
エンジニアの稼働率を上げれば上げるほど機能リリースが遅くなっていく

組織内のメンバーを「リソース」として見始めると、それを100%使い切ることにばかり注力してしまいます。リソースの稼働率を下げることは、すなわち、生産性を下げること。マネージャーは、まるで強迫観念に取り憑かれたように、そのような考えに囚われます。
自社でのソフトウェアプロダクト開発において、その対象は特に、開発者に強く向けられます。その理由は明らかでしょう。バックログに積み上がり続けるアイデアをソフトウェアに変えられるのは、開発者だけです。より多く、できる限り早く、アイデアを市場投入したい。彼らに空き時間という無駄を作らせてしまうわけにはいかない。
しかし、そのような努力が、必ずしも良い結果につながるとは限りません。むしろ、開発者の稼働率を高めすぎたことが、リードタイムに悪影響を与えているかもしれないのです。そして言うまでもなく、アイデアの市場投入が延びれば延びるほど、ユーザーにとってもビジネスにとっても、得られるはずの価値は目減りしてしまうのです。
日常生活での例
リソースの稼働率を高めると、リードタイムが悪化するとはどういうことでしょうか。実はそのような事例は、日常生活にも溢れています。
大型商業施設やビジネス街にある人気のコーヒーショップは、いつ行っても混んで行列ができています。コーヒー1杯を買うために、5分や10分並ぶこともざらです。ショップにとってこの状況は、店舗の稼働率が高く、それだけ時間効率良く売上をあげているということです。ショップスタッフが常に時間を持て余すような閑散とした状態ではビジネスになりません。
しかし、ショップの客である私たちにとっては、行列で待たされるのは非効率でとても苦痛です。むしろ、ショップが閑散としてすいていた方が、行列に並んで待つ必要もなく、コーヒーを手にするまでのリードタイムは短く済み、効率的です(そんな閑散とした不人気ショップに行きたいかは別として)。
少し遠い場所へ自動車で向かうなら、一般道より高速道路を走った方が短時間で目的地に到着できます。しかし、いつもそうであるとは限りません。高速道路によって得られる効率性は、自動車で移動する誰もの便益であるため、多くの利用者によって高速道路はしばしば渋滞します。そうなると、むしろ一般道を使うより時間がかかるかもしれません。
高速道路というリソースにとっては、そこを走る自動車が少ないすいている時ほど稼働率が低い状態と言えます。稼働率があまりに低い高速道路は無駄です。一方で、そこを走る自動車にとっては、すいている時の方が目的地までの到着時間、つまりリードタイムを短縮できます。渋滞した高速道路を走ることは、時間とお金の無駄に感じてしまいます。
このように、リソースの稼働率を高めたことでリードタイムが悪化する場面はどこにでも見られる光景です。何も驚くようなことではなかったのです。
ソフトウェア開発での例
開発者にとっての高稼働な状態とは、止むことなく次々と割り当てられる開発タスクを処理し続けている状態を指します。

その開発タスクとは、新機能の実装もあれば、別の開発者が実装したコードのレビューかもしれません。バグフィックスなんかもあるでしょう。途中でもし少しでも手が空いたならば、更に新たな開発タスクが挿入されます。
このような状態がリードタイムにどのような影響を与えるのか、具体的な例として、機能開発のシンプルな流れを追ってみます。一般的な開発プロセスでは、誰かがコードを実装し、そのコードをまた別の誰かがレビューするというステップを踏みます。その後にもいくつかステップがあり、それらを経て最終的にリリースされるのですが、ここではコードの実装とレビューのみを取り上げます。
Aさんが、機能Xの実装を半日で終え、Bさんにコードレビューを依頼します。コードレビュー自体も、半日かかる見込みなので、うまくいけばリードタイムは1日で済むはずです。

しかし、Bさんは、機能Xのコードレビューをすぐに開始できません。他の機能開発タスクをいくつか抱えているからです。そのため、依頼された機能Xのコードレビューは、Bさんのタスクリストの最後に追加することになります。

