
技術面接で聞かれそうな質問&回答例

はじめに
技術面接を受ける前に確認しておくといいことの「Web関係の知識」の項目を自分なりに調べまとめてみました。
説明不足や間違えている箇所があれば、ご指摘お願いします。
記事の形式は
・質問
・簡潔な回答
・説明
の順に記述しています。
事前知識
クライアント
・提供されたものを利用する立場のモノ
サーバー
・クライアントのリクエストに応じて返信するモノ
・仮想的には1台に見えるが、複数台の可能性もある。負荷を分散する為にソフトウェアを分割して、リクエストに応じて文章を作成。
クライアントはサーバに対してリクエストを送信し、サーバ側はリクエストに対してレスポンスを返します。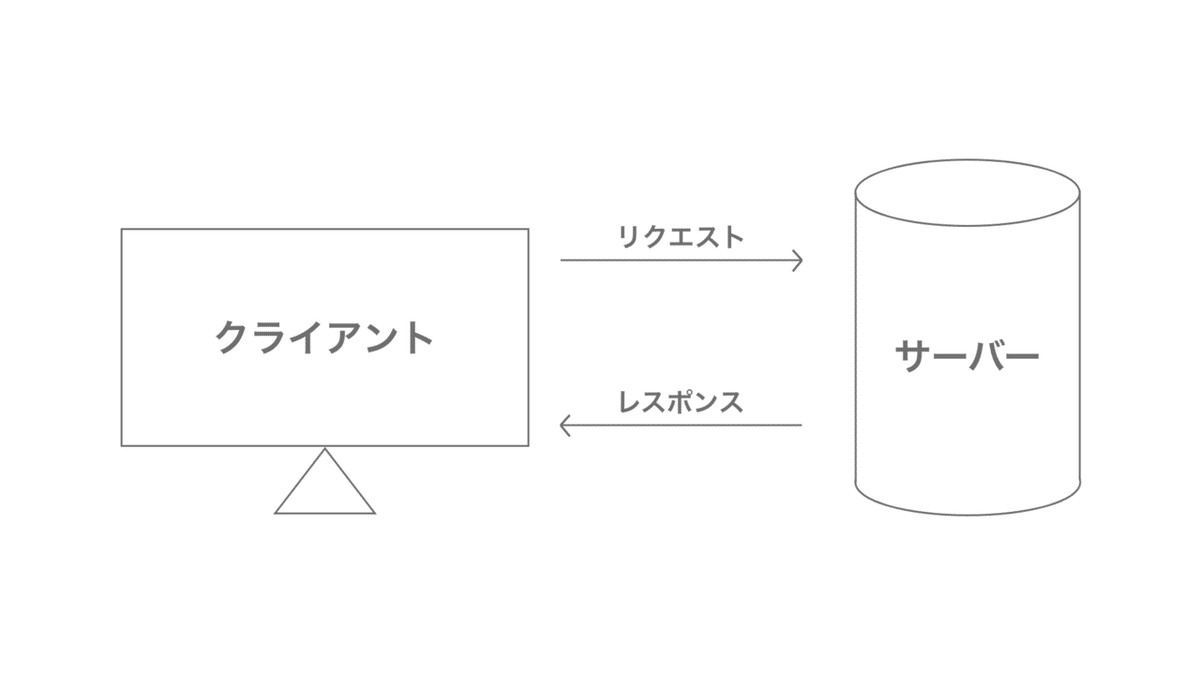
プロキシ(サーバー)
・クライアントとサーバの間で中継をする機構
・キャッシュ,負荷分散,認証等のパフォーマンスに影響する処理を担当
・パフォーマンスにかなりの影響を与えます(キャッシュ、フィルタリング、負荷分散、認証、ログ記録)
・経由する理由1:様々なログが残る(不正アクセスや誰がどういったサイトをみているかなど)
・経由する理由2:キャッシュから読み出せるのでアクセスが早い場合があります。
・経由する理由3:匿名性の確保
HTTP
webサーバーをクライアントがやりとりをする際の決まり事(プロトコル)
つまり、リクエストやレスポンスの記述法のきまりごと。
Q, httpって実際にはどのようなデータとして送られているか?
見るためにはどうする?
