問い合わせ前
ユーザーが自己解決可能できることが望ましい(UX)
不具合があれば問い合わせは増える(QA)
CS
非開発者が解決できることが望ましい(CS機能)
CS組織が必要である(CS組織)
開発者によるトリアージ
該当の機能を開発していない開発者が解決できることが望ましい
開発者の負担を軽減(分散)させることが必要である
根本的な解決あるいは改善
必要があれば新規のバックログをつくる
開発組織とCS組織のコミュニケーション(エスカレーション)
開発チームが単一ならばそれほど複雑ではないが、複数ある場合は工夫が必要になる。開発チームの独立性を高めるのはそうすることによってコンテキストを共有し、効率的に開発するためである。逆に都合の悪いこと、起きる不具合もコンテキストに依存する(そのチームが解決することが最速であることが多い)。そのため、
初期対応する開発者は持ち回りとしつつ
根本的な解決は開発チームに委ねる
とすることが多いだろう。いずれにしても負担を押し付け合う形でなく全体の効率が最適化されるような体制が求められる。
インシデント対応
非常事態は起きるときは起きる。これも4段階に分けよう。
対応前
問題を発見し、関係者に適切に通知する必要がある
品質保証の時点で問題があった可能性がある
初期対応
誰かが常に対応できる状態である必要がある(オンコール担当)
これについて負担を軽減(分散)させる必要がある
根本対応
初期対応で行われるのはトリアージであって、根本的な対応はチームで解決する必要がある
ポストモーテム
適切に振り返りを行う
細かい話はこの本を読んでおくと良いかもしれない。
サービスの規模が大きくなるとオペレーションコストを無視できなくなる。各フェーズに適切なKPI(あるいはSLO)を設定しハンドルする必要がある。
おわりに
社内のエンジニアのパフォーマンスを改善したいなら、エンジニア組織に注目する前にその外側を改善することを考えると良いかもしれない。そうすることでエンジニアに余白が生まれ、結果的にエンジニア組織が改善される。
この記事が気に入ったらサポートをしてみませんか?