
深層強化学習トレーディング①:準備編

こんにちは、magito(@regolith1223)です。約1年ぶりのnote投稿になります。今回は「深層強化学習のトレーディングへの応用」というテーマについて、筆者がこれまで調査・検証してきた内容をまとめて紹介したいと思います。
パート①では、本稿のキーワードである「深層強化学習」について平易に説明したのち、トレーディングに応用するうえでの利点や課題について考えます。パート②では、先行研究を参考にトレーディング用の強化学習アルゴリズムを構築し、Python3/ChainerRLライブラリを用いてデモ実装します。そしてパート③では、仮想通貨市場(今回はビットコインFX)でトレーディングを行い、実装したアルゴリズムの運用パフォーマンスについて検証・考察します。
まだまだ実用には程遠いフェーズですが、個人的にはとても興味深く、好奇心を刺激するような面白いテーマだと思っています。ぜひエンタメ的な視点で楽しんでいただければ幸いです。
※本稿は「トレーディングで利益を上げるための手法やテクニック」を指南するものではありません。本稿記載のアルゴリズムやソースコード等をトレーディングに使用することにより生じた、いかなる損失についても一切責任を負いかねます。ご利用は「自己責任」でお願いします。
1. はじめに
筆者が人工知能という言葉を認知したきっかけは、2016年3月、「Google DeepMind社の囲碁プログラム"AlphaGo"が世界ランカーの囲碁棋士を4勝1敗で打ち破った」というニュースでした。
AlphaGoは、プロ棋士の対局データを「お手本」として学習したのち、自己対戦によるトレーニングを高速に繰り返すことにより、驚異的なスピードで上達していきました。そして、当時は「囲碁でコンピュータが人間に勝つには少なくとも今後10年はかかる」と言われていたにもかかわらず、それをあっという間に成し遂げてしまいました。
AlphaGoの打ち手がなぜ勝利につながったのか理解できない
数千年先の未来の囲碁を見せられているようだ
といった当時の解説者のコメントがとても印象深く、SF映画を観ているかのような気分にさせられたのをよく覚えています。
人工知能に関する話題がニュースやネット記事などでよく取り上げられるようになったのは、たしかこの頃あたりからだったと思います。
ここで、人工知能のもたらす未来に関する有名な予測として「2045年問題/技術的特異点」を紹介しておきます。
米国の未来学者Ray Kurzweil氏によると、このままコンピュータの計算性能が向上していくと、いずれはコンピュータ(人工知能)の知性が全人類のそれを上回るといいます。そうなると、「ヒト」の生み出した「ヒトを上回る知性」が、「さらにそれを上回る知性」を生み出すというループが始まります。いったんこのループに突入すると、テクノロジーは人類なしで進化していき、そのスピードが指数関数的に発散するため、その向こう側はまったく想像もつかない世界になるそうです。このような劇的変化にいたる境界は技術的特異点(Technological Singularity ; シンギュラリティ)とよばれ、このシンギュラリティに到達するのが2045年あたりと推測されることから2045年問題とよばれています。
シンギュラリティへの到達時期については定かではなく、100年後かもしれませんし、ひょっとすると数年後かもしれません。しかし先ほど紹介したAlphaGoの件を踏まえると、(コンピュータが人類を超えたという意味では)囲碁などのボードゲームにおいては、すでにシンギュラリティに到達したと言えるかもしれません。

ところで話は変わりますが、筆者は仮想通貨のシステムトレード(自動売買、BOTトレード)という奇怪な趣味を2年ほど続けています。情報収集によくツイッターを利用するのですが、その中でこのような記事に出会いました。
タイトルの通り、深層強化学習という人工知能に関連する技術をmmbot(指値注文を駆使する自動売買プログラム)に応用できないか、という趣旨の記事でした。
どうやら深層強化学習というものは、例えばテレビゲームのような「連続した意思決定や行動選択を最適化する問題」を解くことを得意とする手法のようで、先ほどのAlphaGo(とその後継バージョン)にも組み込まれているとのことでした。
以下は深層強化学習を用いてスペースインベーダーを攻略する動画です。
このような動画を眺めていると、株・為替FX・仮想通貨などのトレーディングにおいても(囲碁やインベーダーと同じくゲームの類と考えると)AlphaGoのように自ら戦略を学習して強くなっていく自動売買プログラムを作ることができるのでは?という気がしてきます。
これはスンゲー面白そうです。ワクワクしてきました。
もしも、トレーディングの世界でシンギュラリティを起こすことができたら?