ここで、Bさんが抱えるタスクの規模がいずれも0.5日程度で、かつ稼働率が75%だとしましょう。すると、待ち行列理論上、機能Xのコードレビューは1日半ほど待たされることになります。そこからさらに、半日かけてレビューしますので、Aさんにコードレビューを依頼されてからコードレビューが終わるまでに2日を要することになります。Aさんの実装が半日だったので、機能Xの開発に要した期間は合計で2日半となります。

ここでもし、Bさんの稼働率が50%だったらどうだったかと言えば、コードレビューの待ち時間は半日ほどになるため、実装に半日、レビューに半日で、合わせて1日半で終了できます。
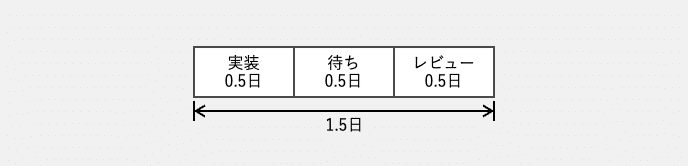
稼働率が75%のリードタイム2.5日と、50%のリードタイム1.5日を比較すると、前者は後者の1.67倍かかる結果となりました。どちらのケースも、コード実装に半日、コードレビューに半日で、実際の処理時間としては1日しか要していません。待ち時間が、リードタイムの違いとしてあらわれているのです。そしてこの待ち時間は、稼働率が上がるほど指数関数的に大きくなります。

もちろん、機能XのコードレビューをBさんが最優先で処理すれば待ち時間がなくなり、リードタイムは縮まります。しかし、その割り込みにより、Bさんのタスクリストに控えていたその他の機能開発のリードタイムが犠牲になってしまいます。
他にも、ガントチャートに落とし込んでタスクの開始日・終了日を完全にスケジュール化することで待ち時間を無くせるとも考えられます。しかし、ガントチャートによるタスク管理では、個々のタスクにバッファが組み込まれる傾向が強まるように感じます。決められた開始日・終了日を守れなければ、後続タスクの開始日・終了日に影響が連鎖するため、その保険としてバッファが組み込まれるからです。結果としてクリティカルパスが長くなってしまいがちです。それはつまり、プロジェクト全体のリードタイムが長くなっているということです。
有能なプロジェクトマネージャーであれば、こういった事態も回避できるでしょう。しかし、そのような人材は希少です。どこの組織にも十分に揃っているわけではありません。
ガントチャートによるタスク管理でも、CCPM(クリティカルチェーンプロジェクトマネジメント)のプロジェクトバッファを導入することでリードタイムを短くすることもできますが、ガントチャートでのタスク管理手法は、自社ソフトウェアプロダクトの内製プロジェクトにそもそも合わないように感じます。プロジェクトマネージャーを中心とする中央管理型より、個々のチームメンバーがが自分で考えて行動し、互いに協力し合う自己管理型が合うと考えているからです。前者をオーケストレーションと呼ぶなら、後者はコレオグラフィーと呼べるでしょう。
以降は、自己管理型組織を前提として検討を進めます。
リソースよりフローに焦点をあてる
ここまでで例に挙げた、コーヒーショップでの個々の客の流れや、高速道路での1台ごとの自動車の流れ、開発プロセスにおける機能Xの流れを「フロー」と呼びます。そして、その流れの効率性を「フロー効率」と呼びます。また、この文脈においてのリソースの稼働率を「リソース効率」と呼ぶこともあります。
ちなみに、機能Xの開発において稼働率75%時のリードタイムは2.5日ですが、そのうち1.5日は待ち時間です。つまり、リードタイムのうち60%が待ち時間なので、フロー効率は40%となります。

同様に、稼働率50%時のフロー効率は67%となります。

こうしてみると、いくらリソースを効率良く使えても、フローの観点ではとても効率が悪い状況に陥っていることがよくわかります。私たちは、フローにもっと目を向ける必要があります。これは、ソフトウェアプロダクト開発におけるパラダイムシフトとも言えるかもしれません。
現状に最適化された見積りはフローの悪化を隠す
コーヒーショップや高速道路のフローの変化は、目に見えるという点で、ソフトウェア開発とは異なります。コーヒーショップなら、行列の長さや進みの速さを観察すれば、フロー効率の変化や良し悪しが分かります。高速道路なら、自動車の走行スピードを眺めていれば明らかでしょう。
それではソフトウェア開発におけるフローは、何を観察すれば把握できるのでしょうか。フローが停滞して待ち状態に入っていたり、進んでいてもスピードが落ちているといったことを知る術です。
先の例の機能X開発は、コード実装0.5日、コードレビュー0.5日なので、理想的には1日で終わるはずです。それを見積りとして開発した結果、実績が2.5日かかったとしましょう。

