
5.総スコアの数理パターンの再現性

前回の話はこちら。
https://note.com/memantine2000/n/n03bae4d763d0
前回は抑うつ評価尺度の総スコアが指数分布に従うことを述べた。今回はその再現性について説明する。
#1 一般人口における指数分布の再現性
抑うつスコアの分布が指数分布に従うことについては、これまで日本で行われた二つの行政調査(保健福祉動向調査、国民生活基礎調査)、米国政府による三大行政調査(NHIS、BRFSS、NHANES)、英国やアイルランドにおける行政調査、また社会学で有名なMidlife in the United States (MIDUS)のデータ分析、等において確認されている。これまで様々な公的調査のデータを調べたが、一般人口における抑うつスコアが指数分布を示すことを確認できなかったことはなかった。つまりこの現象の再現性は高いと言ってよい。これらの結果をすべて紹介するのは控えるが、興味のある方はこのテーマに関する総説を参照していただければと思う(Tomitaka S. Heliyon. 2020)
#2 会社員や小中学生のデータも指数分布に従う
興味深いことに、抑うつスコアが指数分布を従うという現象は一般人口だけではなく、特定の集団においても確認された。たとえば北海道の会社員を対象にした調査や、国立大学の大学生や青森県の小中学生対象にした調査でも(Adachi M, et al. Psychiatry Clin Neurosci. 2020)、やはり抑うつスコアは指数分布に従うことが明らかになった。なお北海道の会社員の分析結果は既に論文として発表されているが(Tomitaka S, et al. PLoS One 2016)、国立大学の大学生や青森県の小中学生の分析結果,は論文としては発表されていない(他の研究者が発表したデータ を私が個人的に分析したものなので発表するのは難しい)。
会社員や小中学生といった特定の集団でも同じ分布モデルに従うことに疑問を感じる人もいると思う。しかしこれはそれほど不思議なことではない。たとえば身長の分布を調べると、一般人口を対象にしても、会社員や小中学生を対象にしても、概ね正規分布にしたがう。それと同じことではないかと思う。抑うつスコアに非常に偏りがある集団を除けば、抑うつスコアの分布は概ね指数分布に従うということである
人間は集団をステレオタイプ化してイメージする傾向がある。大企業の社員や国立大学の学生は比較的順調に人生を送っているイメージを抱きがちだ。しかし実際はそういった集団においても、抑うつスコアの分布は指数分布に近似する。つまりある程度の大きさの組織になれば、うつ病と診断してよいレベルの人々がある程度の割合で存在するということである。こういったことは大企業の人事や大学の保健センターにとっては、周知の事実と思う。
これは国レベルでも同じことが言える。イタリアやスペインのような陽気な国民性で知られる国でも抑うつ症状の分布は同じ数理モデルに従う(Tomitaka S, et al. Scientific Reports 2019)。幸福度が高いというイメージがあるフィンランドやデンマークのような北欧諸国でも同じことがあてはまる(あまり知られていないが、北欧のような幸福度が高いと言われる国においてうつ病患者が少ないわけではない)。どの国でもうつ病と診断できる人々が総人口の数パーセントは存在する。
うつ病問題は、その国に特有な要因に焦点を当てて論じられることが多い。たとえば日本の場合、「日本では同調圧力が強いので、生きづらさを感じる人が多い」といった論考がよく行われる。しかし実際のデータを調べると、どんな国でも抑うつスコアの分布は同じ数理パターンに従う。それぞれの国の特有な要因について論じるのもよいが、普遍的な仕組みについても考える必要がある。
#3 どの抑うつ評価尺度でも指数分布が成立することの再現実験
抑うつ尺度の項目数はそれぞれ異なる。CES-Dの質問項目は16項目、PHQ-9 は9項目、K6は6項目である。また項目に含まれる抑うつ症状もそれぞれ異なる。それにもかかわらず、いずれの抑うつ尺度を用いても総スコアは指数分布を示した。ということは、抑うつ尺度の項目や項目数に関係なく、抑うつ尺度の総スコアの分布は指数分布を示すのかもしれない。
