
4.抑うつ尺度の総スコアは指数分布に従う

前回の話はこちら。
今回は、抑うつ評価尺度の総スコアの数理パターンの話です。
#1 抑うつスコアの分布の数理パターン
K6という抑うつ評価尺度のデータを用いて、抑うつスコアの分布の数理パターンを調べた。なぜK6を選んだかというと、この尺度は日米で行われた大規模な行政調査で最も使用されているからである。日本では国民生活基礎調査、米国ではNHIS(National Health Interview Survey)、BRFSS (Behavioral Risk Factor Surveillance System)、NSDUH(National Survey on Drug Use and Health)と、4つの調査でK6が使用されている。それぞれ数万人から数十万を対象とした大規模調査なので。分布の形を検証するには適切なデータと思う(以前も述べたが1000人以下のサンプルでは分布の数理モデルを検証しづらい)。
K6はKesslerらによって大規模調査のために開発された抑うつ尺度であるが、現在はうつ病や不安障害のスクリーニング目的に世界的に使われている。K6は、「1.神経過敏」「2.絶望的」「3.そわそわ、落ち着かない」「4.気分が沈み込んで、何が起こっても気が晴れない」「5.何をするのも骨折り」「6.自分は価値がない」、の6項目から成る。Kessler が作成した、6項目の抑うつ尺度なのでK6という。
被験者は過去一か月間に、6項目の症状がどの程度あったかを、「全くない」「少しだけ」「ときどき」「たいてい」「いつも」の5段階から選択する(0-1-2-3-4)。6項目からなる、5段階の評価尺度なので、総スコアは最小0点から最大24点まで分布する。なおK6では、うつ病スクリーニングのためのカットオフ値として13点以上が推奨されている。
図1はそれぞれの調査のK6スコアの分布を示している。いずれのグラフも右肩下がりを示している。
グラフの点線(13点)はうつ病スクリーニングのためのカットオフ値であるが、K6が13点以上の比率を調べると、日本の国民生活基礎調査はでは3.1%、米国のNHIS、BRFSS、NSDUHではそれぞれ4.0%、3.6%、6.4%であった。つまり日米いずれもうつ病と診断される可能性が高い人々が、人口の3∼6%程度、存在するということである。
なおK6が13点以上の比率がNSDUHでは高いのは、NSDUHの調査方法が影響している可能性が高い。NSDUHは面接時に audio computer-assisted self-interviewというプライバシーを重視する方法を用いており、この方法を用いると得点が高くなると言われている(Tomitaka S, and Furukawa TA. BMC psychiatry)。

図1は日米4調査のK6の分布である。では上記4つのグラフに共通する数理パターンは存在するだろうか?図1からわかるのは、すべてのグラフが右肩下がりを示しているということである。一般的に右肩下がりを示す分布モデルには、指数関数、ベキ関数、対数正規分布、等がある。
すべてのK6の分布を対数グラフに重ねてみた(図2)。対数グラフに入力すると、指数分布は直線を示し、正規分布は二次関数を示し、ベキ分布は対数関数を示す。したがって対数グラフは分布の数理パターンの鑑別によく使用される。

図2の対数グラフを見ると、すべてのグラフが直線を示しており、かつほぼ平行である。すべてのグラフが直線を示しているということは、K6の分布はいずれも指数関数に近似するということである。なお4つグラフが平行であるということは、それぞれの指数分布の減少率(λ:パラメーター)がほぼ等しいということである。スコアが増えるごとにλの比率で減少するということである。ちなみに指数分布の数式は下記のように と表すことができる
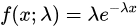
図2を見るといずれのグラフも直線を示しているが、少し直線から外れる部分がある。矢印が示すようにスコア0点の近くでは少し上にシフトしている。つまりスコア0点の近くでは実際のデータが指数分布から外れるということである。この現象について次回のnoteで詳しく説明する。
指数分布が他の分布モデルより抑うつスコアの分布にあてはまるかどうかも検証した。AICやBICといった情報量基準の結果からも、ベキ分布や対数正規分布よりも指数分布が抑うつスコアの分布にもっともあてはまることが確認できた。
以上より、日米いずれのデータを分析しても一般社会における抑うつスコアK6の分布は指数分布に近似することが明らかになった。
#2大規模データと大数の法則
