
ゲーム制作におけるマスタデータの構成について

この記事は「ゲームにかかわる人が自由な記事を作る Advent Calendar 2023」12月12日の記事です。
はじめに
ゲームには様々な数値や文字が登場します。
RPGやカードゲームであれば「HP」や「MP」など
アドベンチャーゲームであれば「キャラ名」や「好感度」など
アクションゲームであれば「移動速度」や「ジャンプ力」など
これらの数値や文字のうち、プレイ中、変化することのないデータ群、プレイヤーごとに変わることのないデータ群を「マスタデータ」と呼びます。
例えば、RPGのキャラで考えてみると、各レベルごとの「最大HP」はマスタデータです。
一方で「HP」はプレイ中ダメージを受けたり、回復をしたりすることによって変化していきます。なので現在の「HP」はマスタデータと呼びません。
もちろん「最大HP」だって成長値に振れ幅のあるゲームはありますよね? けれども、そのような場合でも「最大HP」はマスタデータなのです。なぜなら、振れ幅のあるゲームの場合は下記のように複数の「プレイ中変化することのないデータ(=マスタデータ)」が隠れているからです。
基準となる「最大HP」
成長の振れ幅の「最小値」「最大値」(または振れ幅の「±N%」)
ちなみに記事の中で「数値を調整する」「数値をいじる」といった言葉も出てきます。「プレイ中変化することのないデータ」の「数値を調整する」ってどういうこと? と思われるかもしれませんね。これは「プレイ中に」ではなく、それぞれ「開発期間中に数値を調整する」「開発期間中に数値をいじる」といった意味になります。開発期間中に「最大HP」を調整することは多々ありますので。
さて、今回の記事は、このマスタデータを僕がどういう構成で作成しているか、ということを記事にしていきます。一方で今回の記事で触れない内容もあるので、先にまとめておきます。
<今回の記事の内容>
・とぶがどういう構成でマスタデータを作成しているか
<触れない内容>
・マスタデータのコンバート方法
→エンジニアさんの方がずっと詳しいです
・マスタデータの構成の正解、最適解
→なにそれわかりません
・大規模ゲーム開発やソーシャルゲームのマスタデータ運用法
→我、ただの個人開発者なので……
また、記事ではあれこれ専門用語も入ります。後半やや難易度が上がっていきますが、用語の意味を知らなくても(多分)ある程度読める内容になっているので、特に一つひとつの用語について解説はしません。
では、はじめましょう!
マスタデータはソースコードに埋め込まない
小規模なゲームであれば、下記のようにソースコードに直接マスタデータを埋め込む場合もあるでしょう(いや、ないか)
private int maxHp = 5;
// 以下略この方法では規模が大きくなるにつれ、色々と支障が出てきます。
<色々と出てくる支障>
データを変更するたびにビルドをしなければいけない
データを変更するたびにソースコードの変更履歴が更新されていく
プログラムの知識がない人がマスタデータを調整する場合、数値の変更をエンジニアさんにお願いしないといけない
エンジニアさんがマスタデータ管理を兼ねるようになる
埋め込んだ数値がマジックナンバー化する
環境の変化に対応しづらい
「環境の変化に対応しづらい」について補足します。これは例えば下記のようなことが考えられます
「サーバーからマスタデータをダウンロードするようにしたい」と言われた時に対応しづらい
「イベント版のマスタデータとリリース版のマスタデータを分けたい」と言われた時に対応しづらい
このように様々な問題があるため、まずはソースコードからマスタデータを分離しましょう。
【Unity】インスペクターで数値をいじれるようにするのはあり?
Unityで開発する小規模なゲームであれば、インスペクターでマスタデータの数値をいじれるようにする方法もあるでしょう。
もし「Unityで1週間でゲームを作るイベント」みたいなイベントがあった場合、この方法で十分対応できそうです。
そして、なんと!? 調べてみたら来週「Unityで1週間でゲームを作るイベント」があるらしいですね!! ビックリ!
【Unity】ScriptableObjectで数値をいじれるようにするのはあり?
Unityで開発するゲームであれば他に、ScriptableObjectでマスタデータの数値をいじれるようにする方法もあるでしょう。
ScriptableObjectは魅力的な選択肢の一つです。Play Mode実行中にいじったデータはPlay Mode終了時も保持されるので、テストプレイをしながら数値を調整するのに向いています。
ただ、「インスペクター」も「ScriptableObject」も共に規模が大きいデータ群だと扱いにくくなる傾向があります。扱いにくくなる、というのは主に下記のようなケースが発生するためです。
データを俯瞰して見られない
データを一括して変更できない(多分)
そこで今回は次の方法を紹介します。
スプレッドシートによるマスタデータ管理
僕はある程度以上の規模のゲームになるとスプレッドシートでマスタデータを作成します。エクセルとスプレッドシートの違いはほぼありませんが、スプレッドシートのGAS(Google Apps Script)の方が使い慣れているので個人制作の場合はスプレッドシートを使っています。スプレッドシートのデメリットとしては、googleさんで障害が発生した場合、作業に支障が出るというデメリットがあります。滅多にないですけれども。
僕の場合はスプレッドシートでマスタデータを設定した後、json形式に出力できるようにしています。そして、出力したjsonをゲームに使用しています。……と、何を言っているのかわからない場合は、スルーして大丈夫です。必要になった時に調べてみてください。
スプレッドシートのメリット
スプレッドシートのメリットは下記のようなものがあります。
データを俯瞰して見られる
データを一括で変更できる
分業できる
「データを俯瞰して見られる」というのはマスタデータを調整する人間として大きなメリットです。そこでまずは「データを俯瞰して見られる」というメリットから説明していきます。
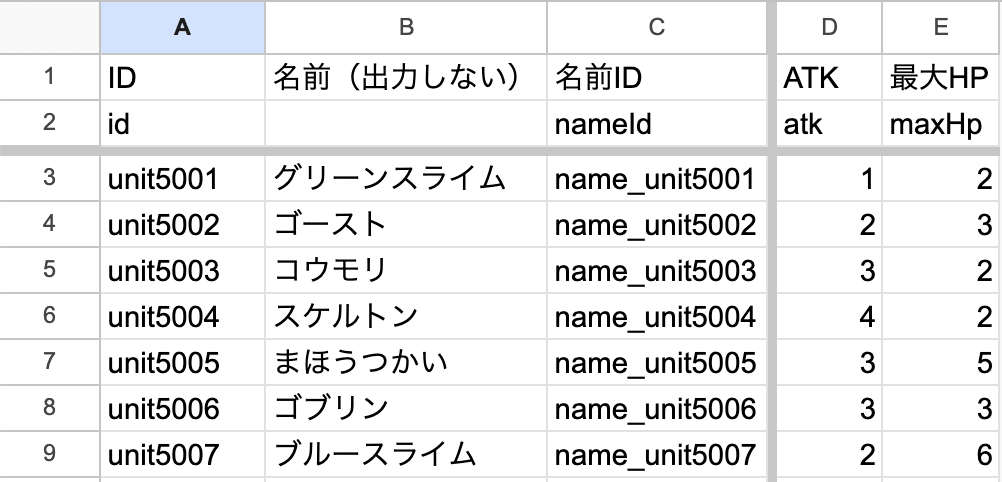
メリットその1.データを俯瞰して見られる

