
画像ファイルの文字を認識するプログラムをChatGPTに教えてもらったら、1時間で実装できた(OCR, pytesseract)

今回は、pythonで、画像ファイルの文字認識するプログラムをChatGPTに教えてもらおうとおもいます!
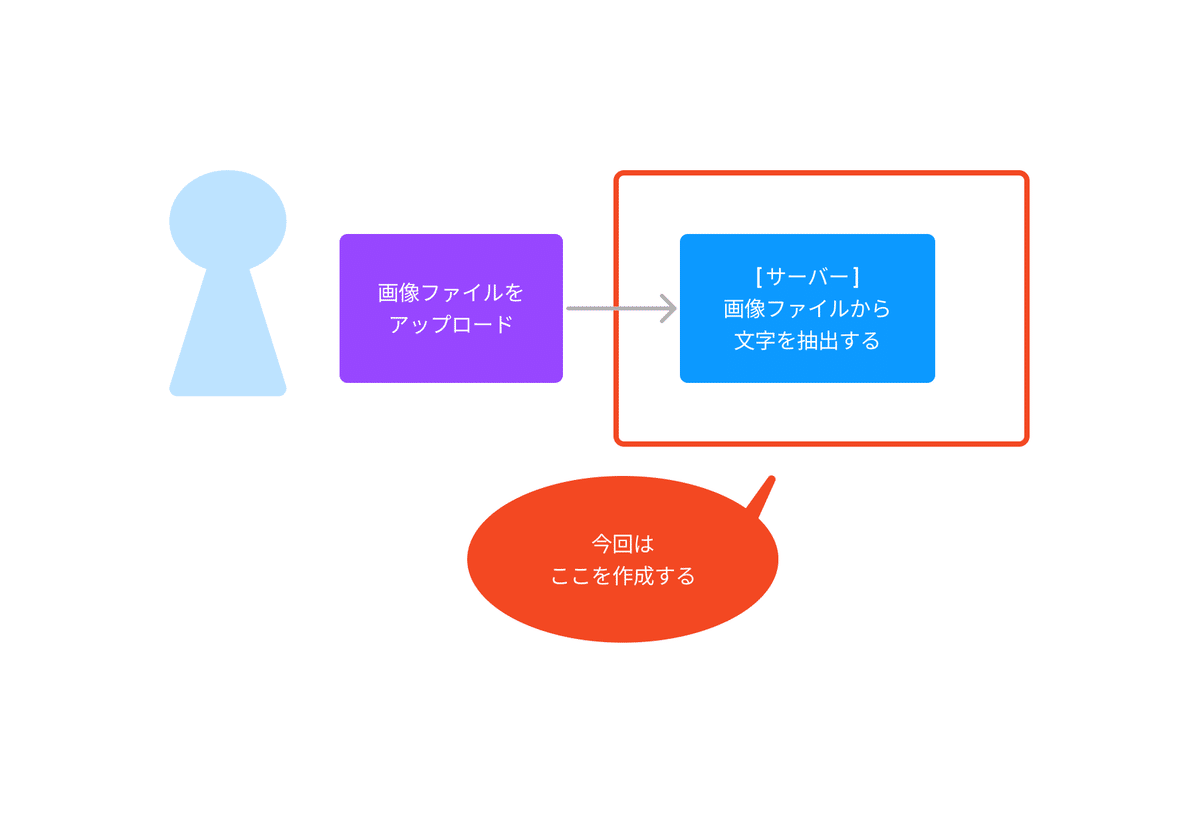
1.まずは画像ファイルから文字認識するコードを教えてもらう
まずは、ChatGPTに画像ファイルから文字認識するコードを教えてもらおうと思います。そこから微調整してコードを完成させていく予定です。
プロンプト
pythonで写真ファイルを読み込み、文字認識をして、テキスト化するコードを教えてください
ChatGPTからの回答
写真ファイルから文字を認識してテキスト化するためには、pytesseract というライブラリを使用する方法があります。pytesseract はGoogleのOCRエンジンであるTesseractをPythonから利用できるようにしたライブラリです。
まずは pytesseract と画像処理ライブラリの Pillow をインストールします。
pip install pytesseract pillow次に、以下のコードで写真ファイルから文字を認識してテキスト化する例です。
import pytesseract
from PIL import Image
# 画像ファイルを開く
image_path = 'sample_image.jpg' # 'sample_image.jpg'は適切な画像ファイルに置き換えてください
image = Image.open(image_path)
# OCR(光学文字認識)で画像からテキストを抽出
text = pytesseract.image_to_string(image, lang='eng') # 'eng'は英語の言語設定です。他の言語に変更可能
# 抽出したテキストを表示
print("抽出されたテキスト:")
print(text)このコードでは、指定した画像ファイル(例えばJPEGやPNGなど)から文字をOCRで認識し、テキスト化しています。pytesseract.image_to_string() 関数は画像を受け取り、その中のテキストを文字列として返します。lang パラメータで使用する言語を指定できます。
ただし、文字認識の精度は画像の品質や内容に大きく依存します。特にノイズが多い場合や、フォントが特殊な場合には正確性が低下する可能性があります。また、日本語などの多言語に対応するためにはTesseractの言語ファイルを追加でインストールする必要があります。
上記のコードを使用する際には、sample_image.jpg を適切な画像ファイルのパスに置き換えて実行してください。写真の内容によっては、認識の正確性が異なることに注意してください。
2.画像ファイルをアップロードする画面を作る
Djangoで画像ファイルをアップロードするフォーム画面一式(views.py、html、urls.py)も、ChatGPTに作成してもらいますが、ここのChatGPTとのストロークは割愛します。
3.動作確認する
お・・!
