
Web3.0におけるデータサイエンス

イントロ
最近Web3.0という単語をよく耳にします。従来のインターネットに比べて何が違うのでしょうか。また、Web3.0が浸透していくと、私達の仕事はどう変わるのでしょうか。私自身、数ヶ月前まで、Web3.0について全然知りませんでしたが、Web3.0について調べてみると、ワクワクするような可能性がたくさん見えてきました。そこで、自分の頭の中の整理を兼ねて、「Web3.0におけるデータサイエンス」というタイトルで、データサイエンスという切り口で説明しようと思います。その理由は、私自身がデータサイエンティストとして企業で働いているのと、Web3.0の登場が、今後データ系人材の働き方を大きく変えるインパクトがありそうなためです。
あらかじめこの記事のサマリーをお伝えすると、
Web3.0において、データサイエンティストの活躍の場が広がりそう
Web3.0において、パーソナライズがますます重要になってくる
というものになります。この記事は、Web3.0周りの情報を調べて、自分なりに解釈してまとめたものになりますので、間違いやコメント等ありましたら、お知らせください。この記事を読んで、Web3.0×データサイエンスのワクワク感が少しでも伝わったら幸いです。
Web3.0とは
まずは、簡単にWeb3.0について解説します。Web1.0→Web2.0→Web3.0の違いは、こちらの図が分かりやすいです。

(自民党デジタル社会推進本部 NFTホワイトペーパー ATカーニー提出資料)
Web1.0では、ユーザーがインターネットを通じて、デジタルコンテンツを読む(Read)ことが中心でした。
Web2.0では、TwitterやFacebookなどの登場により、ユーザー自身がコンテンツを作成(Write)するようになり、ユーザーコミュニティが誕生しました
Web3.0では、Read、Writeに加えて、ユーザーがデジタルコンテンツを所有(Own)することが可能になります。また、コンテンツの売買等の活動は、ブロックチェーン上でなされ、原則公開されています。
具体的に、NFTマーケットの事例から、Web2.0とWeb3.0の違いを見ていきます。特に、「ユーザーがデータを所有(Own)する」と「データが原則公開」について着目します。
NFTマーケットHENの事例
例えば、Web2.0の代表であるFacebookでは、投稿したデータや友人のつながりデータはFacebookが所有することになります。そのため、Facebookがサービスを終了すると、そのデータは無くなってしまいます。
一方で、Web3.0では、NFTマーケットであるHENというサービスが参考になります。イラストや画像などのNFTマーケットとして、50万点以上のコンテンツが取引されていました。