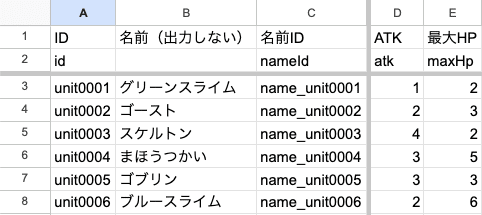
スプレッドシートだと、上の表のようにデータが並ぶんですね。スプレッドシートのフォーマットは自由です。なので、これはあくまで僕がマスタデータを設定する際のフォーマットの説明になりますが、1行目は調整する人間が一目で見てわかる名前をつけています。2行目はプログラム側で実際に読み込む名前。3行目以降はパラメータです。
余談ですが「最大HP」を今回「maxHp」と名付けましたが、マスタデータ上、単に「hp」と名付けることも多いです。マスタデータ上の「hp」というのは「最大HP」を指すことが明白なので。
ところで、こうして並べてみると「あれ? おかしくない?」というデータに気づくのです。例えば先ほどあげた表で明らかに「倒した時の報酬が低い敵」がいます。誰でしょうね? 順に考えてみましょう。
この謎ゲームの敵は全て「atk」「maxHp」で強さが決まっており、報酬は全て「exp」「gold」しかないとします。
敵の強さや報酬をどう評価するかは調整する人の方針によりますが、ここで強さの評価を「atk」と「maxHp」の合計値とします。そして、報酬の評価を「exp」と「gold」の合計値とします。強さ、報酬の評価値を表に加えてみましょう。