そんなわけで、「深層強化学習のトレーディングへの応用」というテーマについて、もう少し詳しく調べてみることにしました。
2. 基本概念
本題に入るまえに、前提となるいくつかの概念について簡単に紹介しておきます。「専門知識ゼロからでも最後まで読める」程度の前提を共有することが目的ですので、数式を使うほど深入りはせず、平易な説明にとどめます。そんくらいは知ってるよ、という方は読み飛ばして3章に進んでいただいてOKです。
また、筆者の理解不足により、説明内容に誤りや不適切な表現があるかもしれません。機械学習の専門の方で気づきがありましたら、ご指摘いただけますと幸いです。
2-1 言葉の体系
人工知能、AI、機械学習、ディープラーニング…昨今ではこのような言葉に日常でもよく出会うようになりました。これらは似通った文脈で使われることが多いため混同しがちですが、言葉の包含関係を整理すると以下のようになります。

(1)人工知能
本稿に登場する言葉の中でもっとも広い概念が人工知能(Artificial Intelligence ; AI)です。AIという略称で呼ばれることが多いですね。
人工知能(技術)
言語の理解や推論、問題解決などの知的行動を人間に代わってコンピューターに行わせる技術
出典元:人工知能 – Wikipedia
世の中には「知的行動を人間に代わってコンピューターに行わせる技術」はいろいろとあります。たとえば、「IF文とセンサーで温度を制御する冷蔵庫」や「自動掃除機ルンバ」などから「世界ランクのプロ棋士を打ち破る囲碁プログラム」に至るまで、(上記の定義にしたがうと)一応はすべてが人工知能であるといえそうです。それくらいザックリとした概念です。
世間一般ではSF映画などのイメージが先行しているため、「人間の代わりにいろいろやってくれるすごいロボット」というように一元的に捉えられがちですが、現実に存在する人工知能とよばれるモノの中身は、上記のように、そのベースとなる技術や手法により大きく異なるようです。
(2)機械学習
人工知能を実現するための技術の一つが機械学習(Machine Learning ; ML)です。機械学習は、その名の通り、機械(コンピュータ)を学習させる技術のことです。機械学習の技術を用いて、コンピュータに大量のデータを与えて処理させると、データの中から有用な特徴や法則性を見つけ出し(学習)、ある特定のタスクを効率的あるいは高精度に実行(推論)するプログラムをつくることができます。
機械学習にもさまざまな種類があり、例えば以下のように分類することができます。
①アルゴリズムによる分類
機械に学習させるといっても、学習のために与えられたデータを「どのように処理・計算するか」は人間が決めてやる必要があります。その方法のことをアルゴリズムといいます。比較的古くから使われているアルゴリズムとしては、例えば、サポートベクターマシン(SVM)やランダムフォレストとよばれるものがあります。
そして、近年になり著しく発展しているのが、生物の脳活動の仕組みを模倣したニューラルネットワーク(Neural Network ; NN)です。ニューラルネットワークは、いくつかのニューロン(Node)からなる層(Layer)が複数結合した構造をしています。これを何層もうまく組み合わせると、人間の能力により近い、高度で複雑な学習・推論ができるようになります。このような何層にも重なる「深い」ニューラルネットワークのことをディープニューラルネットワーク(Deep Neural Network ; DNN)といい、これを機械学習に用いる手法を深層学習(Deep Learning)といいます。

②教師データの有無による分類
こちらも学習方法による分類といえますが、「データをどのように与えるか」という観点での分類になります。教師あり学習は、学習データと正解ラベルをセットで与えてパターンを学習させる方法です。その一方で、教師なし学習は、学習データのみを与えて学習させる方法です。強化学習については、本稿では重要なので以下で少し詳しく説明します。