図2のグラフを見せてもピンとこない人がたまにいる。「たまたま平行になっただけではないか」と質問する人もいた。どうやら世の中の人は分布や確率に対して偶然で不安定というイメージを持っているようである。
確かに少数サンプルの分布は偶然に左右される。仮にサイコロを一回振るなら、どの目が出るかは偶然に左右される。一方、サイコロを一万回振ると、サイコロの目の分布は安定する。正確なサイコロの場合、それぞれの目が出る確率はほぼ六分の一になる。大規模サンプルになればなるほど分布の形は必然性を帯びるのである。
このようにデータ数の増加に伴い、実際の分布があるべき分布に近づくことを、大数の法則(Law of large number)と呼ぶ。データ数が増えるにつれ、分布はあるべき分布に近づくのである。そしてあるべき分布はその現象の仕組みを表現したものである。
本書で紹介した分布は、いずれも数千人から数万人のサンプルのものである。こういった大規模データから得られた分布の形は必然性が高い。そういったことを考えると「たまたま指数分布に似た形を示したのかもしれない」と考えるよりも、「指数分布が発生する仕組みが存在する」と考えた方が合理的である。
#3 指数分布から考えるうつ病診断
抑うつスコアの分布が指数分布に従うという事実は、うつ病診断を行う上で大きな意味を持つ。うつ病診断における抑うつスコアの分布の意味について簡単に説明したい。
K6の方対数グラフ(図2)を見ると、スコアの値に関係なくグラフは連続して直線を示している。このことは、K6の分布はスコアの値に関わらず同じ数学的ルールに従うことを示している。
一般的に重い抑うつ症状を認める人々、つまりK6のスコアがカットオフ値(13点)よりはるかに高い人々は、うつ病と診断される可能性が高い。その一方で、カットオフ値の近辺の人々は、うつ病の診断基準にあてはまるかどうかは半々である。カットオフ値の近辺の人をもし二人の精神科医が診察したとしても、診断が一致しない確率が高い。ある精神科医はうつ病と診断しても、他の精神科医は違う病名(たとえば適応障害)と診断するケースが増える。
図2を見るとK6スコアが非常に高い人々(例えば総スコアが18点以上)よりも、診断が一致しにくいカットオフ近辺に位置する人々(総スコアが11点から15点あたり)の方が圧倒的に多いことがわかる。
図2は対数グラフなので頻度がスコアの増加にともなって直線的に減少しているが、実際は指数関数的に(急激)減少する。つまり世の中には典型的な重いうつ病よりもカットオフの境界付近に位置する微妙なケースの方がはるかに多いということである。
一般向けのうつ病の啓発書では、うつ病の典型例として重症例が提示されることが多い。一日中重い抑うつ気分や無力感に苛まれ、睡眠や食事もとれず、トイレに行くことすらままならない。罪責感や自殺衝動に囚われており、一人にしておくのは危険である。そんな状態が重症例である。
しかし実際はうつ病といっても軽症から重症まで様々なレベルが存在する。そして抑うつスコアが指数分布に従うという事実から考えると、重症うつ病より軽症うつ病の方が多く、軽症うつ病より診断に迷うケースの方がさらに多いということである。高血圧でも、発達障害でも、重症例よりグレーゾーン(境界域)の方が圧倒的に多いのと同じことである。
専門家同士のうつ病の診断がしばしば一致しないのも、抑うつの分布の形を考慮すると了解できる。実はこれまでの研究から、うつ病の診断は専門家同士でも一致しにくいことが報告されている。
たとえば米国精神医学会のうつ病の診断基準であるDSMを用いて専門家がうつ病診断(DSMの大うつ病に相当する)を行った場合、うつ病診断の一致率は30~70%であった(Lieblich et al. . BJPsych Open. 2015)。つまり、ある専門家がうつ病と診断したとしても、別の精神科医は半分くらいの確率で違う病名(例えば適応障害や双極性気分障害)と診断するということである。K6スコアの分布の形から見れば、うつ病診断の一致率が低いのも納得できる。
もちろんK6スコアが非常に高い、抑うつ症状の重い症例を対象にすれば、うつ病診断の一致率は高くなるだろう。しかしそういった典型的なケースはそれほど多くない。むしろ世の中にはK6の総スコアが13点前後の、診断に迷うケースの方が圧倒的に多い。そうなると専門家同士のうつ病診断の一致率も低くなる。
精神科医によって診断名が異なることを、すぐに誤診と見なす人もいる。しかし、そもそもDSMを作成した委員会が専門家によるうつ病診断の一致率は低いことを認めている。うつ病診断の一致率の低さは、誤診というよりも精神科診断基準の限界と理解した方がよいのかもしれない。