見積りと実績の予実差異は1.5日です。この1.5日を待ち時間だと推測できなくもありません。

この場合、待ち時間の1.5日は全体の60%を占めるので、フロー効率は40%となります。

この考え方であれば、見積りと実績の予実差異を見ることで、事後にフローを知ることができるようにも思えます。しかし、実際はそう上手くいきません。
まず、誰でも気付くとおり、見積りより実績が大きくなる原因が、待ち時間だけにあるとは限らないからです。単にコード実装やコードレビューに予想以上の時間がかかってしまっただけかもしれません。

そもそも機能X開発の見積りは、1日とならないでしょう。この規模の開発が2.5日かかるようなチームであれば、その見積りも2.5日近くとなるからです。そうすると、見積りも実績も2.5日となり、フロー効率は100%になってしまいます。

見積りは現状に最適化されやすいので、予実差異はこのようにチームのフロー効率の変化を追うことに適しません。理想的には1.0日の開発規模であっても、チームのそれまでの開発実績に照らし合わせ、見積りが2.5日にも、1.5日にもなるからです。これでは、フロー効率が改善しても悪化しても、見積りもそれに合わせて最適化され、フロー効率が常に100%前後になってしまいます。
だったら、フローごとの待ち時間を観察すれば良いと思うかもしれませんが、これも注意が必要です。パーキンソンの法則によって、仕事のために与えられた時間はすべて消費されてしまう運命にあるからです。現状に最適化された見積りが2.5日であれば、その全てがコード実装やコードレビューに消費されてしまいます。待ち時間があらわれることはないでしょう。

ソフトウェア開発におけるフローを、コーヒーショップの行列や高速道路の渋滞のように観察することはできないのでしょうか。フローの改善を試みる前に、フローの可視化が必要です。
その可視化手法のひとつが、リーン開発の「カンバンボード」です。カンバンボードを既に導入済みの開発チームであっても、フロー改善という観点でボードを眺めれば、また見え方が変わってくるかもしれません。
カンバンボードでフローを可視化する
カンバンボードは、開発プロセスをいくつかの工程に分け、チケットなどで管理されるそれぞれの開発単位が現在どの工程に位置するかを可視化するツールです。各工程を「ステージ」と呼び、開発単位は「チケット」や「カード」、「アイテム」などと呼びます。フローの観点では、「フローユニット」と呼んだりもします。ボード自体は、ホワイトボードなどを使った物理的なボードでも良いし、チケット管理ツールなどに搭載されたボード機能を使っても良いでしょう。
次の図は、6つのステージを持つシンプルなボードと、そこに貼り付けられたチケットのイメージです。

ボードの良いところは、可視化の対象がリソースではなくフローである点です。ボードをみれば、各チケットが現在、どこまで進んでいるかが明らかです。その上、フローに関する2つの重要なメトリクスを提供してくれます。リードタイムとスループットです。
リードタイムは、チケットに着手してから完了までに要した期間です。これは、チケットに記録された着手日と完了日を見れば明らかでしょう。このメトリクスをできる限り縮めることで、フローの流れが速くなります。
スループットは、一定期間の間にいくつのチケットが完了したかを表すメトリクスです。チケットの完了日をもとに集計できます。いくらリードタイムが短くても、たまにしかチケットが完了しないようなら、生産性が高い状態とは言えません。おそらくそれは、稼働率が低すぎるのでしょう。スループットは、フロー効率に焦点をあてながらリソース効率の無駄を無くすために利用できるメトリクスです。