2-2 強化学習
強化学習(Reinforcement Learning ; RL)は、連続した行動や意思決定を最適化するための手法です。教師あり学習では、学習データとセットで正解ラベルを与えますが、強化学習では、正解ラベルの代わりに、意思決定や行動選択に応じて報酬を機械に与えます。良い行動を選択したときにはプラスの報酬(ご褒美)を、悪い行動を選択したときにはマイナスの報酬(罰)を与えるというイメージです。このフィードバックにより、機械は「もらえる報酬ができるだけプラスに大きくなるような意思決定や行動選択の仕方」を学ぶようになります。
強化学習の枠組みでは、エージェントとよばれる行動主体が、ある環境Eの中におかれているという状況を考えます。(例えば、「囲碁」という環境にいる「棋士」というエージェント、「ステージ1-1」という環境にいる「マリオ」というエージェント、などをイメージしてみてください。)
環境Eでは時間がT={0,1,2,3...}というように離散的に流れており、時間ステップtごとに以下の①〜④を繰り返します。
①時刻tにおいて現在の状態s[t]を観測する。
②状態s[t]をもとに方策π(後述)に従い行動a[t]を選択する。
③状態s[t]と行動a[t]に応じて環境Eから報酬r[t]を受け取る。
④状態s[t]と行動a[t]に応じて状態s[t+1]に遷移する。(そして①に戻る)
このように、各時間ステップtにおいて、現在の状態s[t]のみに依存して行動a[t]が決定される過程をマルコフ決定過程(Markov Decision Process ; MDP)といいます。
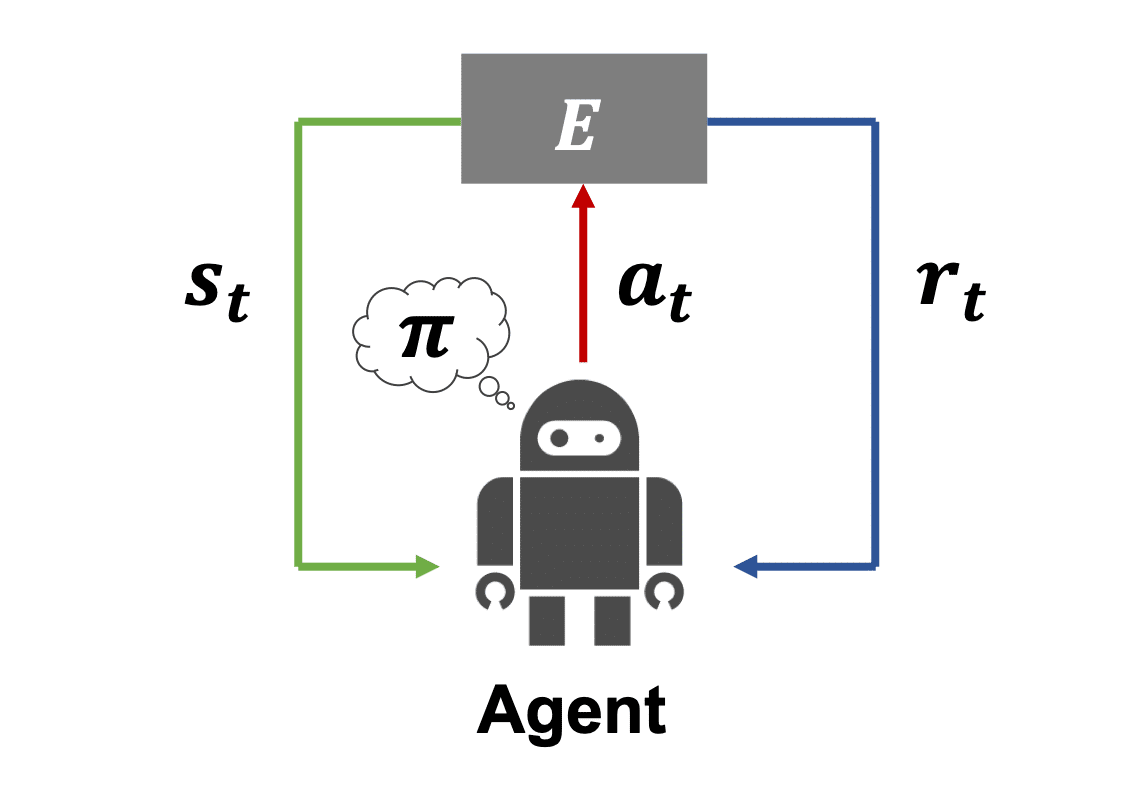
MDPの中でエージェントは、報酬r[t]に基づいて状態s[t]や行動a[t]の良し悪しを評価することにより、「どういう状態でどういう行動を選択すれば報酬につながるか?」を学ぶことができます。いわばノウハウやコツのようなものを経験から獲得していくわけです。このような一連の行動を選択する方針のことを方策πといい、このようなサイクルの中で方策πを繰り返し更新して改善していくことをトレーニングといいます。以上が、強化学習の大まかな流れになります。
「方策πの改善」という処理をコンピュータ上で実行するためには、エージェントの取りうる状態や行動の良し悪し(価値)を数値として定量的に表現する必要があります。強化学習においては、状態や行動の価値はベルマン方程式(Bellman Equation)とよばれる数式により計算されます。
価値の計算においては、ある状態に遷移したり、ある行動を選択したときに「即時に」得られる報酬だけでなく、その先に得られる見込みの報酬も考慮されるため、エージェントは目先の利益だけを追うのではなく、将来を見据えて大局的な視点で動くことができるようになります。
強化学習問題の簡単な例として、「ホウキを手のひらの上に乗せ、なるべく長い時間のあいだ落とさずにバランスをとるゲーム」を考えます(以後、ホウキゲームとよびます)。例えば、エージェント→手のひら、状態s→ホウキの角度とその方向、行動a→手のひらを動かす距離とその方向、報酬r→ホウキを落とさず保持している累計時間、などと定義すると、このホウキゲームは強化学習の枠組みで攻略することができます。(ちなみに、ホウキゲームと相似の問題は、強化学習の世界では"Cart Pole"として有名です)
2-3 深層強化学習
冒頭で述べたように、今回のキーワードとなる技術は、深層強化学習(Deep Reinforcement Learning ; DRL)でした。これは、先ほど紹介した機械学習の手法のうち、深層学習と強化学習の2つを組み合わせたものになります。
