
集計作業のお悩みをAIで解決/第4話「文章自由回答データを効率的に集計する”教師なし学習AI”とは」

前回は、意見や感想などの文章で記述された自由回答データの集計についてご紹介しました。今回はAIを活用して効率化するプロセスをご紹介します。
1.「教師なし学習AI」で行われる処理
今回もアンケートで得られた「作りたてコーヒーサービスがあったら利用したいか」という質問に対する以下のような文章での自由回答データを使用します。前回はアフターコーディングを人の手で行う方法をご紹介しましたが、今回はAIでアフターコーディングを効率的に行う過程を解説していきます。

今回は「教師なし学習」という種類のAIを活用して、分類分けを行います。ここでは大きく分けて3つの処理を経て文章のデータを分類します。
※教師なし学習の定義やAIの分類については第3話 をご参照ください。
(1)文章分解:形態素解析などで文章を細かく分解
(2)ベクトル化:分解した文章を「複数の数値の組」でデータ化
(3)クラスタリング:データの類似度によりグループ分けを行う

文章分解、ベクトル化、クラスタリングとそれぞれの工程では、様々な手法が研究されています。マクロミルでは毎回の集計データごとに、最適なクラスタリングになるよう都度様々な手法の中から選択し組み合わせをしています。
今回の「作りたてコーヒーサービス」の自由回答データの集計で使用する手法は下記の通りです。
(1)文章分解:「JUMAN++」※1
(2)ベクトル化:「BERT」※2
(3)クラスタリング: 「GMM」※3
※1「JUMAN++」
京都大学黒橋・河原研究室で開発されている日本語の形態素解析システム。Wikipedia内の単語を辞書に含んでいるので固有表現にもある程度対応できるのが特徴。
※2「BERT(Bidirectional Encoder Representations from Transformers)」
2018年10月にGoogleの論文により発表された自然言語処理モデル。従来の一般的な自然言語処理モデルと比較し、「to」のような文と文の関係を結ぶ単語や、「not」のような否定表現を解釈することが出来る。
※例えば「高い」という語を"物理的に上にある"という意味と"価値が大きい"というような複数の意味での使われ方を捉えるなどの解釈が可能。BERTを利用するためには大量のデータでの「教師あり学習」を、大きな労力と時間をかけ事前学習したモデル(Pre-trained models)を構築する必要があるが、ここでは京都大学や東北大学などが公開している事前学習モデルを活用。
※3「GMM」
確率論や統計学で用いられる確率分布の1つである「ガウス分布」の線形を重ねて表されるモデル。「平均」「分散」で表現した1つのパラメータが複数のガウス分布のどれに属するかを推定する。
「作りたてコーヒーサービス」のデータを使ってこの手法を使用した場合、イメージとしては下記のような処理が自動で行われます。

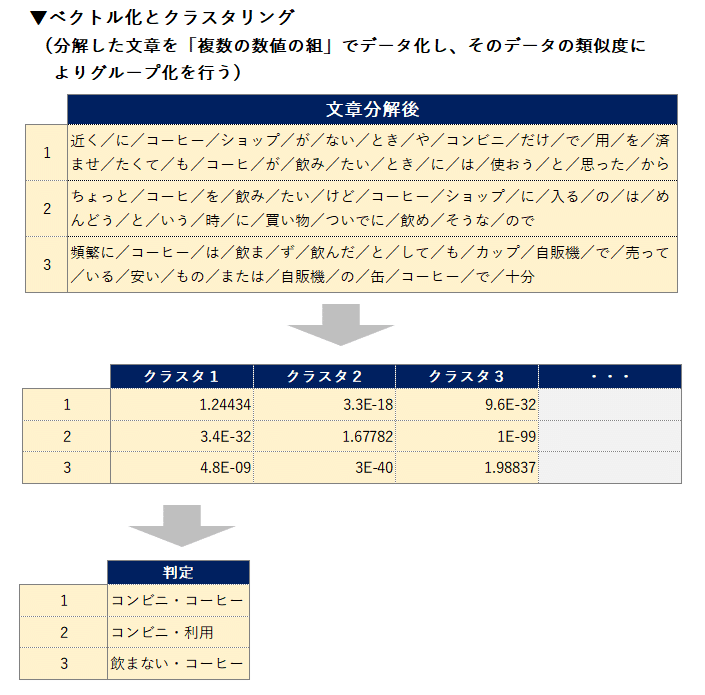
2.「教師なし学習AI」を実行した後のデータ確認
このように今回、「作りたてコーヒーサービス」の意見データについて先ほどご紹介した教師なし学習のモデルを実行したところ下記のような結果が得られました。

AIによるクラスタリングで、ある程度意味が考慮された文章に分けられています。しかし、この結果ですべて意図通りの、100%正確な分類分けが出来るということではありません。
AIがつけたクラスタの名前は代表的な単語をAIが出してくれており、このままでは意味が通らないことがあるため、中に入っている回答を確認しながら代表的な名前を付けていきます。また、人間からみたら同じ意味を持つ内容が複数のクラスタに分かれているような場合があります。上記の図では「コーヒー・好きでない」「コーヒー・飲まない」など同じ意味のクラスタが複数出来ているため、ここだけは人の目で確認しまとめていきます。
AIを使って分けた後にこのような作業を経ることで、意味のある分類分けが可能となります。

但し、一度に多くの意見を分析に掛けてしまうと、教師なし学習AIを実行したとしても、クラスタの数が増え、結果の確認が大変になります。そのため、一部を抜粋したデータ(例えば1万人の回答のうち、1~2千人の回答など)でAIを用いたクラスタリングに分け、統廃合や名前の変更などの微調整を行って整えた後、そのデータを教師あり学習の教師データとして登録し、その後に残りのデータを予測させる方法を取ることもあります。

3.「教師なし学習AI」を使った集計に適しているデータ
今回ご紹介した集計方法は、大量にある文章データの場合にAIの効果が期待できます。サービスや商品への意見、従業員満足度調査での回答、またアンケート以外にも購入した商品の口コミ(レビュー)の文章などは特に1人の回答が長く書かれる傾向にあり、第3話でご紹介した手作業での集計作業を行うと非常に時間と手間がかかってしまうケースに役立ちます。
マクロミルでは自由回答データの中身や量に応じて使用する手法を組み合わせ、効率的かつ最適な集計手法をご提案しています。文章で書かれたデータの取り扱い、集計にお困りの場合はぜひご相談ください。
第4話までは「アフターコーディング」と呼ばれる自由回答の集計手法をご紹介してきました。最終回となる5話ではアフターコーディング以外の自由回答の活用事例をご紹介していきます。次回もぜひご覧ください。
【筆者紹介】

【連載 全5話】集計作業のお悩みをAIで解決