リードタイムもスループットも、どの区間を計測するかは自由です。上図のボードで言えば、コード実装に着手してからコードレビューが完了するまででも構いません。
ただ、これだけではまだ不十分です。フローの待ち状態が可視化されていません。
フローの待ち状態を可視化する
各工程をあらわすステージを並べただけのボードでは、各チケットが進捗しているのか、停滞しているのかを表現できません。Aさんによるコード実装が終わり、Bさんによるコードレビュー待ちとなった機能X開発チケットの状態が可視化されていないのです。
フローの待ち状態が発生する主要なタイミングは、ステージからステージへの移動時です。ステージ遷移にともなってチケットの担当者が変わり、その新しい担当者が着手するまでの空白時間です。
そこで、各ステージに、待ち状態を表す領域を設けます。ステージでのタスクが完了して次のステージに遷移するチケットはすべて、いったんこの「待ち」領域に配置することになります。そして新たな担当者がタスクに着手するタイミングで、チケットを「仕掛中」領域に移動します。

これで、フローの待ち状態を可視化できました。
なお、フローの待ち状態の把握を追求し過ぎることは、コストに見合わないので諦めた方が良いでしょう。待ち状態は、細かく見ればいたるところで発生します。担当開発者がメールチェックしている間や、同僚の相談にのっている時間、トイレに行っている時間もそう。しかし、このような細かな単位で計測することによる正確性の追求は現実的ではありません。
とは言え、開発者が開発以外の業務にあまりに時間が奪われているようなら、別途、業務改善が必要になるでしょう。
マルチタスクという渋滞は見えづらい
カンバンボード上のフローは、待ち行列を作るより、渋滞する方が多いように思います。
待ち行列とは、各ステージに設置した待ち領域にとどまるチケット群のことです。これらのチケットは、コーヒーショップの行列のように、サービスを受けられるのを待っています。
渋滞とは、もちろんカンバンボードの状態を高速道路の渋滞になぞらえた表現です。各ステージの仕掛中領域に入ったチケットは、最大のパフォーマンスで進捗するとは限らず、遅々として進まないこともあります。フローが渋滞したカンバンボードでは、渋滞した高速道路のように、仕掛中領域にとどまるチケットの総数が通常より多くなります。
このような状態が起きる原因は、開発者のマルチタスクです。1人の開発者が、1度に複数のタスクを処理している状態です。
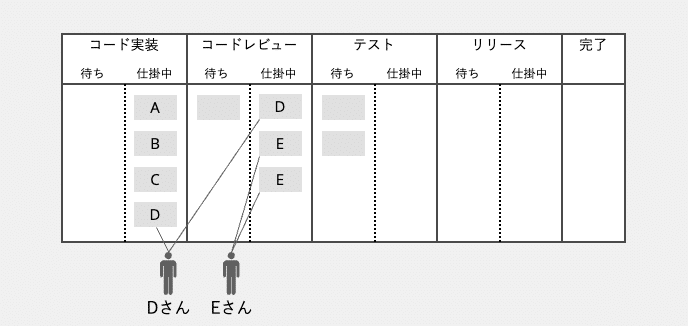
マルチタスクがない状態のボードでは、仕掛中領域に配置されたチケットの総数が、チームメンバー数以下になるはずです。しかし、マルチタスクが発生しているボードでは、仕掛中領域に配置されたチケットの総数がメンバー数を超えることになります。
マルチタスクの問題は、渋滞で自動車の進みが遅くなるのと同様で、チケットの進捗をスローダウンさせます。これは、待ち状態とは異なるタイプのフロー効率の悪化と言えるでしょう。
例えば、ある開発者が、T1とT2という2つのコード実装タスクを担当するとします。どちらも1日で完了できる規模です。着手日を4月1日として、シングルタスクで順番にやれば、T1は4月1日中に完了し、T2は4月2日中に完了します。