強化学習の流れの中に、「状態や行動の良し悪しを評価する」というステップがありましたが、その評価結果を今後の行動選択に活かすためには、「どういう状態、どういう行動が、どれだけ報酬につながるか(どれだけ価値があるか)」というような情報をエージェントが記憶しておく必要があります。
従来の強化学習、例えば、オーソドックスな手法の一つであるQ学習(Q-learning)では、エージェントの方策や価値に関する情報を保存する、いわば「頭脳」にあたる部分において、各状態sと各行動aの組み合わせごとの価値をテーブル方式の関数(Q-Table)で表現していました。
このように単純な形式だった関数を、人間の「頭脳」の構造により近いDNNに置き換えたのが深層強化学習になります。DNNに置き換えることにより、エージェントの取りうる状態や行動の数が膨大になる場合でも価値や方策を表現できるようになり、また、より複雑で高度な方策を学習することもできるようになりました。

深層強化学習というカテゴリの中にも、さまざまなアルゴリズムが存在します。例えば、先ほどのQ学習をDNNに置き換えた、Deep Q-Network (DQN)というアルゴリズムはとても有名です。現在でもDQNを改良した派生アルゴリズムはたくさん考案されており、本稿の次回パート以降でも実装例としてDQNの派生アルゴリズムを使います。
深層強化学習の仕組みについてもっと具体的に知りたいという方は、まずは以下のサイトを読んでみることをおすすめします。強化学習(Q学習、DQN)について、例題を用いて具体的かつ丁寧に説明されているので、とても分かりやすいです。
3. トレーディングへの応用
前置きが長くなりましたが、ここからが本題です。
先ほど説明したとおり、強化学習では「どういう状態でどういう行動を選択すれば報酬につながるか?」を機械に学習させることができます。人間に置き換えると「あるタスクの練習を繰り返して上達していく」というプロセスに対応しますが、このような構造は日常生活の中にもたくさん存在します。例えば、野球やサッカー、チェスや囲碁、テレビゲーム、車の運転...などなどです。
では、トレーディングはどうでしょうか?例えば、裁量トレーダーは「現在/過去の価格」や「自分のポジション」のような状態sを観測して、「買い?売り?ノーポジ?」といった具合に行動aを選択します。もし、選択した行動が将来の価格の変動方向に整合していれば「利益」という正の報酬r>0が得られ、逆の場合は「損失」という負の報酬r<0が得られます。
賢明なトレーダーは、このような経験を積む中で「どういうタイミングでどういう売買判断を行えば勝てるか?負けるか?」を学び、有用なトレーディング戦略を習得することができます。
このように考えると、トレーディングというものは、強化学習(*1)の枠組みと相性が良さそうに思えます。
以降では、便宜的に下記のような設定をマルコフ決定過程M(π)と仮定し、これを強化学習ベースのトレーディングに適用することを前提に話を進めます。
状態s:最新価格の1ステップ前からの変化量(*2)
行動a:買いポジションL、売りポジションS、ノーポジションN
報酬r:1ステップ後に得られるポジション損益
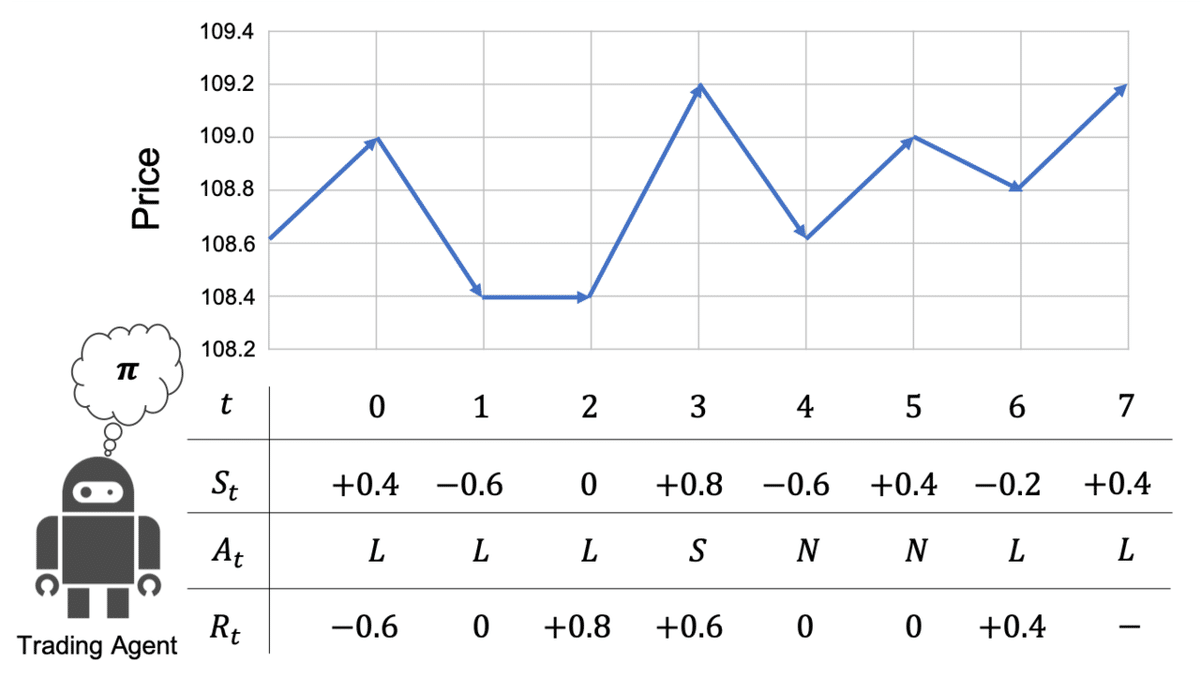
*1:以降は、深層強化学習の「強化学習としての側面」を中心に言及するため、基本的には強化学習という表記に統一します。とくに「深層学習としての側面」について言及する場合のみ、深層強化学習と表記します。
*2:実用的には過去の変化量も現在の状態sに含めて時系列{+0.4, -0.6, 0,...}のように入力するのが望ましいと考えられますが、今回の説明では簡単のため省略します。
4. メリット
では、仮にトレーディングへ強化学習をうまく応用することができた場合、どのような恩恵が期待できるでしょうか?