F列、G列に強さ評価と報酬評価を加えました。ふむ……何となく割に合わない敵が浮き上がってきましたが、このままだと数百体敵がいた場合見落としそうですね。
では、H列にもう一つ「報酬評価➗強さ評価」で計算する「報酬比率」の列を加えてみましょう。ついでに条件付き書式で報酬比率の数値を評価してみます。

おやおや、ゴブリンさんの数値が明らかに低いですね。これは他の敵と比べてもらえる報酬が半分以下である、ということを示しています。特別な意図がない限りは強さか報酬を見直した方がいいでしょう。
このようにデータを俯瞰で見られるのがスプレッドシートの大きなメリットです。
ちなみに今回強さを評価するためF〜H列を加えましたが、エンジニアさんと共同で開発している時に勝手にこういう列を加えると怒られます。謎のエラーが発生することだって考えられます。エンジニアさんとの共同作業の場合、列を追加したい時は事前にこういう列を追加していいか相談しましょう。そして列の追加が無理なら別のシートやドキュメントでパラメータを評価するようにしましょう。
僕は、2023年現在個人で開発していますし、2行目が空の行はjsonに出力しない(ゲームに読み込まない)ようにしているので、好き勝手にこういう列を加えられるのです。
さて、データを俯瞰で見られるメリットについて、何となく伝わったでしょうか? 続いて、「データを一括で変更できる」メリットについて説明していきますね。
メリットその2.データを一括で変更できる
データを一括で変更できるのもメリットです。スプレッドシートであれば例えば「最大HPを一括で1.5倍にしたい」といった時にプログラム側で数値をいじる(←マジックナンバーになるのでお勧めしません)必要はなく、スプレッドシート側で数式(=ROUNDDOWN(⚪︎⚪︎*1.5))を書いて数値を変更すればいいので楽です。
最後にスプレッドシートのメリットとして「分業できる」というメリットについて説明します。
メリットその3.分業できる
「スプレッドシートをうまい具合に分割しておくと」様々な人と分業できます。
調整する人とエンジニアさんとで分業できる
調整する人同士で分業できる
調整する人とその他の職種の人と分業できる
スプレッドシートに分割した時点で、ソースコードを書くエンジニアさんと分業できているため、エンジニアさんと分業できることについては説明を飛ばします。
調整する人同士で分業できる。これは例えば、Aさんが敵のデータを編集している間に、Bさんがアイテムを編集する、ということができるという意味ですね。
その他の職種の人と分業する。これは例えば、Aさんが敵のデータを編集している間に、Cさんが敵の名前を英訳する、といったことができるという意味です。
分業するにはファイルを分けたり、シートを分けたりすると良いでしょう。
ファイルの分割
マスタデータというのは、ファイル分割やシート分割をしないとみるみるデータが増えて可読性が悪くなっていくものです。例えば、1シート数千行のデータが出来上がったり、1ファイル数十シート、シートが連なったりすることもあります。そうするとマスタデータを開くたびにどこに何があるのか探すところから作業が始まるので疲れてしまうでしょう。そうならないためにもファイルを分割しましょう。
ファイル分割は「関連性の低いもの」や「担当する職種の異なるもの」単位で分けるのが良いでしょう。例えば、「敵の強さを設定するデータ」と「敵名の海外版を設定するローカライズ用のデータ」はそれぞれ担当する職種が異なるものですので分けてみます。

