巨大データベースの運用とデータレイク - パーソルグループ AWS合同勉強会

この度、パーソルグループ 横断のAWS合同勉強会を開催しました。
グループ内でAWSを使っているチームやクラウド活用を推進しているチームが増えたので、情報共有の目的と、グループでテクノロジーをもっと盛り上げていきたという思いで今回企画をしました。
ミイダスでは「巨大データベースの運用とデータレイク」というテーマで府川が登壇しましたので、その内容についてご紹介します。

巨大データーベースの運用とデータレイク
ミイダス株式会社の府川と申します。よろしくお願いいたします。
今日は主にデータベース周りの話を少ししようと思います。
まずミイダスについてですが、簡単に説明すると、求職者と企業が直接やりとりして、転職を実現するサービスになります。他社さんでいうと、ダイレクトリクルーティングに近いイメージですね。こちらの画像は、企業側のホームページで、私の背景に写しているのがユーザー側のホームページになります。
ミイダスのがサービスを開始したのは、2015年頃で今年で6年目になります。
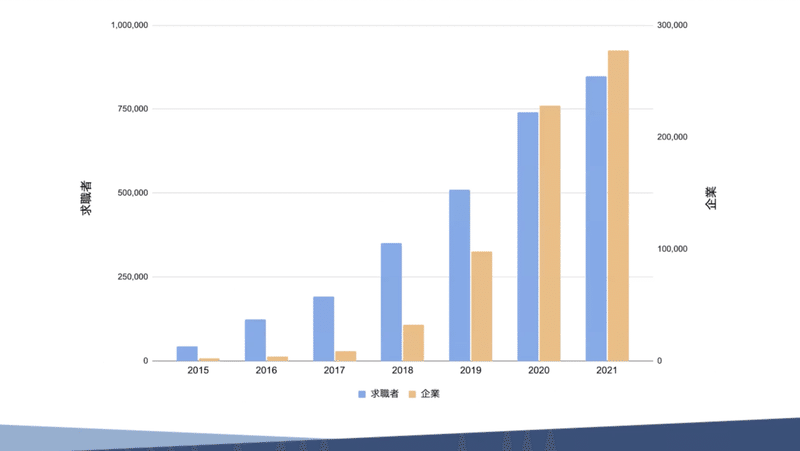
こちらの画像は、求職者の方と企業のグラフで、利用者数表しています。
求職者側と企業側で数字の尺が違うので若干いびつな感じのグラフになっていますが、順調に成長しています。
ユーザーが増えると当然データも増えるので、データベースが色々と大変になってきているという話を本日、少ししたいと思います。
ミイダスのAWS構成
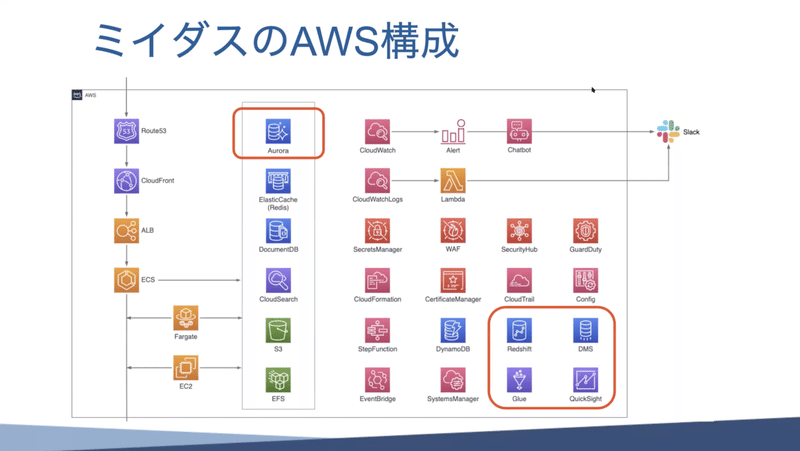
こちらはミイダスのAWS構成で、使っているサービスを列挙するとこのような感じになります。
サービスのWeb側のところは、CDNを挟んでロードバランサーが受けて、後ろでコンテナが受けて、その後ろにデータベースやストレージとかあるという一般的によくあるWebサービスの形を取っています。
画像の右側にある赤いアイコンは、監査とかセキュリティなど利用している様々なサービです。今日お話しするのは、上の赤枠で囲っている所、サービス本体のAuroraデータベースと、右下の赤枠、サービスとは直接関係のないところで動いている、データ分析で使うRedshiftというデータベースについてです。
ミイダスのAurora(MySQL)
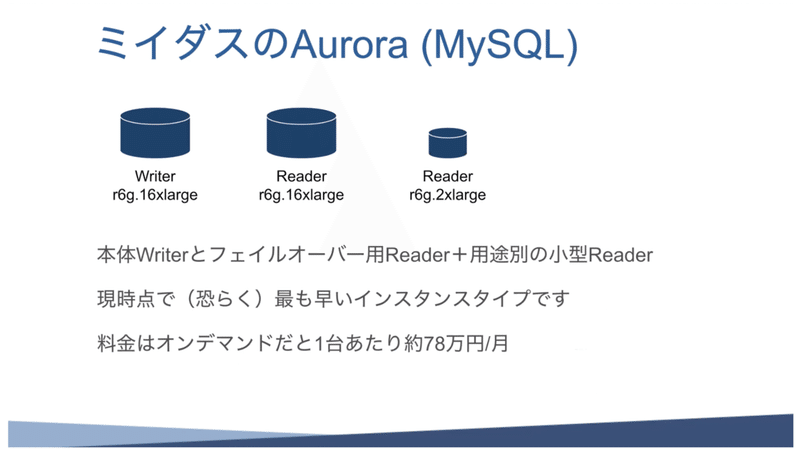
まずはミイダス本体のデータベースについてですが、AWSのAuroraのMySQLバージョンを使用しています。
弊社の特徴の一つとして、インスタンスのサイズがとても大きいのです。この間ちょうど、TokyoリージョンでR6gインスタンスがGenerally Availableになったので、早速それを使っているのですが、インスタンスサイズとしては一番大きいものを使っています。
大きいインスタンスをメインで使っているWriter、バックアップ用のフェイルオーバー用のReaderを1台、あとは時期に応じて複数のReaderが増えたり減ったりしています。