しかし、Henは2021年の3月に公開されたものの、11月にシステム上のトラブルなどの理由で突如クローズされてしまいました。通常ならサービスが終了すると、データも消えて取引できなくなってしまいますが、Henでは、すべての取引がブロックチェーン上に記録されています。そのため、サービスクローズ後に、有志がミラーサイトを作り、ユーザーはそれ上で取引ができています。これは、Web3.0ならではの事例だと思います。
(※コンテンツ自体のデータは、IPFSというP2Pネットワーク上で保持されており、そのデータの維持も問題となっています。ただ、本記事では触れませんので、詳細が気になる方はこちらをお読みください。「Hic et Nuncの終焉とクリプトコミュニティの思想」「HENの突然死が示したNFTのリスクと解決策」)
Web3.0におけるデータサイエンス
前節で、Web3.0においては、データが原則公開されていることを説明しました。これによって、データ分析の仕方やデータサイエンティストの関わり方はどのように変わっていくのでしょうか?
こちらの「[2022] Guide to Web3 Data: Thinking, Tools, and Teams」という記事の中で、Web2.0とWeb3.0のデータのサイクルの違いが分かりやすく説明されています。
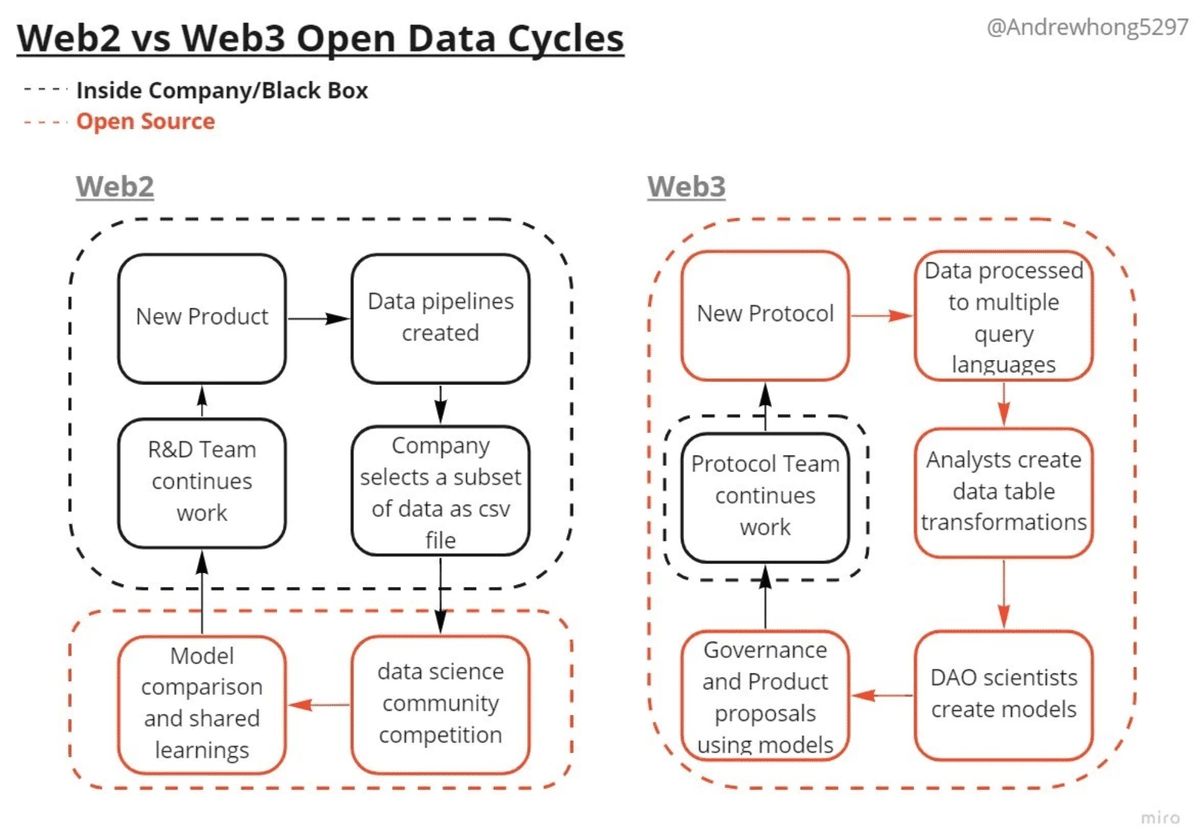
Web2におけるデータサイエンスの仕組みについて説明します。FacebookやTwitter、メルカリ、リクルートなどでは、自社サービスのアルゴリズムを強化させたい場合には、自社内のR&Dチームが取り組みます。外部の知見が欲しい場合には、データの一部を公開します。例えば、Kaggleというプラットフォームでは、各企業が賞金付きでデータセットを公開することで、世界中のデータサイエンティストが競って、賢いアルゴリズムを開発してくれます。(図の左下のオレンジで囲われた箇所)
しかし、Kaggleにデータを公開するには、社内でKaggleにデータを公開する意義を上司に説明したり、公開するデータに個人情報が含まれていないかを法務部に確認したり、手間暇がかかります。そして、公開するデータは、自社サービスの1機能の特定期間のデータになります。そのため、他の機能の改善をしたい場合は、その都度、上記のプロセスを繰り返すことになります。
一方で、Web3.0では、原則的にデータが公開されています。そのため、リアルタイムのデータを好きなように分析することができます。例えば、Dune Analyticsというベンチャー企業は、さまざまなWeb3.0の各サービスのデータを分析できるツールを提供しています。(※Dune Analyticsは従業員16名で今年2月にシリーズBラウンドで約79億円調達しています。)
こちらのダッシュボードでは、NFTマーケットのOpenSeaのデータがまとまっています。


