
【2/17-2/24】生成AIツール/研究-Weeklyまとめ

今週のAIに関するツールや研究情報をまとめた記事です。
ツール
・perplexity.aiに新しい編集機能が追加
ソースを追加したり、無関係なソースを削除することによって、答えを編集することができるように。
Introducing a new editing tool for https://t.co/ut3wdOwUEd: you can now edit answers by either adding sources for more perspectives or deleting irrelevant sources. With just a few clicks, you can add context, remove incorrect information, and curate trustworthy answers: pic.twitter.com/4FU8xFxSxj
— Perplexity AI (@perplexity_ai) February 15, 2023
・ターミナル版Github Copilot
シェルコマンドを自動補完したり、テキストから生成したりできる
・部分指定して画像編集できるInstruct X-Decoderのhugging faceデモ https://huggingface.co/spaces/fffiloni/x-decoder-video


・3Dキャラクターアニメーションがより簡単に
テキストプロンプトだけでゲームに適したアニメーションキャラクターを作成することができるように
https://masterpiecestudio.com/blog/announcing-generative-animations…
✨ 3D character animation just got a lot easier. ✨
— Masterpiece Studio (@withMPStudio) February 16, 2023
Our Generative AI now lets you create game-ready, animated characters with nothing more than a text prompt.
Learn more: https://t.co/xP5EkzKwGj pic.twitter.com/1ZONw0Oodm
・キャラクター、スタイル、シーンを崩さずAIで動画の表現を変換ができるオープンソースツールが開発中
http://Banodoco.ai
キャラクター、スタイル、シーンを崩さずAIで動画の表現を変換ができるオープンソースツールが開発中らしいですhttps://t.co/ymMWfewaxq pic.twitter.com/uB0dGH6dar
— やまかず (@Yamkaz) February 17, 2023
・自律的にAPIを呼び出し情報を得るToolformerを、微調整なし、Zero/Few-shotプロンプトで再現した「Toolformer zero」が公開 http://toolformerzero.com
https://github.com/minosvasilias/toolformer-zero
すごい!!
— やまかず (@Yamkaz) February 19, 2023
自律的にAPIを呼び出し情報を得るToolformerを、微調整なし、Zero/Few-shotプロンプトで再現した「Toolformer zero」が公開https://t.co/DdtH48FTjyhttps://t.co/s0eXVoOMlTpic.twitter.com/QvQy05RKcu
・Self-Attention Guidanceを使用した拡散モデルのサンプル品質の向上
既存の拡散モデルのパフォーマンスを大幅に向上させることができる、プラグアンドプレイの拡散ガイダンスを提案
デモ: https://huggingface.co/spaces/susunghong/Self-Attention-Guidance

・Masterpiece Studioによるtext to 3D/アニメーション
誰でもゲームやその他の 3D アプリケーション用のゲーム対応の 3D モデルやアニメーション キャラクターを作成可能
https://buff.ly/3XL8Y4V


・3秒の録音で自分の声を生成できるAIボイスサービス
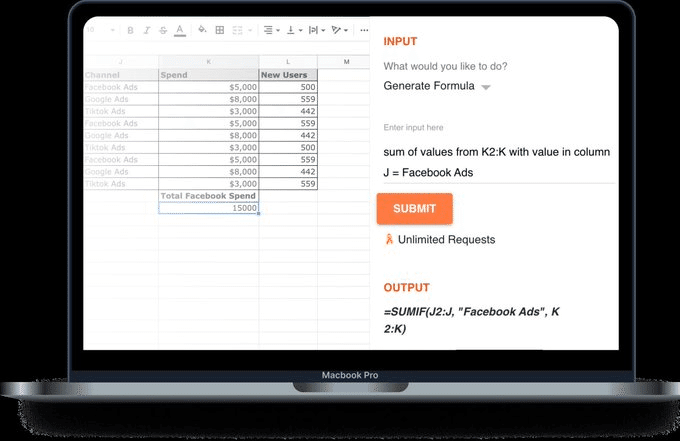
・Excelの関数などをテキストから生成できるFormulaGenerator
チューニングされたGPT モデルを搭載した無料のAIツールを使用して、Excel の数式、VBA 自動化、正規表現、さらには SQL クエリを簡単に生成できる
https://formulagenerator.app
・構成やスタイル等をstable diffusionより詳細にコントロールできるAttend-and-Excite がdiffuserで簡単に利用可能に https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/attend_and_excite