ここでは、文献[1]などで示されている2つの重要なトピックに着目し、筆者のbotterとしての視点から解説してみます。
(1)トレーディングの"End-To-End"最適化
システムトレーダー(botter)とよばれる人々は、価格チャートを一日中眺め続けたり、手動で発注ボタンを押したりすることはめったにありません。ほとんどすべての取引行為を自動売買プログラム(BOT)に任せているからです。
とはいえ、利益の源泉となる予測指標や市場の歪みなどは、トレーダー本人が価格データなどの情報を「自分の目で見て」調べる必要がありますし、それを実際のトレーディング利益に変換するための戦略についても「自分の頭で考えて」構築する必要があります。さらには、そのトレーディング戦略をプログラミングしてBOT化するのも本人です。
このように、システムトレーダーといえども生身の身体を酷使しています。一般的には「自動売買」というと「不労所得」というイメージが強いですが、その実態は過酷な労働を強いられるブラックな職種といえます。
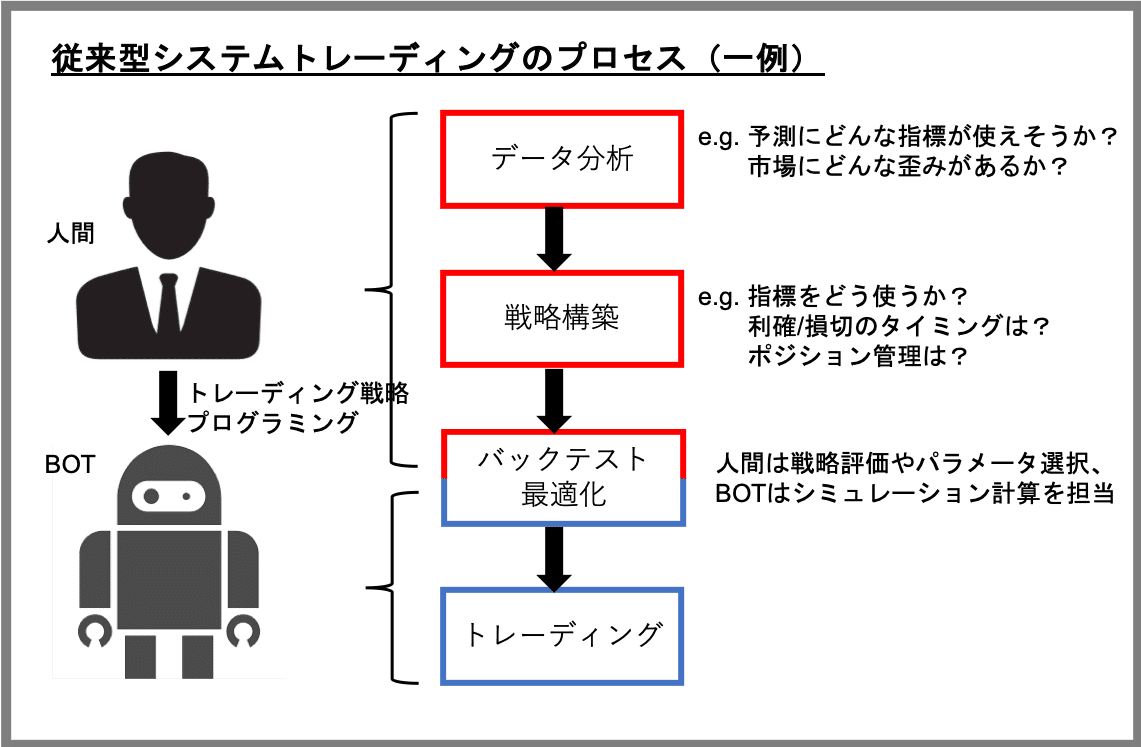
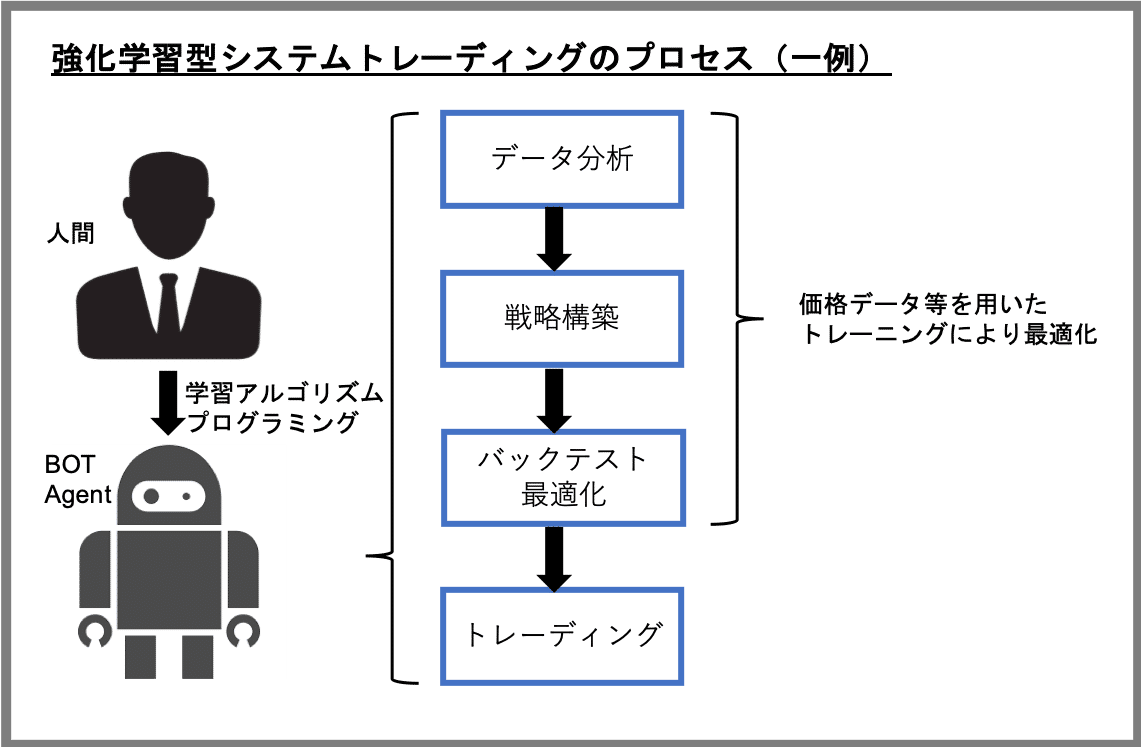
このようなプロセスに強化学習を適用した場合、これまで人間の担当してきたタスクについてもBOTに任せることができるかもしれません。
強化学習の枠組みにおいて、例えば、報酬rとして「トレーディング損益」を与えるように学習アルゴリズムを設計すると、エージェントは「トレーディング損益の総和」を最大化するように方策の改善を進めます。つまり、最初から「利益を実現する」ことを目標として(個別のステップを踏むことなく)トレーディング戦略を直接最適化することになります。したがって、従来のプロセスでいうところの「データ分析」「戦略構築」「バックテスト/パラメータ最適化」というようなタスクについても学習対象に含めることができるため、従来の開発プロセスを"End-to-End"で自動化できることになります。
とはいえ、その場合も人間の役割が完全になくなるわけではなく、むしろ、もっとも重要な「学習アルゴリズムの設計」を担当する必要が出てきます。例えば、「どのようなデータをどのような形で与えるか」「どのように状態、行動、報酬を定義するか」などの検討は、エージェントがトレーディングを適切に学習できるか否か、ひいては強化学習によるトレーディングで実際に利益を上げられるか否かに直結するクリティカルなステップであるといえます。このステップを適切に実施するためには、機械学習技術に関する専門スキルだけでなく、「トレーディング」という行為そのものに対する、より深い理解が必要になると思われます。
(2)ブルーオーシャンの開拓
世の中の投資家/投機家は、さまざまな時間軸や戦略により株・為替・仮想通貨などの売買を行います。例えば、数週間〜数年のスケールで売買を行う長期投資家がいれば、数秒〜数分の間しか同じポジションをもたないスキャルパーとよばれる投機家もいます。極端な例としては、数マイクロ秒〜数ナノ秒(10億分の1秒)というごく短期間で高速売買を行う高頻度取引(High Frequency Trading ; HFT)とよばれる手法も存在します。
長い時間軸になるほど、「世界情勢」や「企業の経営状況」などのファンダメンタル情報も価格変動に影響する傾向があります。したがって、長い時間軸において有用な戦略では、そのような価格以外の外部情報も含めた総合的な売買判断が必要となることが多いため、人間(裁量トレーダー)が得意とする領域といえそうです。