この仮説を検証するため、任意に選んだ項目のスコアの和がどういった分布になるか調べてみた。
検証に用いたのは2000年に日本で行われた保健福祉動向調査のデータ(約32000人)である。この調査ではCES-Dという抑うつ尺度が使用された。CES-Dには、抑うつ症状16項目が含まれる。被験者は過去2週間に、これらの症状がどの程度あったかを、4つの選択肢、「ほとんどない」、「少しある」、「かなりある」、「いつもある」(点数はそれぞれ0-1-2-3)から選択する。
図1が示すように、CES-Dの抑うつ症状16項目は、「6.面倒だ」のように発現しやすいものから、「13.突然泣く」のような発現しにくいものまで様々である。
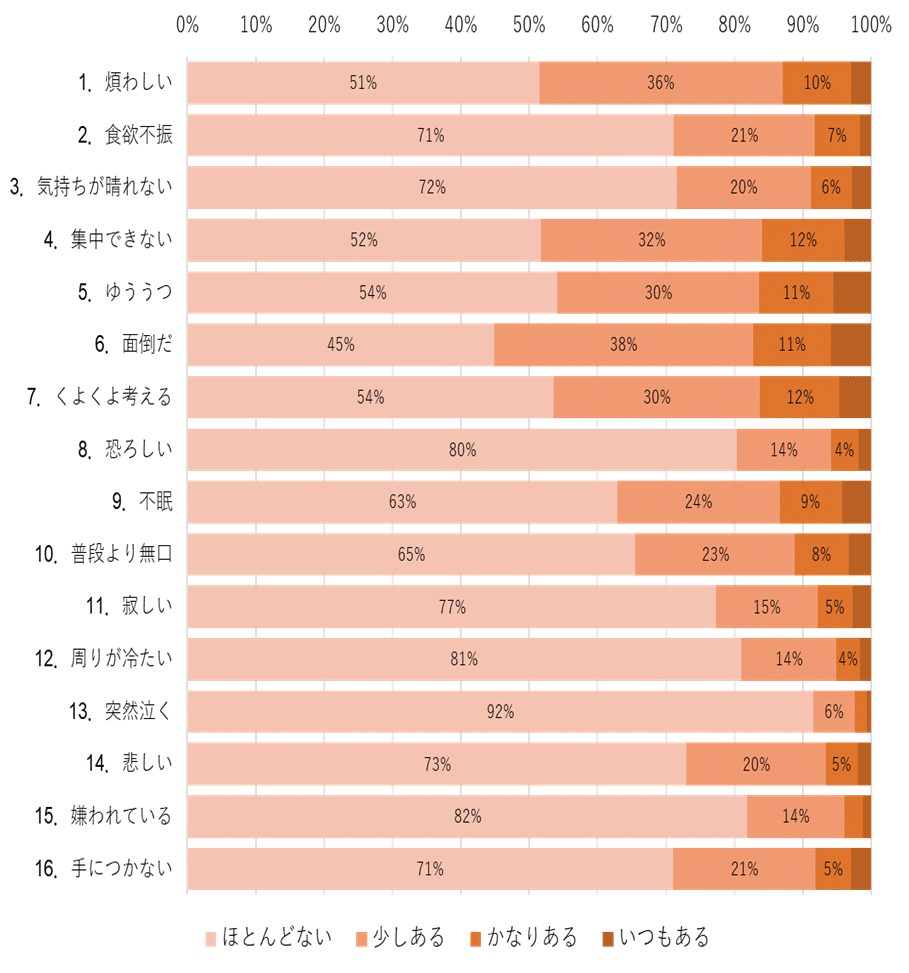
抑うつ症状16項目から4項目を選んだ場合、それらの項目スコア(点数はそれぞれ0-1-2-3)の和がどのような分布を示すかを調べた。
抑うつ症状16項目を4つのグループに振り分けた(1.高発現群、2.やや高発現群、3.やや低発現群、3.低発現群)。「高発現群」は発現率が1番目から4番目の項目、「やや高発現群」は発現率で5番目から8番目の項目といった具合いである。それぞれのグループの項目スコアの和(0点から12点)の分布を調べた。
図2はそれぞれの群の項目スコアの和の分布である。

グラフを見るといずれの分布も右肩下がりを示している。しかし同じ右肩下がりとはいえ、下がり方はそれぞれ異なる。図2Aの低発現群のグラフは傾斜が急激だが、図2Dの高発現群の傾斜はなだらかで、特に1点から3点の間はほぼ平らとなる。
これらの4つのグラフが指数分布に従うか確認するために対数グラフに重ねてみた。その結果が図3である。

図3では、4つのグラフはy軸近傍を除いていずれも直線を示している。つまりy軸近傍を除くと、どのグラフも指数関数に近似するということである。注意してほしいのは、4つのグラフはお互いに平行ということだ。これは、4つのグラフがスコアの増加に伴い同じ比率で減少する(指数関数のパラメーター(減少比率)がほぼ等しい)というを意味する。つまり分布の減少率は項目数によって決まるということである。
一方でy軸近傍、つまりスコア0点から3点の範囲では直線から外れている。つまりy軸近傍では指数分布から外れる、ということである。y軸近傍でグラフが指数分布から外れるという所見は、以前のnote 4.抑うつ尺度の総スコアの分布モデルで紹介したK6の4つグラフと一致する。
0点から3点の曲線エリアと4点から12点の直線エリアとでは、グラフの上下関係が逆転している。例えば低発現群のグラフは曲線エリアでは一番上に位置するが、直線エリアでは一番下に位置する。逆に高発現群のグラフは曲線エリアで一番下に位置しているが、直線エリアでは一番上に位置する。これはどんな分布でもすべての確率分布の和は100%になるからだろう。
任意の4項目のスコアの和について調べたが、3項目や6項目や8項目の項目スコアの和の分布についても調べた。その結果やはり同様の結果を認めた。つまりどんな抑うつ症状をいくつ選択しても、項目スコアの和のグラフは指数分布を示し(y軸近傍を除く)、y軸近傍では指数分布から外れた(Tomitaka et al. PLoS One 2016)。またこういった現象はCES-Dだけではなく、他の抑うつ尺度でも確認できた(Tomitaka S, et al. BMC Psychiatry 2017).
以上より、抑うつ症状の項目スコアの和の分布は、項目の数や抑うつ症状の内容に関係なく、y軸近傍を除いて指数分布に従うことが明らかになった。また抑うつ尺度の総スコアの分布の減少率は項目数によって決まることが明らかになった。
#4 余談
任意に選んだ項目のスコアの和がどういった分布になるか調べた論文は、自分にとっては思い出深い論文である(Tomitaka S, et al. PLoS One 2016)。学術誌から何度もrejectされたからだ。