・maskやboundingboxでコントロールできたり、パノラマを含む任意のアスペクト比での画像生成が可能なMultiDiffusionがdiffuserに統合
今は、text2panoramaがサポートされ、maskやboundingboxによるコントロールは間も無くとのこと
デモ: https://huggingface.co/spaces/weizmannscience/MultiDiffusion…
リポジトリ: https://github.com/omerbt/MultiDiffusion
Excited to share "MultiDiffusion"!
— Omer Bar Tal (@omerbartal) February 17, 2023
A controlled image generation framework w/ pre-trained text-to-image diffusion model.
* Spatial guidance controls (bounding boxes/masks)
* Arbitrary aspect ratios (huge Panoramas!)
NO training NO finetuning.
[1/3]@YarivLior @lipmanya @talidekel pic.twitter.com/sqeQda4FnQ
・社内のビジネスナレッジをChatGPTライクに質問できるGetAnswer
チームやカスタマーサポート担当者が必要な情報にすばやく簡単にアクセスできる https://getanswer.ai

・AIブックリーダーを開発中とのこと
本をアップロードし、質問をして、関連するセクションと一緒に回答を得るだけで、詳細を読むことができる 今週後半にベータアクセスの提供を開始予定
I am building an AI book reader 📖. Just upload your books, ask questions and get answers along with relevant sections to read more.
— Prasann Pandya (@prasann_pandya) February 21, 2023
Interact with this tweet to get early access. I will start giving beta access later this week! #AI #books #reading pic.twitter.com/q3WqU0tRnQ
・ヘルプセンターの記事から回答を引き出すチャットAIのOpenSight
ヘルプセンターの上に単なる検索エンジンを載せるのではなく、企業向けのセキュリティ担保や、チケットにデータの確認や対処が必要かどうかを理解し、解決までを正確にマッチング Yconも支援
https://opensight.ai

・HuggingFace Spaces でFROMAGE を試せるように
FROMAGE は、画像とテキストの入力を処理して画像とテキストの出力を生成できるモデル
https://huggingface.co/spaces/jykoh/fromage…
https://jykoh.com/fromage

・テキストからビデオ生成のTune-A-Videoに、一貫性の向上のための新しい更新が追加
トレーニング: https://huggingface.co/spaces/Tune-A-Video-library/Tune-A-Video-Training-UI…
推論:https://huggingface.co/spaces/Tune-A-Video-library/Tune-A-Video-inference
Tune-A-Video: One-Shot Tuning of Image Diffusion Models for Text-to-Video Generation
— AK (@_akhaliq) February 22, 2023
New update: Improved consistency using DDIM inversion@Gradio demo training: https://t.co/bI3fBY8J4z
Inference: https://t.co/B1XlD1h4Ii pic.twitter.com/nEFD5ZUNAz
・最新のAIを使用して開発する 30,000 人を超える開発者コミュニティ https://lablab.ai

・すぐに使用できるコンバージョン率の高い広告クリエイティブとソーシャル メディア投稿クリエイティブを数秒で生成
https://adcreative.ai

・Fathom
Zoom 通話を記録、文字起こし、要約、通話のハイライトをメールや Slack でチームと簡単に共有できる。 また、CRM、Google ドキュメント、または Notion への通話後のデータ入力を自動化。
Fathom
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) February 23, 2023
Zoom 通話を記録、文字起こし、要約、通話のハイライトをメールや Slack でチームと簡単に共有できる。
また、CRM、Google ドキュメント、または Notion への通話後のデータ入力を自動化。 pic.twitter.com/WLHn4r65BV
・テキストから複数画面のデザイン生成
ただデザイン画像生成じゃなくて編集も出来てる? まだリリースはしてないけど、本当なら試してみたい。
Uizard Autodesigner ウェイトリスト: http://uizard.io/autodesigner/
The secret is out 👀
— uizard ✨ (@uizard) February 22, 2023
Generate a multi-screen UI design from a single prompt with Uizard Autodesigner.
Want to be the first to try Uizard's new, groundbreaking technology? Head to https://t.co/jXd4S1kheg to sign up for exclusive access.
✨ coming soon ✨#uizard #generativeai pic.twitter.com/qAevbRR8IV
・VRで思い出を追体験できるアプリ「Wist」の体験映像
http://WistLabs.com
!?!これやば
— やまかず (@Yamkaz) February 24, 2023
VRで思い出を追体験できるアプリ「Wist」の体験映像https://t.co/U3Vb63rqOupic.twitter.com/2Yn1HYJP3w
・ウェブ上でのフルボリュームのリアルタイムでフォトリアリスティックなNeRFレンダリング
✨ Today we are ready to take AI Graphics to the next level: full volumetric photorealistic NeRF rendering on the web. All in realtime!
— Luma AI (@LumaLabsAI) February 23, 2023
What you see is what you get for photorealistic 3D is finally here!
Starting with the the Fields Editor soon you’ll be able to reshoot in… https://t.co/M5qPE21MRy pic.twitter.com/ywkTdEVdyT
・decktopus: テキストスライド生成
-画像とアイコンの提案
-トピックと聴衆に合わせて調整されたスライドノート
など様々な機能も完備
他との違いは、プレゼンテーションアシスタントとしての機能とのこと
https://decktopus.com/?ref=producthunt
・Raycast Mac上どこからでもGPTを使える
ショートカットコマンドも設定できてかなり便利そう
waitinglist https://raycast.com/ai#join-waitlist