その一方で、ごく短い時間軸において有用な戦略は、まったく異なる性質をもちます。例えば、裁定取引(Arbitrage)とよばれる戦略では、ブローカー間や商品間の価格差を利用して利ざやを稼ぎますが、そのような価格差(裁定機会)はほんの一瞬しか生じません。また、マーケットメイク(Market Making ; MM)とよばれる戦略の中には、買い/売りの両方に指値注文を提示してスプレッド利益を稼ぐタイプがありますが、指値注文とマッチングする成行注文の数量は限られているため、自分の指値注文を(他者をさしおいて)いかに有利に約定させるかという点が重要となります。
どちらの短期戦略についても、ほとんどの場合は数値データ以外の情報を必要とせず、ロジック自体もシンプルです。その一方で、いわば「椅子取りゲーム」の性質を帯びており、シビアな高速性・瞬発力が求められます。生身の人間の思考・判断のスピードには生物的限界があるため、こちらはBOT(システムトレーダー)が得意とする領域といえます。
このように、トレーディングの時間軸や戦略によって、同一市場の中でもプレイヤーの棲み分けがされていますが、ある特定のカテゴリで似たようなプレイヤーが増加すると、一人あたりの利益の取り分は小さくなると考えられます。その一方で、だれも手をつけていない領域(ブルーオーシャン)が市場のどこかに存在すれば、それを初期に見つけたプレイヤーは大きな利益を得られます。
以上を踏まえると、トレーディングで利益を上げるにあたっては、「差別化」や「優位性」という観点がとても重要であるといえます。それらはプレイヤーによっては、「アイデア」や「データ分析力」かもしれませんし、あるいは「プログラミング能力」や「通信速度」かもしれません。
深層強化学習ベースのトレーディング戦略は、プログラム(BOT)として実行できるため、当然ながら、人間よりも高速に売買することが可能です。それに加えて、深層学習の恩恵により、(適切に適用できれば)従来のシストレロジックよりも複雑で高度な推論処理が可能になることが期待されます。このような深層強化学習トレーディングBOTの有する「機械的な高速性 × 複雑で高度な推論」という得意分野のかけ算が大きな優位性・差別化となり、市場のどこかにあるブルーオーシャンの開拓を可能にするかもしれません。
5. 課題
以上のように魅力的なメリットが考えられる一方で、強化学習ベースのトレーディングで成功を収めるためには、いくつもの課題を克服する必要があります。そして、この課題克服こそが実用への橋渡しとなるもっとも重要なフェーズであると思います。前項3-1と同様、いくつかの重要な課題に着目して解説していきます。
(1)カーブフィッティング
カーブフィッティングは従来のシストレにも共通する問題であり、トレーディング戦略の最適化にあたっては常につきまといます。
例えば、強化学習を用いてテレビゲームを攻略したい場合は、ある特定の環境(例えば、スーパーマリオブラザーズのステージ1-1)で繰り返しトレーニングを行い、最終的にクリアできればOKです。
その一方で、強化学習を用いてトレーディングを攻略したい場合は、ある特定の環境(例えば、ある一週間のビットコイン価格の1分足データ)で繰り返しトレーニングを行い、あらゆる値幅を完璧に拾える戦略を作成できたとしても、実用上はなんの意味もありません。なぜなら、その戦略はトレーニングに使用した環境に対して過剰に最適化されており、他の環境(例えば、次の一週間のビットコイン価格の1分足データ)では使い物にならないからです。この問題をカーブフィッティング(過学習)とよびます。この場合、エージェントは「戦略を学んだ」のではなく「その期間の価格変動を丸暗記しただけ」といえます。