しかしマルチタスクで同時に取り組んだら、完了日はT1もT2も4月2日になってしまいます。本来であればT1は4月1日に終わったはずが、1日延びてしまいました。
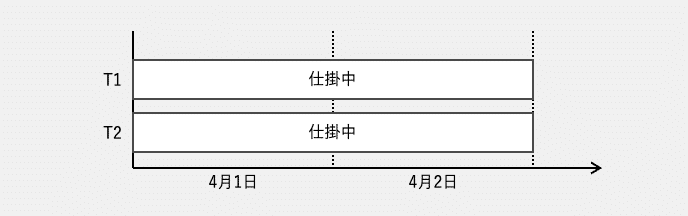
これは、それぞれのタスクに対し、担当開発者1人の作業時間を半分ずつしか割り当てられないからです。マルチタスクのオーバーヘッドを考えると、結果はもっと酷いことになるかもしれません。これは明らかに、フロー効率を悪化させています。
マルチタスクによるフローの遅延は、目立たないため、見落としがちになることも問題です。仕掛中の領域内のチケット数をかぞえたり、誰がどのチケットに取り組んでいるかを確認しないと把握できないからです。
マルチタスクによるこのような問題を回避するためにも、マルチタスクを防ぎ、チケットを待ち領域に留めることを推進しなければなりません。待ち領域にあるチケットは目に付きやすいので、フローの状態を把握しやすくなるからです。そのために使えるプラクティスが、WIP制限です。
なお、マルチタスクが発生する要因のひとつは、各ステージで処理するタスクが大きすぎることにあるように思います。1つのタスクに取り組む時間が長すぎて、その間に別のタスクにも取り組まざるを得ない状況が起きるのです。したがって、各チケットで扱うタスクの規模を小さくするよう工夫することも、マルチタスクの発生を防ぐ手段になるでしょう。
WIP制限でマルチタスクを抑制する
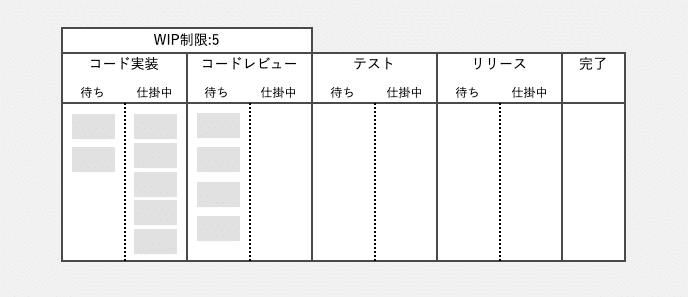
「WIP制限」とは、仕掛中のタスクの数を制限するプラクティスです。カンバンボード内で仕掛中領域に配置できるチケットの数を制限します。仕掛中のチケットが制限数に達したら、それ以上は仕掛中領域に進めることができません。待ち領域で待機させることになります。こうすることで、1人でいくつもの仕掛中タスクを抱えるマルチタスクの発生を抑止できます。

図では、「コード実装」ステージと「コードレビュー」ステージを合わせて5という制限数を設定しています。この5という制限数は、チームメンバー数と一致させています。メンバー1人につき、仕掛中のタスクを1つまでに制限するためです。ステージごとにWIP制限を設ける方法も一般的です。
このように制限しても、メンバーが1人で複数の仕掛タスクを持つこともできてしまいます。ただそうすると、他のメンバー1名がタスクに取り組めなくなりますので、チーム内でタスクアサインの調整を行うことになるでしょう。こうやって、チーム内でのメンバーごとの負荷(稼働状況)のばらつきがが平準化されていきます。
ただし、仕事があまりにも属人化されたチームでは、このようなタスクアサインの変更ができません。特定のメンバーへの負荷の偏りや、酷いマルチタスクを生み出す原因は、「このタスクを担当できるのは、Aさんのみ」といった属人化にもあります。メンバーによって仕事の得意分野が違うことは当たり前だし歓迎すべき多様性だと思いますが、属人化までいくとフロー効率悪化や開発者間での稼働状況の偏りの原因になるため、解決すべき問題だととらえるべきでしょう。
全体最適でボトルネックを解消する
WIP制限を導入しても、チームメンバーみんながコード実装ばかりしていると、コードレビューステージの待ち領域にチケットがたまってしまいます。これは、コード実装ステージだけで見れば高いスループットとなりますが、カンバンボード全体でみれば、フローが止まり、リードタイムもスループットも低い状態です。
ここで必要な思考は、全体最適です。待ち領域に最もチケットがたまっているステージが、カンバンボード全体のフローを遅くするボトルネックです。チームは常に、ボトルネックにたまったチケットを消化することを優先すべきなのです。コードレビューステージの待ち領域にチケットがたまっているなら、チーム一丸でそれらのチケットに取り組み、フロー効率を高める行動が必要です。