・Yvonも支援するスタートアップ向けの AI を活用した簿記および財務モデリング
GPT-3 を使用して会計をより簡単かつ正確にする。
研究
・AutoBiasTest バイアスをテストするための文を自動的に生成する手法
バイアスが入ったネットデータやクラウドソーシングによるデータから学習された言語モデルはバイアスが入ってしまう問題の対策として https://arxiv.org/abs/2302.07371

・テキストガイド付き画像編集
論文: https://arxiv.org/abs/2302.07979

・3Dを考慮した条件付き画像合成
プロジェクト: https://cs.cmu.edu/~pix2pix3D/
レポ: https://github.com/dunbar12138/pix2pix3D…
論文: https://arxiv.org/abs/2302.08509
3D-aware Conditional Image Synthesis
— Aran Komatsuzaki (@arankomatsuzaki) February 17, 2023
proj: https://t.co/ATbYzN9e4A
repo: https://t.co/9ufGcGMaTp
abs: https://t.co/ED2IwCDSok pic.twitter.com/4x49G49Z1Q
・拡張言語モデルのサーベイ論文
abs: https://arxiv.org/abs/2302.07842

・T2I-Adapter
テキストから画像への拡散モデルにおいて、より制御可能な能力を引き出すためのアダプタの学習
abs: https://arxiv.org/abs/2302.08453
github: https://github.com/TencentARC/T2I-Adapter

・pix2pix3D 制御可能なリアルな画像の合成のための 3D 認識条件付き生成モデル
セグメンテーションやエッジマップなどの 2D ラベル マップが与えられると、モデルはさまざまな視点から対応する画像を合成
論文: https://arxiv.org/abs/2302.08509
プロジェクト: https://cs.cmu.edu/~pix2pix3D/
3D-aware Conditional Image Synthesis
— AK (@_akhaliq) February 17, 2023
abs: https://t.co/0t97dhvC4t
project page: https://t.co/AqXSiyiYdV pic.twitter.com/CIvjxL9PQr
・Conservation AI と呼ばれる英国を拠点とする非営利団体は、Nvidiaの力を借りて、センザンコウ、サイ、その他 50 種以上の絶滅危惧種に対する脅威をリアルタイムで検出。 https://blogs.nvidia.com/blog/2023/02/16/conservation-ai-detects-threats-to-endangered-species/
Conservation AI と呼ばれる英国を拠点とする非営利団体は、Nvidiaの力を借りて、センザンコウ、サイ、その他 50 種以上の絶滅危惧種に対する脅威をリアルタイムで検出。https://t.co/o9f3EOrrgI pic.twitter.com/85hipCAuYy
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) February 17, 2023
・言語モデル ×化学適用論文
GPT-3に化学の質問を試したところ、専用に開発されたモデルより正しく答えられた。分子の相関関係を発見も可能。
https://doi.org/10.26434/chemrxiv-2023-fw8n4

・画像生成の制御手法の横断的なレビュー
・GLAZE: ぱっと見にはわからない変更を画像に追加することで、Stable Diffusion などの拡散モデルを用いたスタイルの学習/模倣を困難にする仕組み
https://buff.ly/3kdkCbd
[Paper] アーティストの権利を守るための試み。GLAZE: ぱっと見にはわからない変更を画像に追加することで、Stable Diffusion などの拡散モデルを用いたスタイルの学習/模倣を困難にする仕組み https://t.co/PNvo0RGfCy pic.twitter.com/LS8QAOZg5T
— Create with AI (@createwithAI) February 19, 2023
・スキルローカライゼーション: 言語モデルのどこに新しく学習したスキルが存在するのか
学習済みモデルを調整することで、95%以上の学習効率を実現する0.01%のパラメータを特定
-再学習せず40%-90%の誤差削減
-分布外予測で改善
-重複はタスクの類似度で対応領域が分布
論文:https://arxiv.org/abs/2302.06600