(2)外乱・ランダム性
強化学習の適用に成功しているテレビゲームと、トレーディングのあいだには決定的な違いがあります。それは、トレーディングにはエージェントの行動により制御できない外乱成分が多く存在し、さらにそのランダム性が大きいという点です。
ここでいう外乱とは、最新価格(LTP)や板情報(LOB)のような時系列的に逐次観測される市場データを指すことにします。
ChainerRLはDQN実装が簡単(DNN使わんQ学習ならChainerすら不要)。強化学習は状態のランダムさに弱い。例えば降ってくるボールをリフティングする問題だと初期射出(落下?)速度が固定なら結構学習してくれるが、初期速度がランダムだと途端にファビョりだす。初期だけでこれなので途中の外乱はさらに。 https://t.co/viv8wyTHS1
— AKAGAMI 卍 (@akagami_v2) January 9, 2019
学習の難しさ
例えば、3-1で設定したM(π)のとおり、「1ステップ前からの最新価格の変化量」を状態sとして定義した場合、ある時刻tでどのような行動a[t]を選択したとしても、次の時刻t+1で観測する状態s[t+1]は行動a[t]に左右されません。また、この場合の状態sの時間変動にはランダム性があるため、エージェントのとった行動a[t]が良かったのか悪かったのか、状態s[t], s[t+1]や報酬r[t]などから正しく評価できない(つまり、学習が進まない)おそれがあります。
現実のトレーディングで例えます。どれだけ適切な売買判断を常に下すことができたとしても、10000回連続して勝つということはありえません。たまたまランダムな要因により価格変動がポジションと逆行して負けてしまう、ということは往々にしてあるからです。そして、このような場面が多すぎると、実際は良い判断なのに悪い判断として棄却してしまったり、逆に、実際は悪い判断なのに良い判断として採用してしまい、トレーディングの上達を阻害する原因になります[3]。トレーディングを強化学習の枠組みにあてはめた場合も、これと同様の問題が起こりえます。
制御の難しさ
別の観点で考えてみます。トレーディングは、先ほどのホウキゲームで例えると「暴風が吹き荒れる中でホウキを落とさずに手のひらでバランスをとり続ける」ようなものです。次の瞬間にどの方向から来るかわからない突風(価格変動)を想定しながらホウキの角度を制御するのは至難の技です。
このような過酷な環境に対応するためには、「一見ランダムに見える風向きから法則性を見つける(価格予測)」「想定外の方向から突風が吹いてもホウキを落とさないような立ち回りをする(リスク管理)」というような方策学習を促すアルゴリズム設計が必要になるかもしれません。
(3)部分観測性
ホウキゲームを「ホウキの柄だけしか見えない条件」でうまくプレイできるでしょうか?通常の「ホウキ全体が見える条件」に比べ、はるかに難しいと思います。このように、時刻tにおいて状態sの情報の一部しか観測できない過程を部分観測マルコフ決定過程(Partially Observable Markov Decision Process; POMDP)といいます。