もうできたの??
作成した画像アップロード画面にて、画像ファイルを読み込むとエラーとなってしまいました。。さすがに多少はエラーが発生しますよね。。
エラーログもそのままChatGPTに投げてしまいます!
エラーログをそのままコピペで解決してくれるので、エラー解消する作業の時短になります!
プロンプト
File "/opt/bitnami/python/lib/python3.11/site-packages/django/forms/fields.py", line 708, in to_python from PIL import Image ModuleNotFoundError: No module named 'PIL'
ChatGPTからの回答
ModuleNotFoundError: No module named 'PIL' エラーは、Pillow(Python Imaging Libraryのフォーク)が見つからないことを示しています。PillowはDjangoで画像を扱うための一般的なライブラリですが、インストールされていないようです。
これを解決するためには、Pillowをインストールする必要があります。
まず、SSHなどのコンソールからDjangoが稼働している環境に入り、次のコマンドでPillowをインストールします。
pip install PillowPillowがインストールされたら、ImageFieldを使用して画像をアップロードするフォームを作成できるはずです。これで from PIL import Image のエラーが解決されるはずです。
もし、Bitnamiのような特定の環境で問題がある場合は、Bitnami DjangoスタックにPillowをインストールする方法を調べる必要があるかもしれません。通常は上記のコマンドで問題なくインストールできますが、特定の環境によっては手順が異なることがあります。
4.文字認識した内容をログに出すように修正する
上記の不足していたPillowをインストール後、文字認識した内容をどこにも表示していなかったので、ログに出力するようにChatGPTにプログラム修正をしてもらいます。
以下プロンプトで提示しているコードは、上記でChatGPTから提示されたコードで、このコードをベースに修正してもらいたいのでコードも提示しました。
プロンプト
ファイルを読み込んだ後に、pytesseractで文字解析をしたいです。
文字解析した文字列は、loggerで出力する
def image_upload_view(request):
if request.method == 'POST':
form = ImageUploadForm(request.POST, request.FILES)
if form.is_valid():
# form.cleaned_data['image'] でアップロードされた画像にアクセス可能
return HttpResponseRedirect('/success/')
else:
form = ImageUploadForm()
return render(request, 'image_upload.html', {'form': form})
ChatGPTからの回答
理解しました。ファイルを読み込んだ後に pytesseract を使って文字解析し、その結果を logger で出力するための image_upload_view を作成します。以下がコードの例です。
まずは views.py に次のようなコードを追加します。
import pytesseract
from PIL import Image
import logging
logger = logging.getLogger(__name__)
def image_upload_view(request):
if request.method == 'POST':
form = ImageUploadForm(request.POST, request.FILES)
if form.is_valid():
# 画像ファイルを取得
image_file = request.FILES['image']
# Pillowを使って画像を開く
image = Image.open(image_file)
# 文字認識
try:
text = pytesseract.image_to_string(image, lang='jpn')
# ロギング
logger.info("文字解析結果: %s", text)
# ここで他の処理を行う
return HttpResponseRedirect('/success/') # 成功時にリダイレクトするURL
except Exception as e:
# 例外処理
logger.error("文字解析エラー: %s", str(e))
return HttpResponseRedirect('/error/') # エラー時にリダイレクトするURL
else:
form = ImageUploadForm()
return render(request, 'image_upload.html', {'form': form})このコードでは、ファイルを読み込んだ後に pytesseract を使って文字解析を行います。logger を使って、解析結果やエラーを出力します。
必要なライブラリやモジュールをインポートして、image_upload_view メソッド内で画像の文字解析を行っています。解析結果やエラーは logger を使ってログに出力しています。解析結果は info レベルで、エラーは error レベルで出力しています。
ImageUploadForm は、以前定義した画像アップロード用のフォームです。
このコードを使うと、画像をアップロードした際に文字解析を行い、その結果をログに出力することができます。エラーが発生した場合にも適切にログに記録されます。
5.動作確認その2
上記ログを出力するロジックをプログラムに反映したので、再度動作確認です!