驚くべきことに、月間の取引高やアクティブユーザー数などの情報を、誰でもSQLを書くことでリアルタイムに知ることが可能です。Dune Analyticsでは、このように各サービスのデータ分析が可能で、2万を超えるダッシュボードが作成されています。
つまり、データサイエンティストは、自身が使うサービスを自分自身で分析することが可能になります。例えば、協調フィルタリングを使って、独自のレコメンドエンジンを作ったり、自身が出品するアイテムの価格を売れやすい価格帯にするようなことも可能です。さらには、そのサービス全体の改善に対して、意見することも可能です。そして、それによって、金銭的なインセンティブを受けることも可能です。これは、Web2.0のときのようなデータが一部切り出されていた世界とは大きく異なります。
アカデミックな分野でもWeb3.0のデータを分析する研究は増えています。例えば、ネットワーク分析で著名なBarabashiらは、NFTマーケットについての研究をしています。その研究によると、NFTの取引のネットワーク上で、RichなアーティストとPoorなアーティストのクラスタができており、成功したアーティストは、少数のコレクターから不釣り合いな投資を繰り返し受けています。このようなコミュニティ分析が加速することで、今後のNFTマーケット改善にも繋がります。
このようにWeb3.0時代には、データ人材の活躍の場が増えていきそうです。例えば、次のような仕事です。
データアナリストは、Dune Analyticsのようなダッシュボード作成
アナリティクスエンジニアは、dbtなどを駆使したデータマートの設計
データエンジニアは、ブロックチェーンのデータをBigQueryなどのDBにリアルタイムに入れるストリーミング処理機構構築
機械学習エンジニアは、取引の予測モデルの構築
データサイエンティストは、メカニズムデザインの設計
今まで、オープンソースという形で、ツールが公開され、世界中の開発者が改善してきました。一方で、データは各会社内に閉じており、データサイエンティストは、その会社に所属するか、Kaggleなどを通して一部のデータを分析するしかありませんでした。しかし、今回Web3.0という形で、データ自体も公開されたことで、将来究極的には、データ分析タスクがその会社内に閉じずに、全世界のデータサイエンティストが分析して改善していくかもしれません。
つまり、Web2.0におけるデータサイエンスは、主に各会社内に閉じたデータから価値を引き出すことでしたが、Web3.0におけるデータサイエンスとは、各会社内に閉じずに、世界中の人が誰でも、リアルタイムに公開されるデータから価値を引き出すことになるかもしれません。
Web3.0におけるパーソナライズ
最後に、パーソナライズについて説明したいと思います。(ただ、こちらについては、きれいに考えがまとまっていなく、個人的思いが強く、一部論理の飛躍があるかもしれませんが、ワクワク感が伝わればと思います。)
Web3.0の大きな特徴の1つに、ウォレットアドレスによる会員登録なしでのスムーズな利用があります。従来では、各種サイトを利用するために、メールアドレスとパスワードを登録する必要がありましたが、Web3.0ではウォレットアドレス1つで、さまざまなサービスが使え、そこでの活動がそのウォレットアドレスに蓄積されていきます。