トレーディングでは、エージェントはせいぜい現在価格(または直近の数ステップの時系列)や保有ポジションに関する情報くらいしか観測できませんが、実際は、過去の時系列、市場参加者、ファンダメンタル情報など、値動き(将来の状態s')に影響する要因はさまざまにあります。トレーディングを理想的なMDPとしたい場合は、これらの情報をもれなく状態sに含めるべきですが、それは現実的ではありません。したがって、トレーディングにおいては、MDPではなくPOMDPの問題として解く方が現実に即しているといえます。
DQNは画像から全ての情報が手に入るマルコフ決定過程(MDP)な問題に対して有効な手段となります。一方、仮想通貨の値動きはテクニカルだけでなくチャートからは読み取れないファンダの影響を受けるため部分観測マルコフ決定過程(POMDP)となります。
— ohshima (@ocjapan) January 23, 2019
強化学習におけるPOMDPの解法については、現在も研究が進められていますが、まだまだ発展途上のようです。本稿では、POMDPに有効とされる手法の一例として、再帰型ニューラルネットワーク(Recurrent Neural Network ; RNN)を用いた深層強化学習を次回パート以降で紹介します。
(4)獲得戦略のブラックボックス性
深層強化学習により獲得したトレーディング戦略は、「どのような指標を見て、どのような基準で売買しているのか」というロジックの部分をトレーダー本人が直接確認できないという問題があります。
従来のシストレでは、人間のトレーダーが戦略を構築し、それをプログラミングによりソースコードへ落とし込みます。この場合は、戦略の運用中に市場環境が変化したとしても、トレーダー本人が戦略(のロジックやパラメータ)を直接チューニングすることにより対処できる可能性があります。また、チューニングの際も、自分で記述したソースコードを改変するだけでOKです。
しかし、深層強化学習ベースのトレーディングの場合、トレーニングにより獲得した戦略そのものは、従来のBOTのようにPythonなどのソースコードではなく、ニューラルネットワーク上の「重み行列W」の中に数値の羅列として記述されています。この数値の羅列の意味を人間が直接解読することは不可能です。したがって、獲得戦略はブラックボックスであり、取引履歴などから間接的に推測することはできても、その中身を直接的に確認したり、チューニングしたりすることはできません。
これは「AlphaGoの打ち手を解説者(人間)が説明できなかった」という事例と本質的には同じ問題であるといえそうですね。

6. まとめ
深層強化学習ベースのトレーディングには、非常に魅力的なメリットが期待できる一方で、実用に向けては厳しい課題をクリアする必要があり、テレビゲーム攻略のように一筋縄ではいかないことが分かりました。
この現実を踏まえた上で、次回のパート②では、トレーディング用の学習アルゴリズムを具体的に検討し、Python/ChainerRLという深層強化学習ライブラリを用いてデモ実装します。
以上になります。最後までお読みいただきありがとうございました!
参考文献
オンライン記事
[1] "Introduction to Learning to Trade with Reinforcement Learning", Denny Britz, WILDML, 2018/2/10
[2] "深層強化学習はビットコインのmmbotに応用可能か?", AKAGAMI卍, AKAGAMI TOKYO, 2018/12/13
[3] "トレーディングの統計モデリング", UKI, note, 2019/7/17
書籍
[4]"強化学習", 森村哲郎, 講談社, 2019/5/23