行けるか・・??
・・・
エラーでした、、
またエラーとなりましたので、再度ChatGPTに聞いてみます。
プロンプト(Tesseractが見つからないエラー)
File "/opt/bitnami/python/lib/python3.11/site-packages/pytesseract/pytesseract.py", line 260, in run_tesseract raise TesseractNotFoundError() pytesseract.pytesseract.TesseractNotFoundError: tesseract is not installed or it's not in your PATH. See README file for more information.
ChatGPTからの回答
pytesseract.pytesseract.TesseractNotFoundError エラーは、Tesseractが見つからないことを示しています。Tesseractは pytesseract ライブラリが利用するOCRエンジンですが、インストールされていないか、パスが通っていない可能性があります。
Tesseractをインストールしてパスを設定する方法について説明します。
1. Tesseractのインストール
まず、Tesseractをインストールする必要があります。以下の手順でインストールします。Windows:
Tesseractのインストーラーを公式サイトからダウンロードして実行します。インストーラーに従ってインストールします。
インストールが完了したら、環境変数 PATH にTesseractのインストールパスを追加します。通常は C:\Program Files\Tesseract-OCR などです。
macOS:
Homebrewを使ってインストールします。
brew install tesseractLinux (Ubuntuなど):パッケージマネージャーを使ってインストールします。
sudo apt-get install tesseract-ocr2. Pythonとpytesseractのインストール
次に、Python用の pytesseract ライブラリをインストールします。
pip install pytesseract3. Tesseractのパス設定
Tesseractが正しくインストールされたら、settings.py ファイルで TESSERACT_CMD を設定してパスを指定します。以下のように設定します。
# settings.py
TESSERACT_CMD = '/path/to/tesseract'もしくは、pytesseract.pytesseract.tesseract_cmd を使用して、アプリケーション内で直接パスを指定することもできます。image_upload_view 関数内で次のように設定します。
import pytesseract
def image_upload_view(request):
pytesseract.pytesseract.tesseract_cmd = '/path/to/tesseract'
# 以下略上記の手順でTesseractをインストールし、パスを設定することで、pytesseract を使って画像の文字解析を行うことができます。
プロンプト(TESSERACT_CMDのパスの設定の仕方)
TESSERACT_CMD = '/path/to/tesseract' パスは何を設定するのですか
ChatGPTからの回答
TESSERACT_CMD に設定するパスは、Tesseractの実行可能ファイルである tesseract コマンドのパスです。Tesseractが正しくインストールされている場合、このコマンドを実行することで文字認識を行います。
では、各OSでの一般的な tesseract コマンドのインストールパスを示します。
Windows:
通常のインストールでは、以下のパスにTesseractがインストールされます。
C:\Program Files\Tesseract-OCR\tesseract.exeしたがって、Windowsで TESSERACT_CMD に設定するパスは次のようになります。
TESSERACT_CMD = 'C:/Program Files/Tesseract-OCR/tesseract.exe'macOS:
Homebrewを使ってインストールした場合、通常のパスは次のようになります。
/usr/local/bin/tesseractmacOSで TESSERACT_CMD に設定するパスは次のようになります。
TESSERACT_CMD = '/usr/local/bin/tesseract'Linux (Ubuntuなど):
通常のパスは次のようになります。
/usr/bin/tesseractLinuxで TESSERACT_CMD に設定するパスは次のようになります。
TESSERACT_CMD = '/usr/bin/tesseract'上記のように、TESSERACT_CMD には実際の tesseract コマンドのパスを指定します。これにより、pytesseract はTesseractを呼び出して画像から文字を認識することができます。どのOSを使っているかに応じて、適切なパスを設定してください。
6.動作確認その3
上記ログを出力するロジックをプログラムに反映したので、再度動作確認です!