Web2.0では、TwitterやFacebookなどの各サービスごとのデータは、それらの中だけで活用されていましたが、Web3.0では各サービスでの活動を横断的に把握した上でのパーソナライズが可能になります。つまり、Web3.0が広まった世界では、Webサービスに限らず、教育や就職活動などの幅広いサービスでの活動が個々人のウォレットアドレスに蓄積されていきます。その世界では、今まで断片的に閉じていたパーソナライゼーションではなく、その人自身により寄り添ったパーソナライゼーションが可能になるかもしれません。
さて、そのようなパーソナライゼーションは、どのようにして可能になるのでしょうか。ここでは、アルゴリズムの限界と人間によるキュレーションの重要性の観点から説明したいと思います。
アルゴリズムの限界
Web3.0時代において、すべてのデータがリアルタイムに公開されて、横断的に活用できるので、すごいアルゴリズムによって、究極のパーソナライゼーションがなされると思われるかもしれません。しかし、Web3.0において、公開されるのはあくまで取引情報で、そのコンテンツ自体の情報や背景ストーリは、自動では公開されません。また、取引情報においても、どのアドレスが購入したかは分かりますが、購入した人の性別や年齢はわかりません。
例えば、NFTマーケットのOpenSeaでも、各アートがどのくらい取引されているかはデータ分析可能ですが、日本の30代男性に一番買われているアートが何かを知ることはできません。また、新規のアートがどのくらいの値段で取引されるかも、予測することは難しいです。そのアートが歴史的文脈において、非常に重要であるなら、高くなりますが、その判断をアルゴリズムがするのはおそらく難しいでしょう。

どのアドレスが買ったかは分かるが、どういう属性の人が買ったかは簡単には分からない。
このように、Web3.0といってもすべてのデータが公開されるわけではないので、そのコンテンツや作者を深く理解した人間の介在が重要になってきます。
人間によるキュレーション
もともとキュレーションは、美術館や博物館の学芸員が展示品を選んで分かりやすく展示するものでした。最近は、情報をキュレーションするというように、大量の情報から必要な情報を整理して提示することにも使われます。Web3.0においては、元来の意味どおりに展示品を選んで、何かしらのストーリーに乗せて展示することが重要になると思います。
例えば、OpenSea上では、一部のアイテムに取引が集中して、ほとんどのアイテムは、一度も取引されていないと言われています。そのようなアイテムをより多くの人に知ってもらうためには、そのアイテムや作者を心から好きで応援したい人によるキュレーションが重要です。今でも、Amazonでのレコメンドで買うことも増えていますが、Youtuberやインスタグラマー、アメトークの家電芸人による熱のこもったキュレーションによって、商品を買うことも多いです。
昔、アルというマンガサイトの「あなたを構成する5つのマンガ」という企画のデータ分析をしたことがあります。(詳細の分析はこちらに。)

こちらの企画では、64万人の方が、自分を構成する5つのマンガを入力して、Twitter上でつぶやきました。こちらも一種のキュレーションであり、友人の5つのマンガを見て、この友達が言うならこれも面白いはずだということで、マンガを購入したこともありました。
その時のデータを見ると、鋼の錬金術師は、64万人中の約1割の6万人が登録していたりと、一部の人気マンガに登録が偏っています。

一方で、数人からしか、登録されていないマンガが数千冊あり、こちらは本当にそのマンガが大好きな人が登録したものになります。そして、そのようなマンガが好きな人同士は、意気投合しやすいです。
Web3.0においては、このようなキュレーションをすることに対しても対価が払われるようなインセンティブの設計も可能になります。例えば、まだ有名でないクリエイターを初期から応援することで、そのクリエイターが有名になったときに、そのファンにも金銭的な対価が支払われます。YouTubeやインスタグラムでは、影響力がある人だけが金銭的な対価を得やすいという仕組みになっていますが、Web3.0ではそのインセンティブの仕組みが柔軟に設計され、影響力がなくても最初から応援していると対価を得られるようにすることもできます。
つまり、Web3.0において、キュレーションが加速することで、ニッチなアイテムがより発掘されて多くの人に知ってもらえるようになるのと、ニッチなアイテムが好きな人同士が知り合いになりやすくなるという、この2点がより加速されていくでしょう。これによって、より自分の興味にあったアイテムを知れたり、人々に出会えたりすることで、よりよいウェルビーイングにつながる世界がやってくるかもしれません。
まとめ
この記事では、「Web3.0におけるデータサイエンス」というタイトルで、
Web3.0において、データサイエンティストの活躍の場が広がりそう
Web3.0において、パーソナライズがますます重要になってくる
の2点を中心に説明しました。
Web3.0×データサイエンスで、もっとこんな未来がありそうなどコメントがありましたら、コメント欄でもTwitter DM(@masa_kazama)でもお知らせください。
参考資料
特に次の3つの資料を参考にしています。