ボトルネック解消を最優先にすると言っても、仕掛中のタスクを放り出して待ち領域にたまったチケットに取り掛かってしまっては、マルチタスク状態になるだけです。仕掛中のタスクを終わらせた人からボトルネック解消に取り組むのが良いでしょう。
そのためにも、タスクがなるべく小さくなるよう、チケットのサイズに留意することも重要です。チケットが扱う内容が大きいと、いざという時にボトルネック解消に取り組みたくても、手元の仕掛中タスクがなかなか終わらないといった事態に陥るからです。
どの待ち領域のチケットに取り組むべきかを全体最適で決定するためには、タスクと人を強く紐づけすぎないことも重要です。事前に決められたタスクのアサインの強制力やオーナーシップが強すぎると、メンバーはみな、自分のタスクにしか取り組まなくなってしまいます。待ち領域にチケットがたまっていても、それが他人のタスクであれば放置する。それよりも、自分が抱えるタスクを消化することの方が優先度が高くなってしまいます。
ペアプロでステージ遷移時の待ち時間を無くす
ここまでで見てきたように、フローの待ち状態は、チケットが次のステージに移る際に、担当者が切り替わるタイミングで多発します。

それなら担当者を切り替えなければ良いと思うかもしれませんが、そう単純でもありません。コード実装ステージからコードレビューステージへの遷移が端的な例です。コードの実装者とレビュアーが同じ担当者では意味がありませんからね。
しかし、コードの実装者とレビュアーが一緒にタスクを処理すれば待ち状態は発生しません。そのプラクティスとして、ペアプロが使えます。
ペアプロ(ペアプログラミング)は、1つのコード実装タスクに、2人のプログラマが同時に取り組むソフトウェア開発手法です。2人で同じディスプレイを見ながら、協力してコードを書き上げていきます。このようにすれば、コード実装とコードレビューの間に待ち時間は発生しません。実装が終わればそのまま2人でレビューすれば良いのです。そもそも、コードレビューはもはや不要です。実装と同時にレビューが行われているからです。

「2人で1つのタスクに取り組む」とだけ聞くと、リソースを無駄に消費するように感じ、導入に抵抗感があるでしょう。ところが、ある研究によれば、ペアによって低下する生産性は50%ではなく15%程度だということです。その上、欠陥が15%少なくなると言うのだから、思ったより導入しやすいプラクティスだと感じられるのではないでしょうか。
バッチ方式のリリースが真のボトルネックを作り出す
多くのプロジェクトで、バッチ方式のリリースが採用されています。この方式では、複数の機能追加や機能改善、バグフィックスなどを一度にまとめてリリースします。単一の機能追加ごとにリリースを実施するといった方式を採用する組織はあまりないでしょう。
バッチ方式でのリリースの必要性についてはいったん脇に置いて、この方式のフローについて考えてみると、その効率の悪さに気づきます。カンバンボードを流れるチケットは、必ずリリースステージの待ち領域でせき止められます。すべてのチケットが揃うまで、いずれのチケットもリリースステージに入ることができません。リリース前に最終的なテストを一括で実施しているなら、テストステージの待ち領域でチケットがせき止められることになるでしょう。あきらかに、テストステージやリリースステージがフローのボトルネックになっています。

この問題を理解するには、カンバンボードを「開発」と「生産」に分けて眺めてみる必要があります。
開発と生産に分けて考える
カンバンボードで表現される開発プロセスは、「開発」と「生産」に分けることができます。本記事の前半で主に扱っていたコード実装ステージやコードレビューステージは、「開発」です。それ以降が「生産」で、バッチ方式リリースに関係するのは主にこちらです。