抑うつ尺度の項目や項目数に関係なく、抑うつ尺度の総スコアの分布は指数分布を示すことを証明するには、任意に選んだ項目のスコアの和が指数分布を示せば証明できる。自分としては良いアイデアと思ったのだが、レビューアーの大半は論文の主旨を理解してくれなかった。
「CES-Dの項目を勝手に選んでそのスコアを調べること自体がナンセンスだ」と査読すら受けつけてくれない学術誌もあった。5-6回ぐらいrejectされたと思う。
また査読に回ったとしても、レビューアーの中には因子分析や項目反応論を用いた解析を勧めてくる人もいた。心理学統計学の研究者の大半は因子分析や項目反応論の専門家なので、自分たちが慣れ親しんだやり方でデータを分析してほしいのだろう(研究テーマは査読者ではなく、投稿者が決めるべきものと思うのだが)。
心理学の研究では既存の統計モデルを使用して、データを分析することが一般的である。データの中に数理パターンを探すような研究はあまりない。そういったこともあり、こういったテーマの論文はレビューアーにとって奇妙な論文に見えたのかもしれない。
いくら本人が面白いと思っても、他人に論文の面白さを理解してもらうのは大変である。そもそも抑うつスコアが指数分布に従うことはまだ学会でもほとんど知られていない。まだ知られていない事実の再現性を奇抜なアイデアで検証しようとしても、理解しにくいのは当たり前かもしれない。
文献
1) Tomitaka S. Patterns of item score and total score distributions on depression rating scales in the general population: evidence and mechanisms. Heliyon. 2020 6: e05862.
2) Adachi M, et al. Distributional patterns of item responses and total scores of the Patient Health Questionnaire for Adolescents in a general population sample of adolescents in Japan. Psychiatry Clin Neurosci. 2020 74:628-629,
3) Tomitaka S, et al. Distribution of total depressive symptoms scores and each depressive symptom item in a sample of Japanese employees. PLoS One 2016 11: e0147577.
4) Tomitaka S, et al. Responses to depressive symptom items exhibit a common mathematical pattern across the European populations. Scientific Reports 2019, 9: 1-9.
5)厚生労働省大臣官房統計情報部編 平成12年保健福祉動向調査 2002厚生統計協会
6)Tomitaka S, et al. Relationship between item responses of negative affect items and the distribution of the sum of the item scores in the general population. PLoS One 2016, 11: e0165928
7) Tomitaka S, et al. Characteristic distribution of the total and individual item scores on the Kessler Screening Scale for Psychological Distress (K6) in US adults. BMC Psychiatry 2017 17: 290.
この記事が気に入ったらサポートをしてみませんか?