
ChatGPT勉強日記(#7) Embeddingsで生成したベクターデータの視覚化

某月某日、
弊社のベトナムチームに、EmbeddingsなどのOpen AIの機能を説明しようと思ったのだが、ベクター化したデータが一体何なのか口で行ってもなかなか伝わらないかもしれないと思った。
word2vecなど元々自然言語処理や自然言語を扱うニューラルネットワークを扱ったことがある人であればすぐにしっくりくると思うが、そうではない人にはベクター化という行為はイメージがしづらい。
少しでも伝わりやすい方法はないかと思っていたところ、OpenAI cookbookに以下のサンプルを見つけた。
https://github.com/openai/openai-cookbook/blob/main/examples/Visualizing_embeddings_in_3D.ipynb
OpenAIのEmbeddingsの機能で文章をベクターデータにしてもらうと、1536次元の浮動小数点数の配列として返ってくる。
1536次元もあるので、この生データを見せても???という感じでしっくりこない。このサンプルのように思い切って3次元で見せたほうが良いかもしれないと思い、自分なりのサンプルを作ってみた。
まず、wolf, monkey, whale, dogという4つの動物の”文字列”を含んだ配列を作る。
import openai
import pandas as pd
# List of animals
animals = ["wolf", "monkey", "whale", "dog"]
# Calculate embeddings for each animal
embeddings = [
openai.Embedding.create(input=animal, engine='text-embedding-ada-002')['data'][0]['embedding']
for animal in animals
]
# Create a DataFrame with animals and their corresponding embeddings
df = pd.DataFrame({
'name': animals,
'embeddings': embeddings
})
df.head()(注:openai, pandasのモジュールをpipで先にインストール必要があります)
次にそれぞれの単語をEmbeddingsを使って、ベクターデータにし、wolf, monkey, whale, dogという動物の名前とセットでDataFrameに格納しておく。
格納したembeddingsデータをPCAをつかって3次元のベクトルに圧縮して、DataFrameに"embed_vis"という名前で格納しておく。
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
vis_dims = pca.fit_transform(embeddings)
df["embed_vis"] = vis_dims.tolist()(注:sklearnモジュールをpipで先にインストール必要があります)
PCA(Principal Component Analysis)というsklearnライブラリの機能をつかってベクターデータの次元を1536から3次元に削減する。
PCAはベクターデータの全次元のデータを見て、各データどうしでもっとも値が違う次元(特徴)を3つ探して、その次元だけのベクトルを生成する。
このデータをpyplotをつかって3次元空間にプロットする。
%matplotlib widget
import matplotlib.pyplot as plt
import numpy as np
fig = plt.figure(figsize=(10, 5))
ax = fig.add_subplot(projection='3d')
cmap = plt.get_cmap("tab20")