大きいインスタンスなので、当然料金もすごいことになってまして、普通に使うと月78万円というなかなか高級なものを使っています。
当然リザーブドインスタンスを使っているのですが、リザーブドインスタンスの金額もなかなかすごいことで毎年うん千万の購入をしています。
データ特性
次にデータについてですが、単純に求職者と企業が増えるにつれ、データが掛け算で増えていきます。
一番大きいのがオファーと呼ばれているデータで、これが他社さんでいうとスカウトという名前だったりします。企業から求職者に「うちの会社で働きませんか?」と言ってリクエストを出す機能です。
このデータが一番大きくて、求職者と企業の求人とが、掛け算で増えている状況です。
以下画像の下部にあるのは、slackで毎週Botがデータベースでテーブルを投げてくれるものの抜粋なんです。このtable_rowsというところ、ここの数値が大きくて約20億くらいという膨大な量になっています。
さらにちょっと面白いのが、この間、このデータがintの数の上限を超えて、intでデータを扱っているところが溢れて障害が起きるという事件がありました。なかなか体験できないですよね。このように珍しいことをやっていたりします。
あとはテーブルの各容量がすごくて、1テーブルで300Gや400Gなど、なかなか大きなテーブルを使っているなという感じです。

データベースの運用
これだけ大きなデータを使っていると、色々問題が起こります。昔はこれほど大きくなかったので、小さい頃は可愛いものでした。しかし、データが増えてくるとメモリに乗らない、バッチが終わらない、などの問題が出てきていました。これまでは、メモリが足りないのであればスペックアップしようとか、バッチが遅い時はいっぱいReaderを増やして並列して、それでしのぐ対策をしてきました。
今は書き込み量が多すぎて、ストレージがボトルネックになっています。これはまだ解決策が見出せていないのですが、インスタンスのサイズはこれ以上あげられないので、ちょっとデータベースの分割や、別のアプローチを取らないといけないと思っている次第です。
データの活用(過去)
ここからは少し話が変わるのですが、それなりに色々なでデータを持っているので、このデータを活用しようとしています。
昔はいわゆるアクセスログを、普通であればElasticsearchに放り込むというのがよくある話だと思うのですが、弊社の場合は、別のAuroraを立てて、そこに入れてました。
そこのログが入っているAuroraに本体からのデータを同期して、色々なデータを一箇所で見れるようにしていました。
こうしておくとSQLでデータを抽出するのが楽になりますし、ログと本体のデータ(ユーザーIDとか企業 ID)を繋げておくと、その企業がこういう行動をしたとか、このユーザーはこれとこれを見た後にこうしたとか、などの行動分析ができるというメリットがありました。
しかし、最初は良かったのですが、データが増えてくると、これらの統計用SQLを投げると、遅くて返ってこない状況になってしまいました。
この問題を解決するために、データレイクの導入を進めました。
データレイク
データレイクは、色々なデータを一箇所にまとめ、データの中身は気にしないでとりあえず保存しておく場所を作り、そのデータを色々なところの分析で使うという仕組みです。