A, httpは主に「httpリクエスト」「httpレスポンス」に分けて通信される。
「httpリクエスト」には「リクエストライン」「リクエストヘッダー」「リクエストボディ」が含まれ、
「httpレスポンス」には「ステータスライン」「レスポンスヘッダー」「レスポンスボディ」が含まれます。
curlコマンドを使って確認してみます。
$ curl --http1.1 --get -v https://note.com/
// HTTPリクエスト
// リクエストライン
> GET / HTTP/2
// ヘッダー
> Host: note.com
> User-Agent: curl/7.64.1
> Accept: */*
// HTTPレスポンス
// ステータスライン
< HTTP/2 200
// 以下レスポンヘッダー
< content-type: text/html; charset=utf-8
< content-length: 333449
< vary: Accept-Encoding
< date: Tue, 18 Feb 2020 13:51:37 GMT
< server: nginx
< vary: Accept-Encoding
< no-cache: Set-Cookie
< x-xss-protection: 1; mode=block
< x-frame-options: DENY
< x-content-type-options: nosniff
< etag: "51689-KpRoecWGYXIwRqN9georyUMKzeI"
< accept-ranges: none
< x-cache: Miss from cloudfront
< via: 1.1 fde26f249a60f3285d817fd49c79d699.cloudfront.net (CloudFront)
< x-amz-cf-pop: NRT51-C3
< x-amz-cf-id: MQbtzbwiLj4JNIEqwJ0e4dmIqD6pwje7gfk0bD7rQ4Ccr-MtuVqAxQ==
<
// メッセージボディ
<!doctype html>
<html data-n-head-ssr lang="ja" data-n-head="lang">
...以下略各要素ごとに補足して解説します。
リクエストライン(webサーバに対してどのような処理を頼むのか)
// 左から「メソッド」「パス」「プロトコルのバージョン」
> GET / HTTP/2文章で書くと「httpプロトコルのver2に則り、リクエスト先のURI(ここではnoteのトップページのパス)にGETメソッドをリクエストした」になります。
リクエストヘッダー(リクエストについての追加情報や属性の記載)
> Host: note.com
> User-Agent: curl/7.64.1
> Accept: */*
Host:ブラウザからサーバに対して、サーバ名を送信します。複数のWebのドメインを持っている同一のサーバーに対して見分けをつけるため。
(Host:はHTTP 1.1では必須)
User-Agent:ブラウザのバージョン情報等(ここではcurlのバージョン)
Accept:ブラウザが想定する(利用可能な)MIMEのタイプ
リクエストヘッダーの下にメッセージボディが含まれる場合があります。
POST等を使用するとformに入力した情報がメッセージボディに追加されます。
HTTPレスポンス
// ステータスライン
< HTTP/2 200
// 以下レスポンヘッダー
< content-type: text/html; charset=utf-8
< content-length: 333449
< vary: Accept-Encoding
< date: Tue, 18 Feb 2020 13:51:37 GMT
< server: nginx
< vary: Accept-Encoding
< no-cache: Set-Cookie
< x-xss-protection: 1; mode=block
< x-frame-options: DENY
< x-content-type-options: nosniff
< etag: "51689-KpRoecWGYXIwRqN9georyUMKzeI"
< accept-ranges: none
< x-cache: Miss from cloudfront
< via: 1.1 fde26f249a60f3285d817fd49c79d699.cloudfront.net (CloudFront)
< x-amz-cf-pop: NRT51-C3
< x-amz-cf-id: MQbtzbwiLj4JNIEqwJ0e4dmIqD6pwje7gfk0bD7rQ4Ccr-MtuVqAxQ==
<
// メッセージボディ
<!doctype html>
<html data-n-head-ssr lang="ja" data-n-head="lang">
// 以下略...ステータスライン(webサーバ内の処理結果を表示)
// ステータスライン
< HTTP/2 200 「HTTP/2」で「200」が返ってきたと書いてあります。
この「200」は「ステータスコード」と呼ばれており、特定の HTTP リクエストが正常に完了したどうかを示します。
この場合の「200」はリクエストが成功した場合に返すコードです。
別の質問項目で補足してステータスラインの話をします。
レスポンスヘッダーは説明が長く、覚える必要がないと思うので、その都度調べるなどして対応して頂けたらと思います。(webサーバの情報がいろいろ書かれています。)
下で若干解説しています。
メッセージボディ
HTMLなどのデータを格納
Q, POSTメソッドとGETメソッドは、実際にhttpの通信の中身だとどう違うか?