敵の強さを設定するファイル

敵名のローカライズ用ファイル
おっと、突然内容が難しくなりましたね! でも心配しないでください。順を追って説明します。
IDを振ろう
ファイルやシートを分けた時、あるいはプログラムでマスタデータを読み込む時、IDを振る必要が出てきます。IDを振ることによって、ファイルが分かれていてもデータを関連づけることができるようになるのです。
例えば、ファイル「enemy_unit」の中で設定されている「unit0003」のIDを持つ敵は「name_unit0003」という名前IDを持っています。この敵の日本語名を知るためには、「localize_enemy_unit」の中で設定されている「name_unit0003」の「japanese」列を見れば良いのです。すると「スケルトン」という名前の敵であることがわかります。
え? 面倒くさくない? ファイルを分けなくて列を増やせば良くない? と思われるかもしれないですが、10言語同時リリース! みたいなことをし始めたりして列を増やしていくとどんどん列が増えていくので(←それはそう)可読性が落ちていくのですよね。
IDだけだとどのデータをいじっているのかわからなくない? といった意見も出そうです。これには解決方法があって、僕は2行目が空の行はjsonに出力しない(ゲームに読み込まない)ようにしているので人が識別するための列を1列追加してあげれば良いのです。
B列に作業者確認用の列追加
IDについては、数値か文字列かどちらが良いか、といったこともあると思います。サーバーエンジニアの方はおそらく数値の方が好みではないでしょうか? 一方で僕は文字列でIDを振っています。検索で見つけやすいので。また、文字列であれば、下記のようなID名から用途を判別できるようなIDの振り方もできますので。

僕の好みはさておき、IDを数値でつけるか文字列でつけるかについては、エンジニアさんとよく話し合って決めるのが良いと思います。
シートの分割
さて、先ほどまでファイルの分割について説明してきました。ところで、ファイルを分割せずにシートを分割するケースはどういったものが考えられるでしょうか? 一つの方針として「関連性の高いもの」についてはファイル分割ではなくシート分割するという方針があります。
例えば、これまで紹介してきた敵のデータ。敵のデータがあるということは、プレイヤーのデータもありそうですよね? 試しにひとつのシートにプレイヤーのデータも足してみましょうか。
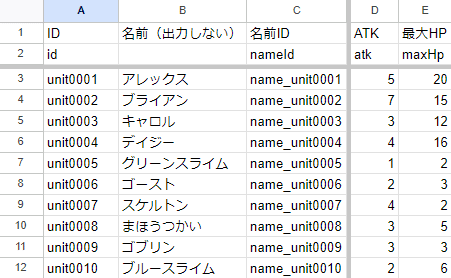
unit0004までがプレイヤーのデータ
うーん、わからん。どこまでがプレイヤーのデータでどこからが敵のデータかわかりにくいですね。
でも、関連性はとても高い。なんたって、持っているデータが同じなのですから。こういう時はファイル分割ではなく、シート分割の方が良い場合が多いです。試しに分割してみましょう。ついでにプレイヤーのIDと敵のIDも分けてみましょう。
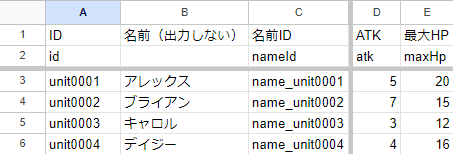
シート名「unit」
プレイヤーのデータ
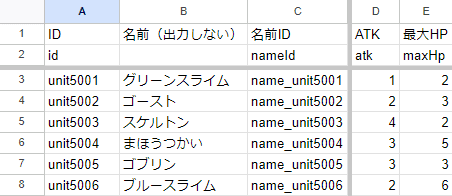
シート名「unit[2]enemy」
敵のデータ
ファイル名、シート名はなんでもいいのですが、一例として名前をつけてみました。シート名に「[n]」といった名前がついてたらjsonを結合するみたいな実装になっている例ですね(なんのことかわからない場合はスルーして大丈夫です)
また名前IDの方は端折ってますが、unitのデータと同じようにシート分割しています。
とにもかくにもこれで敵のデータとプレイヤーのデータを管理しやすくなったのではないでしょうか?
IDもプレイヤーは1番から、敵は5001番から振っているので、例えば第五のプレイヤーエンリュウを出したい! みたいな時も対応が楽そうです。
並び順の話
ところで敵キャラのコレクション画面を作りたい場合、敵を登場順に並べて表示するには、どうマスタデータを制作すれば良いのでしょうか?
基本的には敵のマスタデータのIDは制作者の意図した並び順に並べていくのが良いと思っております。
例えば、開発途中でゴーストとスケルトンの間にコウモリを加えたい、と思った場合も出てくるでしょう。その場合は、開発序盤であれば(あまりやりたくないですが)IDを振り直すのも選択肢の一つです。
名前IDや他のIDもズレるので気をつけて
ただ、開発終盤になって敵キャラが300体います、という状況でIDを振り直すと少々面倒です。特にIDと敵キャラの画像ファイル名が紐づけられていた場合などはファイル名も変更しなおさないといけないです。そういったことが起きないようにIDは歯抜けで数値を振っておくのも手です。