第1フェーズである開発に関連するタスクは、チケットごとに異なる内容であり、同一のタスクは存在しません。それ故、タスクごとに要する時間にもばらつきがあり、一定にはなりません。タスクの見積りも、このフェーズに要する時間を主な対象としています。また、このフェーズにあるチケットが一括で処理されることもなく、それぞれのチケットごとにフローが流れることが特徴です。
第2フェーズである生産に関連するタスクは、それぞれのチケットで扱う範囲が大きく重複します。例えばテストであれば、そのチケットで変更することになったコードだけをテストするのではなく、リグレッションテストも行われます。リグレッションテストは、テスト範囲が複数のチケットで重複します。このような重複による無駄なコストを避けるために、複数のチケットを一括で扱う傾向が強くなるのです。いずれにしても、ここで追求すべきは、製造業での生産と同様で、スピードと品質を高いレベルで一定に保つことです。
開発フェーズと違い、生産フェーズは、自動化技術が進んでいる領域です。ソースコードを実行可能な成果物に変換する「ビルド」はもちろん、テストやリリースもほとんどが自動化可能です。
この自動化が究極に進んだプロジェクトでは、コードレビューが終わったチケットが、自動でビルド、テストされ、リリース(デプロイ)されるようになります。バッチ方式ではなく、チケット単位でリリースまで進められるため、リードタイムが短く、フロー効率はとても高い状態になります。
現実のプロジェクトでバッチ方式でのリリースが行われる背景には、このような自動化が十分に進んでいないという理由があります。また、生産フェーズに必要な権限が開発チームに不足していることが自動化の足かせになっていることもあります。例えば、リリースに関係する重厚な承認プロセスがあるなら、そこで必ずフローは止まってしまいます。他にも、開発チームと運用チームが分離している組織では、開発チームがリリースをコントロールすることが難しくなるでしょう。
生産フェーズのこのような問題をどれだけ解決できるかが、フロー効率に大きな影響を与えています。生産フェーズのコストがあまりに高いと、「なるべく多くの機能を1度のリリースに含めたい」という意識が働きます。そのようなプロジェクトは、バッチに含めるチケットの数が多くなり、リリースは数か月に1度しか行われないといった状況に陥っているのではないでしょうか。
固定イテレーションでバッチのサイズをコントロールする
スクラム開発をはじめとする典型的なアジャイル開発手法では、短い固定のイテレーション(スプリント)の導入によって、バッチに含めるチケットの数が多くなり過ぎることを抑制し、リリース頻度を高めることを可能にします。このイテレーション期間を短く設定するほど、フロー効率は高まります。

このような固定イテレーションを導入しようとしたり、イテレーションをより短くしようとすると、フロー効率に関係する組織やプロセスの問題に気づくはずです。テストやリリースの実施コストがあまりに高く、長い期間がかかるようなら、短いイテレーションの導入など無理になるからです。こういった問題に気付くという点も、アジャイル開発手法導入による効果のひとつでしょう。
特に、アジャイル開発手法を導入した後は、イテレーション毎の振り返り(レトロスペクティブ)でフロー効率の改善について意見を出し合うことになるでしょう。そこでは開発フェーズだけでなく、生産フェーズの問題について話し合われることも期待できます。
補足ですが、スクラム開発がそうであるように、リリースは、イテレーションごとに実施するとは限りません。イテレーションの終了はあくまでも、そのイテレーションで対象としたバックログをリリース可能(デプロイ可能)な状態に仕上げることです。イテレーション終了から、実際にリリース(デプロイ)されるまでの期間をフロー上の待ち時間としてフロー効率を計測するかどうかは、プロジェクト次第です。
※バッチサイズについては、はてなブログに書いた記事『バッチサイズ削減はソフトウェアデリバリに何をもたらすか』でも深掘りしています。
生産フェーズの自動化でオンデマンドのリリースへ
改善を続け、生産フェーズの自動化が極まると、必ずしもバッチ方式でのリリースを採用する必要性が薄れてきます。個別のチケットごとにリリースすることが容易になるからです。それは、リリースのタイミングをイテレーションサイクルに合わせる必要性がなくなったことを意味します。
バッチ方式のリリースからオンデマンドのリリースに移行することで、フロー効率は一気に高まります。WIP制限やペアプロなどで待ち時間を徹底的に小さくした開発フェーズを終えたチケットの成果物は、生産フェーズで自動化されたプロセス(継続的デリバリー/継続的デプロイメント)を経てすぐにリリースされるのです。