A, URLに記載してリクエストするか、bodyにデータを埋め込むか
ブックマーク出来るか出来ないか
POST
POSTの定義
POST メソッドは、[ ターゲットリソースが,自前の特有な意味論に則って,要請内に同封された表現を処理する ]ことを要請する。
引用:https://triple-underscore.github.io/RFC7231-ja.html#section-4.3.3
指定したリソースに対して実装した機能に従い、送信された情報を処理をするメソッドです。
リクエストボディ部にデータ含めリクエストします。
例をあげると
・アプリ上で新規ユーザ登録をする
・テキストや記事を投稿する
などですね。
GET
GET定義
GET メソッドは、[ 現在の,ターゲットリソース用に選定される表現 ]を転送するよう要請する。 GET は、情報を検索取得する主たる仕組みであり,ほぼすべての処理能 最適化の力点が置かれる所である。 よって、誰かが[ HTTP を介して識別できる何らかの情報を検索取得する ]ことについて話すとき,たいていは GET 要請を為すことを指している。
引用:https://triple-underscore.github.io/RFC7231-ja.html#section-4.3.1
指定されたリソースの表現を返すようにリクエストするメソッドです。
URL部分にクエリを追加しリクエストします。
例をあげると、ブラウザで情報を検索する際には、このGETメソッドを使っています。
そして大きな特徴としてブックマークができるかどうか?があります。
・POSTはブックマークができない
・GETはブックマークができる
POSTの場合ブックマークからURLが開かれると、ボディーにデータを含める事が出来ない為。
GETだとURLにクエリを保存するので、ブックマークからURLを開く場合にも処理結果を再現できる。
Q, レスポンスヘッダってなんのためにある?
2系と3系と4系と5系の使い分けは?
A, レスポンスヘッダーにはレスポンスの各種の状態など、詳細な情報が記載されています。
代表的なレスポンスヘッダー
content-type: どんな種類のデータなのか
connection: 接続状況
location: リクエストと違う場所からリソースの取得を指示。リダイレクト先
cache-controlやpragma: キャッシュ制御
...などなど
他にもたくさんあるのでこちらを参考にしてみてください。
A, HTTPリクエストが正常に完了したかを示しています。
1.情報レスポンス (100–199),
2.成功レスポンス (200–299),
3.リダイレクト (300–399),
4.クライアントエラー (400–499),
5.サーバエラー (500–599)
参考:https://developer.mozilla.org/ja/docs/Web/HTTP/Status
Q, リダイレクトはどんな風に起きている?
A, サーバ側がステータスコード3xxを返した場合にリダイレクトが行われる。リダイレクト先にはLocationに示されている情報を元に行われる。
* Connection state changed (MAX_CONCURRENT_STREAMS == 100)!
< HTTP/2 301
< location: https://www.example.com
< content-type: text/html; charset=UTF-8
< date: Sat, 22 Feb 2020 09:55:17 GMT
< expires: Mon, 23 Mar 2020 09:55:17 GMT
< cache-control: public, max-age=2592000
< server: gws
< content-length: 222
< x-xss-protection: 0
< x-frame-options: SAMEORIGIN
< alt-svc: quic=":443"; ma=2592000; v="46,43",h3-Q050=":443"; ma=2592000,h3-Q049=":443"; ma=2592000,h3-Q048=":443"; ma=2592000,h3-Q046=":443"; ma=2592000,h3-Q043=":443"; ma=2592000
<
<HTML><HEAD><meta http-equiv="content-type" content="text/html;charset=utf-8">
...以下略Q, キャッシュって何が起きている?キャッシュのコントロールは、配信側でどのように行なっているか?
A, サーバから取得してきたリソースを保存する機能の事
再度アクセスした際に、保存したデータを使用し、読み込みを早くする為です。
レスポンスヘッダー内にキャッシュをコントロールする為の記載がある。
キャッシュに関するレスポンスヘッダー例
Cache-Control:ブラウザやキャッシュサーバーに対して、キャッシュの動作や有効期限を指定するためのものです。
Expires:キャッシュの有効期限を指定します。
他にも様々なヘッダーがあるので必要に応じて調べてみてください。
Q, RESTとは何か?