↑の例は少々やり過ぎ感はある
こうしておけば例えば、ゴーストとスケルトンの間にコウモリを加えたい、と思った場合「unit5025」などのIDでコウモリを加えれば済みます。
ただ、ここまで話しておいてなんですが……何かしらの順番で並べたい、という場合、並び順(ソート順)用の列を一列追加した方が色々と便利です。

こうすることによって柔軟に並び順の調整ができますし、「-1」が振られている敵はコレクション画面で表示しないといった対応も取れます。
その他補足
ここまで読んでいただいた方、ありがとうございます。大分長くなってしまったので、残りは駆け足で補足をしていきますね。
経験値とゴールドの設定はどこへいった?
これについては報酬マスタというマスタが別にあると考えてください。
マスタ制作で気をつけることは?
一つの列に複数の意味を持たせないのが良いです。これについては少々説明が難しいので補足します。例えば、マスタデータの中で複雑になりがちな魔法効果。

マスタ上では上の表のようにvalueに魔法の効果量が設定されているものとします。実際は対象範囲設定やエフェクト設定なども必要ですが、端折ります。上の表は一見問題ないように見えますが、仕様では下記の挙動になることを想定しているものとします。
「magicType」が「1」であれば「valueポイント傷が回復する」
「magicType」が「2」であれば「nターンの間、対象のターン開始時に最大HPのvalue%ダメージを与える」
「magicType」が「3」であれば「対象をvalueターン眠らせる」
「対象のターン開始時の定義ってなんだ?」とか仕様が不正確であることは目を瞑ってください。兎にも角にもここで注目すべきは2つ。
「効果量」を表す「value」の中に「%」や「ターン数(turn)」まで含まれてしまっていること
マスタデータ設定に必要な列が抜けていること
こういった時は「効果量」「効果率」「ターン数」の列を作成した方が良いでしょう。一方で「valueポイント傷が回復する」「valueポイントATKをあげる」「valueポイントダメージを与える」と数値の意味が「効果量」を表す場合は、素直に「効果量」の列に数値を入れて問題ありません。
……と、補足のはずなのに説明が長くなってしまいましたっっ!!
まとめ
いかがでしたでしょうか?
今回は僕がマスタデータを作成する時にどういった構成でマスタデータを作成するのかといったことをざっくりと説明してみました。
僕もマスタデータに精通しているわけではないので、あまり良くない方法でマスタデータを作成していたり、誤ったことを書いていたりする場合もあるかもしれません。そのような場合は石を投げないでっ。生暖かく見守っていただくか、こっそり優しく指摘してください。
ではでは! 今回の記事が誰かのお役に立つことがありましたら嬉しいです。