# Plot each sample category individually such that we can set label name.
for i, animal in enumerate(animals):
sub_matrix = np.array(df[df["name"] == animal]["embed_vis"].to_list())
x=sub_matrix[:, 0]
y=sub_matrix[:, 1]
z=sub_matrix[:, 2]
colors = [cmap(i/len(animals))] * len(sub_matrix)
ax.scatter(x, y, zs=z, zdir='z', c=colors, label=animal)
ax.set_xlabel('x')
ax.set_ylabel('y')
ax.set_zlabel('z')
ax.legend(bbox_to_anchor=(1.1, 1))(注:matplotlib, numpyモジュールをpipで先にインストール必要があります)
すると、dog、monkey、whale、wolfのベクトルデータは下のようにプロットされた。

whaleが右の離れたところにいて、dogとwolfが比較的近いところにいることがわかる。
これを見るとOpenAIのモデルがそれぞれの動物の名前をどのように把握しているのか、イメージが膨らむだろう。
ただ、PCAは与えられたデータの各次元の値を単体で比べて大きな差があるものを3を選んでいるだけなので、このように3次元空間にプロットしたときに常に自分の直感と同じような分布になるとは限らない。
例えば、上の動物のリストにlionとcatを追加して、ベクターデータを生成しプロットしてみると下のようになる。
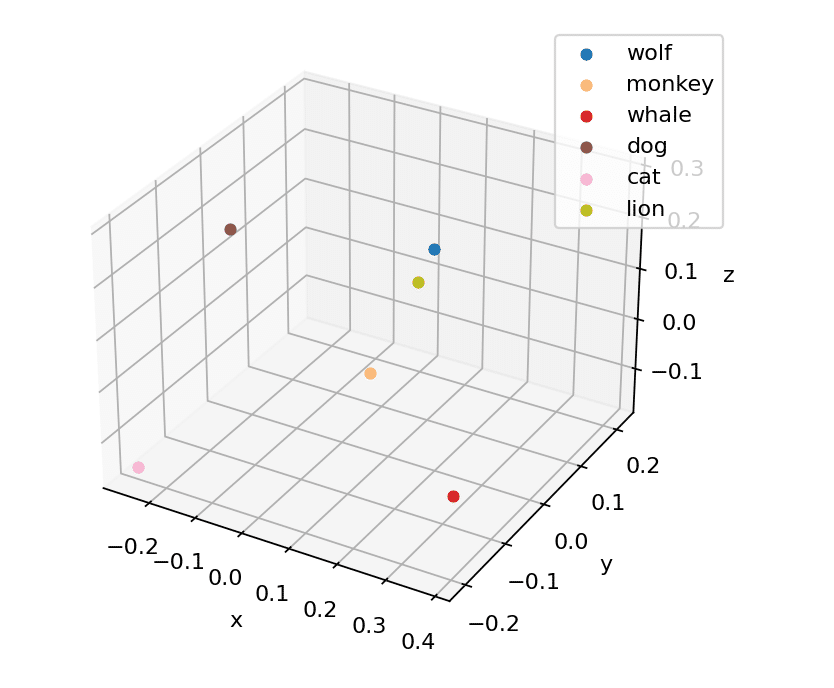
catとlionは近いのかなと思いきや、catは左下の端っこにいて、wolfとlionが近いところにプロットされている。今回はdogはwolfからは少し離れてしまった。
dogとwolfが離れた理由は、今回のcatとlionを追加したデータセットのなかでPCAが選んだ次元が前回選んだ次元と違うということの証である。
このように、1536次元の特徴から、3つを選んでプロットしているので、必ずしももともとの1536次元のベクターデータどうしの距離、”近さ”を正しく反映しているようには見えないこともある、というところに注意が必要だ。(ベクター同士の距離は前回でてきたコサイン類似度などの計算を使って求めるのが正確なやり方である)
ただEmbeddingsでベクターデータ化したものはどういうものなのかを説明するのに、このVisualizationは使えそうだなと思った。やっぱりグラフィカルに見えると楽しいし、「おぉ、犬と狼、やっぱり近いじゃないか!」のような喜びもある。
これを使って弊社のベトナム法人のメンバーにもうまく伝わったらいいな。。
調子にのって、第4回で扱ったIDEOの人間中心設計の講義資料のベクターデータも同じ方法でプロットしてみた。
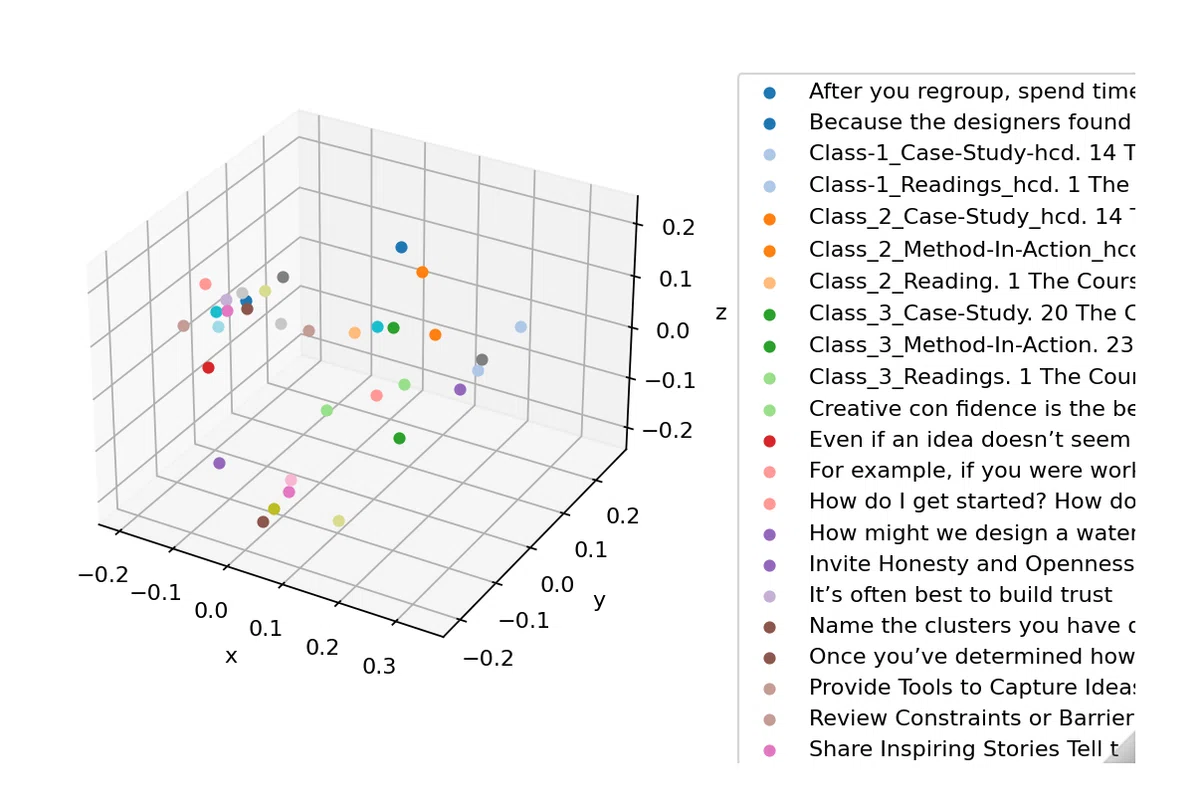
動物の名前のときのように、1つ1つを直感的に比べたりするのは難しいなと思ったが、データのばらつきを見るのに良いかもしれないと思った。多様なデータを集めたと思っていたが実は変な偏りがあった、などを見るのに良いかもしれない。
実際には他の統計的な計算でばらつきを見たほうが正確だが、ばらつきに問題があることを統計の知識のない人にプレゼンするときなどは上のように3次元にプロットして、「ほら、なんか偏ってるでしょ?もうちょっとデータ集めたほうがいいですよね?」と伝えればすぐに分かってくれるかもしれない。
続く。
このブログに関する質問や、弊社(Goldrush Computing)への開発案件の依頼は↓↓↓からお願いします。弊社では現在、OpenAI APIを使った高度なドキュメントや文字列情報を扱ったシステムの開発に注力しております。
mizutori@goldrushcomputing.com
この記事が気に入ったらサポートをしてみませんか?