A,アーキテクチャスタイルの一種。
REST(REpresentational State Transfer)
直訳すると「(リソース)の表現可能な状態の転送」という感じです。
要はリソースを中心とした考え方です。
原則
・ステートレスなクライアント/サーバプロトコル
->セッションなどの状態管理は行わない。
・すべての情報(リソース)に適用できる「よく定義された操作」のセット
->POST,GETなどのHTTPメソッド
・リソースを一意に識別する「汎用的な構文」
->URL,URIなど
・アプリケーションの情報と状態遷移の両方を扱うことができる「ハイパーメディアの使用」
->情報の中に別の情報や状態を含める事ができる(HTMLまたはXMLを使用)
参考:https://ja.wikipedia.org/wiki/Representational_State_Transfer#%E5%8E%9F%E5%89%87
RESTを理解する上で、重要な「リソース」「状態」「表現」について
リソース
・処理や振る舞いではなく、名詞で表現できるもの
・例として、画像や商品など
状態
・リソースの状態
・商品だと在庫一覧、画像だとアップロード前の画像など
表現
・通信でやり取りされるのは、リーソスでそのものはなくリソースの表現
・表現の例として、「HTML」「JSON」「XML」「PNG」など
REST における「リソース」とは名詞のみの「リソース」と、その「状態」を合わせたものと見做しても良いのかもしれません。
実際に昔作ったAPIを例として、説明します。
RESTではないAPIの例
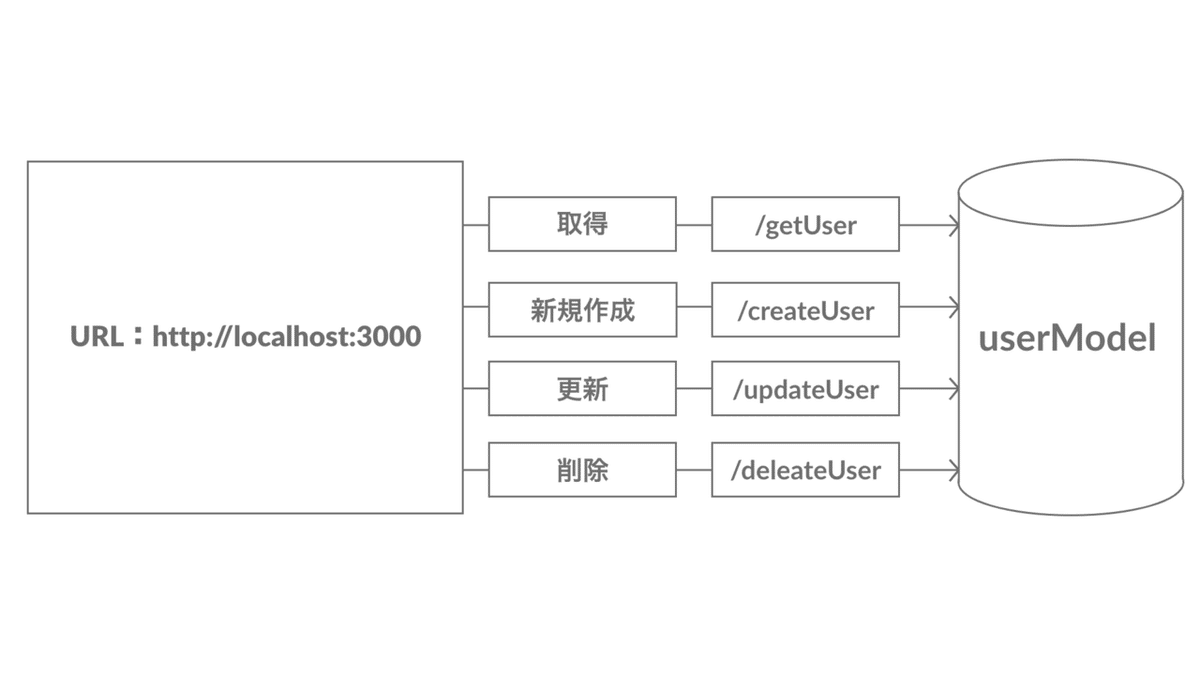
URLと処理が対応するシステムであるが、RESTの設計思想的には間違いである。getやcreateなどの動詞は使わないのが基本。
RESTなAPIの例

このようにリソース(この場合はUser)を中心として各処理を対応づけます。
メリット
リソースへの操作を限定する事(CRUD)で統一性のある設計が可能
ステートレスにすることで、スケーラビリティが向上
Q, セッションは何か?cookieとsessionはどのように連動しているか?
A, cookieを利用した一連の処理の始まりから終わりまで
Cookie
・一言で言うと、クライアントに保存された情報
仕組みを簡単に
・HTTPレスポンスのヘッダを利用して、クライアントにCookieに保存するよう送ります。
・Cookieがあればその情報を常にサーバー側に伝えます。
セッション
ECサイトを例にして説明します。
httpはステートレス(通信で状態を持たない)なのでECサイトで商品をカートに入れる、決算などの一連した処理ができません。
そこでcookieを使用します。
処理(セッション)の流れ
1.ブラウザからECサイトにアクセスする。
2.サーバ側はアクセスしてきた、ユーザにセッションIDを対応づけクライアント側に送信
3.サーバ側から送信されたセッションIDをcookieに保存
4.クライアント側で商品をカートに入れる(セッション変数に商品を記憶)
5.情報に変更があるときには、セッションIDを元に更新等を行う。
参考
この記事が気に入ったらサポートをしてみませんか?