・IBMによる、コード言語モデルによる対話型インタラクション
-ほとんどのコード用言語モデルはUIやコンテキストがない
-提案するprogrammer's assistantは、コードに基づいた会話を探求
-長時間の対話が可能
-生産性を向上させる可能性があることにユーザーが高評価
論文: https://arxiv.org/abs/2302.07080

・numpyを使った60行でのGPT実装
Github: https://github.com/jaymody/picoGPT

・動的Nerfの新しい学習方法の提案
学習済みモデルのレンダリング品質を維持しながら、ニューラル ネットワーク モデルと比較して 100 倍以上高速
論文: https://arxiv.org/abs/2302.09311
project: https://sungheonpark.github.io/tempinterpnerf/

・Webデータセット汚染
昨今の基盤モデルで学習に使われているWebクロールデータセットへ、意図的に悪意のあるデータを差し込むデータ汚染に関しての研究 LAION-400M のようなデータセットの 0.01% をわずか 60ドルで効果的に汚染し、モデルのパフォーマンスを低下させた
https://arxiv.org/abs/2302.10149
・GPT モデルの機械翻訳における包括的な評価
GPTモデルは高リソース言語では非常に競争力のある翻訳品質を達成する一方、低リソース言語ではその能力が限定的。また、GPTモデルと他の翻訳システムを組み合わせたハイブリッドアプローチが、翻訳品質をさらに向上。
abs: https://arxiv.org/abs/2302.09210
・画像ビュー合成と3Dを考慮した拡散からのNeRF誘導型蒸留法
論文: https://arxiv.org/abs/2302.10109
プロジェクト: https://jiataogu.me/nerfdiff/
NerfDiff: Single-image View Synthesis with NeRF-guided Distillation from 3D-aware Diffusion
— AK (@_akhaliq) February 21, 2023
abs: https://t.co/xajK2VrcdC
project page: https://t.co/KtVopBjVwW pic.twitter.com/QfmPDoOiAB
・1会議に1台ファシリテーター言語モデル
多様な意見を持つ人々が一致点を見出すのを機械が役立つかを検討した論文 - 700億パラメータのLLMを微調整 -報酬モデルが個人の嗜好を予測するように訓練 -人間の最良の意見よりも好まれる合意候補文を生成
論文 https://arxiv.org/abs/2211.15006

・テキスト/画像/グラフにおける、BERT/GPT-3/DALLE-E/ChatGPTなどの事前学習された基盤モデルに関する約100ページに及ぶサーベイ論文
モデルの効率と圧縮、セキュリティ、プライバシーなどの関連研究についてや、将来の研究の方向性、課題、未解決の問題などが網羅
https://arxiv.org/abs/2302.09419

・AI2がパーソナライズがん治療計画支援ツールを発表
科学文献の大規模なコーパスとテキストマイニング技術を使用して、医療専門家が多くの異なる治療の組み合わせを含むパーソナライズされたがん治療計画を作成するのを支援
ツール http://planbuilder.apps.allenai.org
記事 https://blog.allenai.org/computer-aided-cancer-treatment-plan-design-5f6c05d240df

・Amazon は最近、ScienceQAベンチマークにおいてGPT-3.5 よりも 16% 優れ、784 倍小さいモデルをリリース
視覚情報も入力に入れ、中間CoTを生成することによって達成。 Apache-2.0 Licenseでコードもモデルも公開されてる。
論文: https://arxiv.org/abs/2302.00923
コード: https://github.com/amazon-science/mm-cot

・RealFusion 360° 単一の画像からの任意のオブジェクトの再構築
abs: https://arxiv.org/abs/2302.10663

・PC2: 単一画像から3Dモデル再構成のための投影条件付きpoint cloud diffusion
論文: https://arxiv.org/abs/2302.10668