生産フェーズの自動化では、そのパイプラインを止めてしまう障害を最優先で排除する必要があります。例えば、開発フェーズを終えて生産フェーズに入った最新コードが自動テストに通らなかったら、それ以降に生産フェーズに入った最新コードの自動テストはすべて不合格になります。生産フェーズを止めてしまったコード実装を担当した開発者は、別の仕掛中タスクがあっても手を止めて、テストに合格するようコードを修正すべきです。ちょうど、トヨタ生産方式の「アンドン」のようなものです。
ここまでくると、プロダクトバックログの優先順位付けが、その重要性をより増してくるでしょう。オンデマンドリリースに変わると、バックログの先頭にあるアイテムが必ず次に着手され、開発が完了次第、リリースされるようになります。
優先順位付けを怠ると、機会費用となってビジネスに悪影響を及ぼします。得られる価値を最大化するための優先順位付けが必要です。プロダクトバックログに並ぶアイデアは、リリースされて初めて価値を生み出すものだから、リリースが早ければ、ビジネスやユーザーが得られる価値は早くに得られます。逆に遅ければ、得られる価値は目減りします。

この課題に対しては、「WSJF(Weighted Shortest Job First)」と呼ばれる優先順位付け手法が有用でしょう。WSJFは、プロダクトバックログアイテムの開発期間見積りと遅延コストに基づいて、優先順位を表すスコアを算出するシンプルな手法です。遅延コストとは、例えばリリースが1日遅れることで失われるコンバージョンや、逆に高まってしまうリスクなどの規模を相対的に表現した数値です。
WSJFについて詳細を説明すると長くなってしまうためここでは割愛しますが、はてなブログに書いた記事『遅延コスト回避中心のPBIライフサイクルマネジメント』で詳細に説明しています。
実際には、オンデマンドリリース化が難しいケースもあります。特に、UIテスト(E2Eテスト)は自動化が難しく、人手によるテストが多く残りやすい領域です。また、モバイルアプリではAppleやGoogleによる審査もあります。そういったケースでは、適切なサイズでのバッチ方式の採用が現実的になるでしょう。
内部品質の悪化はフローを遅くする
フロー効率を悪化させる要因は、待ち時間の他にもあります。それは、コード品質をはじめとする内部品質の悪化です。
ある調査によると、コード品質が低いとされたコードは、コード品質が高いとされたコードと比べ、変更のために平均で2倍、最大で9倍もの開発時間がかかるという結果が出ています。これではフローは進むものの、そのスピードが落ちていることになります。それをフロー効率で表すなら、2倍の時間を要すれば50%、9倍の時間なら11%になります。

もちろん、1つのチケットが対象とするコードの全ての品質が一様に悪いとは限らないので、この計算はシンプルすぎます。しかし、コード品質がフローに与える影響を直感的に理解しやすいでしょう。
ソフトウェアの内部品質を高めることが、フローの観点でもいかに大切であるかがよく分かります。
現状に最適化された見積りは、内部品質の悪化によるフロースピードの低下も隠してしまいます。外部品質にばかり気を向けていると、気づかぬうちにフロー効率を悪化させることになるでしょう。
「生産性を高める」とはどういうことだろうか
フロー効率に焦点をあてると、「生産性を高める」という言葉の指す意味が変わります。開発者を「リソース」と見立て、彼らがどれだけ多くの仕事をさばいているかというメトリクスへの関心が薄れます。稼働率(リソース効率)がいくら高くても、フローが停滞し、進みが遅ければ意味がないことに気づくからです。
追求すべきは、フロー効率を高めてリードタイムを短くし、フローのスループットを高め続けることです。そうすれば、稼働率も自然と適切なレベルにまで上がります。それこそが、「生産性が高い」と呼べる状態でしょう。特に、生産フェーズ全体のリードタイムとスループットは、それぞれ「変更のリードタイム」「デプロイの頻度」と呼ばれ、その向上が、収益性や市場占有率といった観点での組織のパフォーマンスに影響するという調査結果もあります(書籍『LeanとDevOpsの科学』を参照)。「詰め込めるだけ詰め込んでしまえ」といったリリースを計画する悪習があるなら、捨て去ることをおすすめします。
※フロー効率についての詳細は、書籍『This is Lean』がおすすめです。
この記事が気に入ったらサポートをしてみませんか?