今度こそ行けるか・・??
・・・
エラー・・!
またエラーとなりましたので、めげずにChatGPTに聞いてみます。
プロンプト
File "/opt/bitnami/python/lib/python3.11/site-packages/pytesseract/pytesseract.py", line 264, in run_tesseract raise TesseractError(proc.returncode, get_errors(error_string)) pytesseract.pytesseract.TesseractError: (1, 'Error opening data file /usr/share/tesseract-ocr/4.00/tessdata/jpn.traineddata Please make sure the TESSDATA_PREFIX environment variable is set to your "tessdata" directory. Failed loading language \'jpn\' Tesseract couldn\'t load any languages! Could not initialize tesseract.')
ChatGPTからの回答
pytesseract が TesseractError を出力しています。このエラーは、Tesseractが言語データを読み込めない場合に発生します。TesseractError の内容を見ると、言語データファイル jpn.traineddata を開けないというエラーです。
解決するためには、Tesseractに日本語の言語データを正しく設定する必要があります。以下の手順で進めてみてください。
1. Tesseractの日本語言語データのインストール
まず、Tesseractに日本語の言語データ jpn.traineddata をインストールします。
Linux (Ubuntuなど):
tesseract-ocr-jpn パッケージをインストールします。
sudo apt-get install tesseract-ocr-jpn2. TESSDATA_PREFIXの設定
Tesseractが日本語の言語データを正しく読み込むためには、TESSDATA_PREFIX 環境変数を設定する必要があります。通常は /usr/share/tesseract-ocr/ 以下に tessdata フォルダがあります。
以下の手順で環境変数を設定します。Linux (Ubuntuなど):
.bashrc や .profile などのシェルの設定ファイルに次の行を追加します。
export TESSDATA_PREFIX=/usr/share/tesseract-ocr/設定ファイルを保存後、シェルを再起動するか、以下のコマンドを実行して環境変数を反映します。
source ~/.bashrc環境変数が設定されたら、TESSDATA_PREFIX に Tesseract のデータフォルダが指定され、jpn.traineddata などの言語データが正しく読み込まれるはずです。
3. Djangoの設定
Djangoの settings.py ファイルで TESSDATA_PREFIX を設定することもできます。
# settings.py
TESSDATA_PREFIX = '/usr/share/tesseract-ocr/'4. テスト
上記の手順を行った後、Djangoアプリケーションを再起動して、再度画像アップロードを試してみてください。これにより、Tesseractが日本語の言語データを正しく読み込むことができるはずです。
7.動作確認その4
上記ログを出力するロジックをプログラムに反映したので、再度動作確認です!
今度こそ行けるか・・??
・・・
行けたー!!!
無事画像ファイルから文字を読み込めました。嬉しいです!
実際に読み込んだ画像ファイルと、読み込み結果は以下の通りとなります。
8.検証その1
以前、noteの記事用に作成したスクショを取り込んでみます。
読み込んだ画像ファイル

読み込み結果

正確に読み取れている感じがしますね!
8.検証その2
次にYahooニュースの一部をスクショしたもので検証していきます!
読み込んだ画像ファイル

読み込み結果

吹き出しアイコンや、Newアイコンなどが含まれていると、その箇所は文字化けした形で取り込まれてしまいますね、、
おわりに
最後まで読んで頂き、ありがとうございました!
ChatGPTを使用しながらコーディングをすると、やはりサクサク出来て気持ちがいいですね!1時間程度で完成することができました。
写真から文字認識させて、その読み込んだ文字列を加工したりすることで、色々なことに使えそうですね!
今回作ったプログラムは、画像から文字を取り込むまでのステップが、写真を撮り、サイトに写真をアップロードしないと確認できず、効率が良くないので、アプリで写真を撮ったら即文字認識みたいな仕組みの方が効率が良さそうですね。
以前にiosアプリで文字認識させるプログラムを作ったことがありますが、内容を忘れてしまったので、ios版もまた作ってみたいと思いました!
おまけ
最近、ChatGPTを使用し、色々なことを模索しています。
もしよければ、以下の記事も見て頂けると嬉しいです!
この記事が気に入ったらサポートをしてみませんか?