・課題も残ってるが、ChatGPTのコード生成により、ロボットアーム、ドローン、ホームアシスタントなどの複数のプラットフォームを言語で制御できてる
Blog: https://aka.ms/ChatGPT-Robotics…
Paper: https://microsoft.com/en-us/research/uploads/prod/2023/02/ChatGPT___Robotics.pdf…
Video: https://youtu.be/NYd0QcZcS6Q
Discover a new paradigm for robotics, powered by ChatGPT! Our experimental study delves into design principles and model capabilities for solving robotics tasks with ChatGPT.
— Sai Vemprala (@saihv) February 21, 2023
Blog: https://t.co/lL863c0XsS
Paper: https://t.co/bzFPTWcM2c
Video: https://t.co/DpkJ1jSmkY
🧵👇(1/N) pic.twitter.com/NxJDpSyKGU
・ChatGPTの能力を25の多様な分析的NLPタスクで検証し、38000以上の回答を分析した論文
arxiv.org/abs/2302.10724

・ChatGPTのようなモデルを学習するときに必要な、どの回答がより良いかの人間のフィードバックデータであるStanford Human Preferences Dataset (SHP) がリリース
料理から法律相談まで18の分野の質問・指示に対する回答をRedditから抽出し、嗜好性を評価。
https://huggingface.co/datasets/stanfordnlp/SHP
・FLAN-T5モデルから派生したSteamSHP と呼ばれるいくつかのプリファレンスモデルもリリース
どちらの回答がより良いを予測するように微調整されている。NLG 評価用に、または RLHF の報酬モデルとして、すぐに使用できる。
・テキスト画像生成モデル×ロボット
ROSIE: Scaling RObot Learning with Semantically Imagined Experience ロボット学習のデータ拡張にテキスト画像生成モデルを使用することを提案。この拡張により、操作などの下流のスクを学習するための画像を生成可能
ウェブサイト:http://diffusion-rosie.github.io
Text-to-image generative models, meet robotics!
— Fei Xia (@xf1280) February 22, 2023
We present ROSIE: Scaling RObot Learning with Semantically Imagined Experience, where we augment real robotics data with semantically imagined scenarios for downstream manipulation learning.
Website: https://t.co/vIAnaK3Y3c
🧵👇 pic.twitter.com/I4ZmakUljJ
・Vid2Avatar: 動画から3Dアバター復元
論文: http://arxiv.org/abs/2302.11566
プロジェクト: http://moygcc.github.io/vid2avatar/
Vid2Avatar: 3D Avatar Reconstruction from Videos in the Wild via Self-supervised Scene Decomposition
— AK (@_akhaliq) February 23, 2023
abs: https://t.co/vE62SjuYUB
project page: https://t.co/uqFN885RlW pic.twitter.com/xYxdpDQttG
・辞書なし言語モデルだけで翻訳していたが、特にデータ量の少ない言語の希少語を翻訳するのに辞書との組み合わせが有益だったとのこと
一般知識を持つ言語モデルに、ニッチなデータを辞書やグラフデータで補強する、は翻訳以外でも起きそう
論文: https://arxiv.org/abs/2302.07856

・1 つの画像と 5 ~ 15 の調整ステップで新しい概念を追加できるテキスト画像生成モデル
abs: https://arxiv.org/abs/2302.12228
プロジェクトページ: https://tuning-encoder.github.io
Designing an Encoder for Fast Personalization of Text-to-Image Models
— AK (@_akhaliq) February 24, 2023
TL;DR: use an encoder to personalize a text-to-image model to new concepts with a single image and 5-15 tuning steps
abs: https://t.co/pn2adCjp6L
project page: https://t.co/Kr22yp7HYl pic.twitter.com/naQI4TA05q
・遠近法を考慮した3次元GANによるポートレート歪み補正
論文: https://arxiv.org/abs/2302.12253
プロジェクトページ: https://portrait-disco.github.io
Portrait Distortion Correction with Perspective-Aware 3D GANs
— AK (@_akhaliq) February 24, 2023
abs: https://t.co/0Lds4o3JZL
project page: https://t.co/USIJeUAEge pic.twitter.com/KsjFNzQ2Lp
・人間のフィードバック x テキスト画像生成
abs: https://arxiv.org/abs/2302.12192

・MERF
ブラウザーで大規模なシーンのリアルタイム レンダリングを実現するメモリ効率の良い放射輝度場 (MERF) 表現を提案
abs: https://arxiv.org/abs/2302.12249
プロジェクト: https://merf42.github.io
MERF: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
— AK (@_akhaliq) February 24, 2023
abs: https://t.co/0B8d3rH5KL
project page: https://t.co/2vWyYgyIak pic.twitter.com/hDy1ArqGEe
この記事が気に入ったらサポートをしてみませんか?