AWSのデータレイクハンズオンに参加させていただき、データレイクを初めて触りました。色々と教えてもらって、これは良さそうだと思い、弊社でも導入しました。
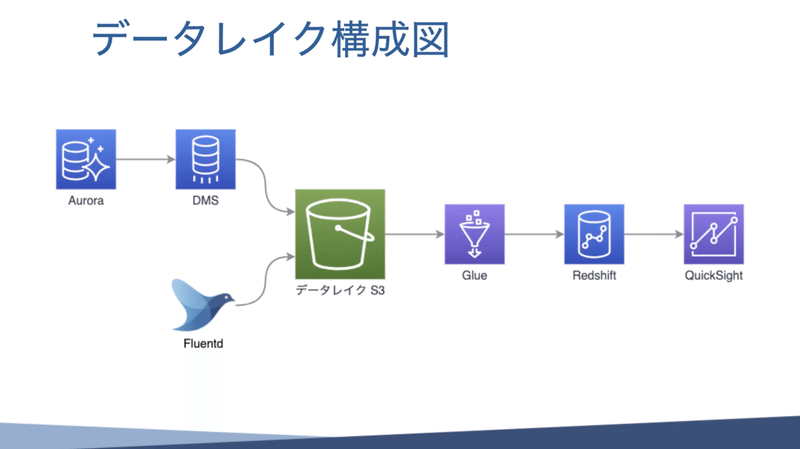
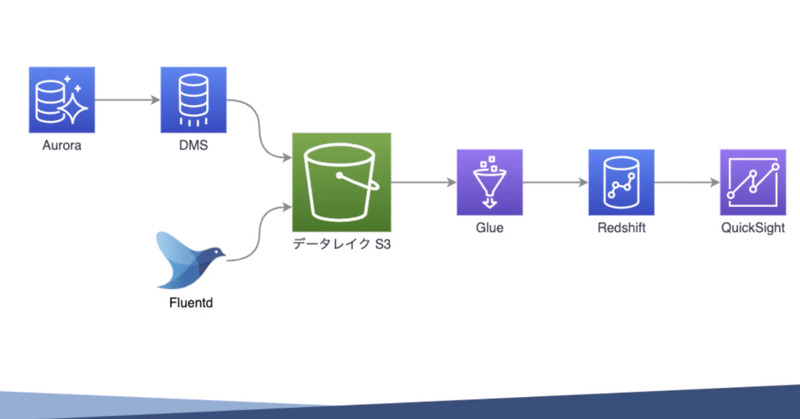
データレイクをざっくりの図に表すとこちらの画像のようになります。
本体のAurora データベースから、DMSを使って、データレイクS3にデータを投げ込みます。DMSは、データーベース マイグレーションサービスというのですが、データベースのデータを右から左に流すサービスです。
また、アクセスログはFluentdで拾っていたので、それを使ってS3に投げておきます。このS3に色々なデータを貯めておき、そこからGlueを使ってデータを取り出しRedshiftに流します。Glueは、いわゆるETLと呼ばれているサービスで、データを持ってきて加工して流し込むサービスです。
Redshiftというのは、列指向のポスグレ互換のデータベースみたいなイメージのさらに大きいものになります。弊社の場合転職サービスなので、ユーザの個人情報などセンシティブな情報をGlueで抜いています。なので、Redsiftにあるデータは色々参照しても問題のない安全なデータに加工されています。
Redshiftにデータベースに直でSQLでデータを投げることもできるのですが、ちょっと使いづらいので、QuickSightというAmazonが提供しているBIサービスを使って主にグラフを作ったり、ダッシュボードを作ったりしています。
データの活用(現在)
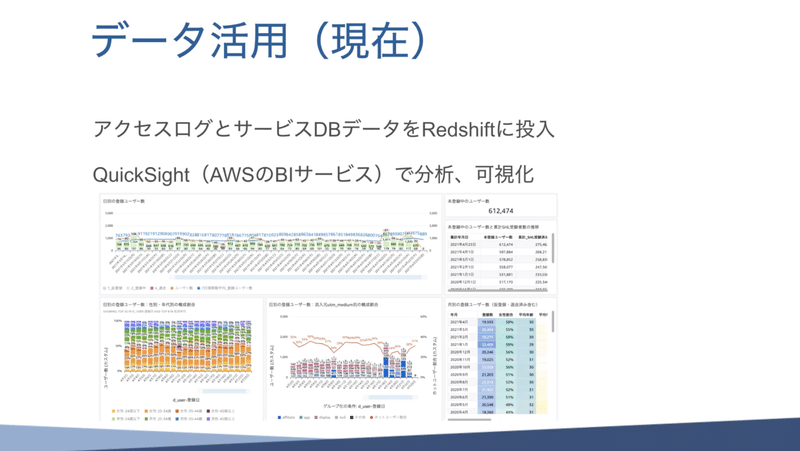
QuickSightは、このような感じで表示されます。いわゆるBIツールなので、カラフルで綺麗な感じでグラフに出せたりします。
あとはフィルターの条件とかを入れることができるので、直近1ヶ月のデータのみを表示させることも可能で、色々と便利な感じのサービスです。
これを使うことで、今はデータ分析がいい感じにできています。
分析している人の話によると、AuroraでSQLでやっていた時に比べて、Redshiftにするとものすごい早いらしく、一瞬で返ってくるのですごく助かってます、なんて話をよく聞きます。
以上、ミイダスで取り組んでいる「巨大データベースの運用とデータレイクについて」ご紹介させていただきました。
ミイダスでは、このように様々なデータを活用しながら、大規模データベースの運用開発を進めています。
ミイダス Techについて
ミイダスでは、様々な技術イベントを開催しています。connpassやYouTubeチャンネルでミイダスグループのメンバーになった方には、最新の開催情報やアーカイブの公開情報が届きますのでぜひご登録をお願いいたします。
イベントページ:https://miidas-tech.connpass.com/
Twitter:https://twitter.com/miidas_tech
この記事が気に入ったらサポートをしてみませんか?