
#12高校情報科の授業で初めてPython(パイソン)というプログラミング言語に取り組む 第12回

2020年度、初めて授業でPython(パイソン)というプログラミング言語に挑戦している。
第12回はGoogleColaboratoryを使って、アヤメのデータセットを使った機械学習にチャレンジした。
これからPython(パイソン)を学ぶ方の参考になれば幸いです。
学習内容
テキスト『ゼロからやさしくはじめるPython入門』より、大切な部分を抜粋します。
機械学習とは、人工知能の一分野で、コンピューターに大量のデータを入力して、そのデータを解析し、そのデータから有用な規則やルールを抽出する手法のことです。
機械学習を実践すると、分類、予測、ルール抽出が実現可能になります。
「分類」とは、過去の分類事例をもとにして、未知のデータを分類することです。具体的には、大量の手書き文字を学習しておくことで、新たに手書き文字の画像を与えると、文字の認識ができるようになります。また、大量の写真を学習して、そこに何が映っているのかを判定できます。同じように、大量のテキストデータを学習しておいて、迷惑メールかどうかを判断したり、ニュース記事をカテゴリごとに自動分類を行ったりすることができます。
次に「予測」とは、過去の大量のデータを分析して、将来の予測を行うことです。その具体例としては、過去の大量の株の取引データを学習して、未来の株価を予測することもできます。また過去の気象データや売上データを学習して、未来の天気や売上予測を行うことも可能です。
そして「ルール抽出」とは、ある事象と他の事象が発生する関係を抽出するものです。例えば、あるコンビニの購入履歴情報を分析して「牛乳を買うお客は卵も買う」とか「カップラーメンを買うお客は冷凍食品も買う」などといったルールを導き出すことです。通販サイトでれば、ユーザの購入した商品に基づいて、オススメ商品を提示することもできるでしょう。
簡単な分類問題が例にあがっている。2種類のデータを2次元のグラフにプロットしたものだ。コーヒーが好きな人を▲、紅茶の好きな人を●で表したとする。
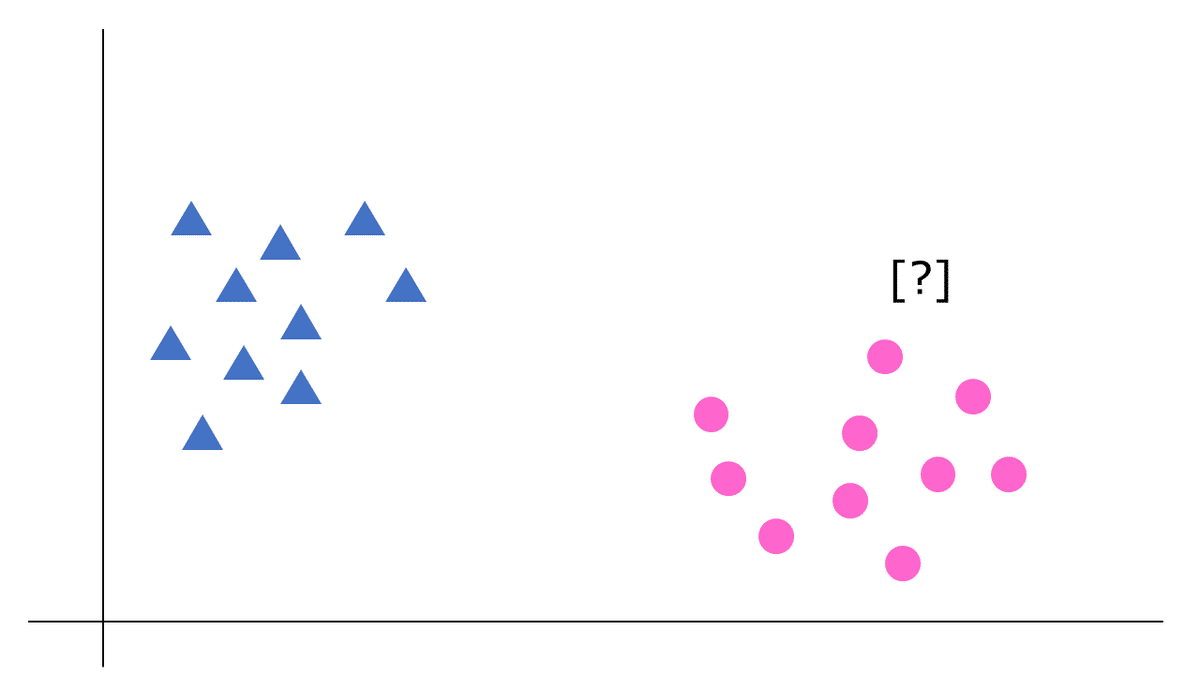
[?]で示した位置にいる人は、コーヒー好きか紅茶好きかのどちらかを考える。明らかに紅茶好きだと予測できるだろう。
人間の目ならパッと見で見分けることができるが、コンピューターはどのように見分けているのだろうか?例えば、次のような境界線を引いて、その境界線の右側か左側かを計算によって調べることができるそうだ。

機械学習のライブラリ、サイキット・ラーンのアヤメのデータを使って、品種の分類にチャレンジした。

テキストはAnacondaのJupyterNotebookを利用する手順になっていたが、GoogleColaboratoryでも同じように動作した。
150個のデータを読み込んで、データをシャッフルし、120個を学習用に、残りの30個を評価用と分け、サポートベクターマシンのアルゴリズムで学習モデルを構築し、評価した。
生徒の様子
テキストの通り打ち込んで動かしてみると、テキストの通りに出力されるが、何をしているか実感しづらいようだった。
アヤメの品種Setosa,Versicolour,Virginicaを写真で紹介し、花びらとガク片の図も見せたが、生徒たちの興味を引き出せなかったように感じた。
ただ、人工知能の一分野に機械学習があり、簡単な分類ができるということは伝わったと思われる。
また、あっという間に出力され、人間が分類するよりも圧倒的に早いことは実感できた。
テキスト
https://book.mynavi.jp/ec/products/detail/id=87236
マイナビ出版の『ゼロからやさしくはじめるPython入門 基本からスタートして、ゲームづくり、機械学習まで楽しく学ぼう!』に沿って学んでいる。
この記事が気に入ったらサポートをしてみませんか?