うつ病診断の難しさとは、連続的な心理現象を非連続に分類することにある。診断とはなんらかの基準にしたがって病気を正常を鑑別することであるが、連続的な現象を区別することは難しい。しかも精神科診断ではその鑑別を抑うつ症状というかなり主観的な基準によって行わないといけない。高血圧や糖尿病のように客観的な測定値によって区別するわけではない。
そういったことを考えると、この人はうつ病なのか、あるいは適応障害なのかといった、二律背反的な診断にこだわらず、世の中には様々な抑うつレベルの人が存在すると理解した方が合理的なのかもしれない。なぜなら実際の抑うつレベルは連続しているからだ。
#4 メルツアーらの先行研究
なお文献を検索したところ、抑うつ尺度の総スコアが指数分布に従うことを報告した先行論文が一つだけ見つかった。メルツアーらのグループは、2002年に英国における抑うつ尺度の総スコアの分布がy軸近傍を除いて指数分布に近似することを報告していた(Melzer D, et al, Psychol Med. 2002)
メルツアーらは、うつ病と非うつ病で抑うつスコアの分布が数理的に非連続となることを想定した。その仮説を検証するため、英国の抑うつスコアの分布の数理パターンを分析した。CIS-Rという抑うつ尺度のデータを分析したところ、その分布はカットオフ値前後でも連続しており、指数分布を示した。またy軸の近傍では指数分布を外れていた。つまり我々と同じ結果を認めたということである。
残念なことに、メルツアーはこの論文を一つ発表しただけで、このテーマの研究を止めてしまった。他の尺度でも抑うつスコアが指数分布に従うことの再現性を確認したり、分布の安定性を調べたりすることはなかった。メルツアーらがこのテーマの研究を継続しなかった理由は不明である。もしかしたら、彼らの研究仮説からすれば、抑うつスコアがカットオフ値前後でも連続して指数分布を示すという結果はネガティブデータだったからかもしれない。
現在メルツァーは精神疾患に関する研究はしておらず、環境ホルモンの疫学研究者として活躍している。抑うつ尺度の総スコアが指数分布を従う所見に関しては、先行した研究が一つ存在したことは記しておきたい。
#5 ー赤信号、みんなで渡れば怖くないー
メルツァーらの論文は2002年に発表された。筆者らはCES-Dの総スコアの分布が指数分布に従うことを2015年に発表した。しかし、2002年から2015年の間に総スコアの分布の数理パターンについて検証した論文は何も発表されていない。なお2015年以降も、筆者ら以外で抑うつスコアの分布の数理パターンについて検証した論文はない(2024年1月現在)。つまりメルツァーと我々の研究グループ以外に抑うつスコアの分布の形を報告した論文はない、ということである。
こういった事実は、精神科医や心理学者がいかに抑うつの分布の数理パターンに興味がないかを示している。筆者はこういった状況が不思議でたまらない。なぜならデータ解析を行う上で、分布の数理パターンは非常に重要だからだ。
抑うつ評価尺度を使用した疫学論文は毎月大量に発表されている。そしてそういった論文の大部分は、正規分布を想定した統計手法(t検定、因子分析、項目反応論)を用いている。しかし抑うつスコアの分布は正規分布ではなく、指数分布に従うのである(これまで一般人口の抑うつスコアが正規分布に従うという報告はない)。
「赤信号、みんなで渡れば怖くない」というのはこういう状態を指すのではないだろうか。
次回のnoteでは抑うつ評価尺度の総スコアの再現性について説明したい。
文献
1) Tomitaka S, and Furukawa TA. Mathematical pattern of Kessler psychological distress distribution in the general population of the US and Japan. BMC psychiatry 2021 21: 1-9.
2) Lieblich et al. High heterogeneity and low reliability in the diagnosis of major depression will impair the development of new drugs. BJPsych Open. 2015 1: e5–7.
3) Melzer D, et al, Common mental disorder symptom counts in populations: Are there distinct case groups above epidemiological cut-offs? Psychol Med. 2002 32:1195-201.
この記事が気に入ったらサポートをしてみませんか?