
【3年ごと見直し】プライバシー強化技術(PETs)のゆくえ

本稿のねらい
ことの発端
以前の記事に書いたとおり、2024年6月27日、個人情報保護委員会(PPC)は、第292回個人情報保護委員会配布資料として、個人情報保護法(APPI)に関し、いわゆる3年ごと見直し(第二次3年ごと見直し)にかかる「中間整理」(本中間整理)を公表し、かつ、パブコメを開始した。締切は7月29日。
本中間整理の内容について整理していたところ、2024年7月22日付けで、Googleが進めてきた "Privacy Sandbox" という、3rd Party Cookie廃止に伴い、それに代わる新たな広告技術につき、「新しいアプローチを提案」すると発表した。
つまり、Googleは、3rd Party Cookieを廃止するのではなく、「Chrome に新しい機能を導入し、ユーザーがウェブ閲覧全体に適用される情報に基づいた選択を行い、いつでもその選択を変更できるように〔する〕」とのことである。
これだけだとよくわからないのだが、UKの競争当局であるCompetition and Markets Authority (CMA) のウェブサイトを見ると少しわかる。
つまり、Googleは、3rd Party Cookieを廃止するのではなく、Chromeユーザーが3rd Party Cookieを保持するか否か選択できる機能をChromeに導入することを提案したようである。
On 22 July 2024, Google announced that it is changing its approach to Privacy Sandbox. Instead of removing third-party cookies from Chrome, it will be introducing a user-choice prompt, which will allow users to choose whether to retain third party cookies. The CMA will now work closely with the ICO to carefully consider Google’s new approach to Privacy Sandbox. We welcome views on Google’s revised approach, including possible implications for consumers and market outcomes.
これはUKのInformation Commissioner’s Office (ICO) やその所管法令との関係のためではなく、UKの "the Competition Act 1998" における "abuse of a dominant position" (日本法的にいえば優越的地位の濫用)に相当する懸念があるためとのことである(Google’s Privacy Sandbox commitments)。
つまり、Googleが3rd Party Cookieを廃止することにより、次の3つの問題が生じるリスクがあるとのことであり、それを踏まえてアプローチを設計しなければならないようである(八方塞がり)。今回のGoogleやCMAの発表を見るに、特に3つ目のChromeユーザーの自己決定権のようなものが重視されたように思われる。
①Googleと3rd Partyの非対称性が競争を歪める
"distort competition in the market for the supply of ad inventory and in the market for the supply of ad tech services, by restricting the functionality associated with user tracking for third paies while retaining this functionality for Google" (訳) 広告市場やアドテク市場において、Googleにはユーザー追跡機能が残るのに対し、3rd Partyはユーザー追跡機能が制限され、これにより競争が歪められる
②Googleによる自社サービス等の優先が競争を歪める
"distort competition by the self-preferencing of Google’s own advertising products and services and owned and operated ad inventory" (訳) Googleのサービス等を優先することにより競争が歪められる
③ユーザーの選択を否定する権利をGoogleに与えることになる
"allow Google to deny Chrome web users substantial choice in terms of whether and how their Personal Data is used for the purpose of Targeting or Measurement and delivering advertising to them." (訳)Chromeユーザーの個人データがターゲティングや測定のため、または広告配信に使用されるかどうか、どのように使用されるかにつき、ユーザーの実質的な選択をGoogleが拒否できるようになる
その他諸々細かい点については、下記CMAのウェブサイトを参照のこと。
【参考】これまでの流れ

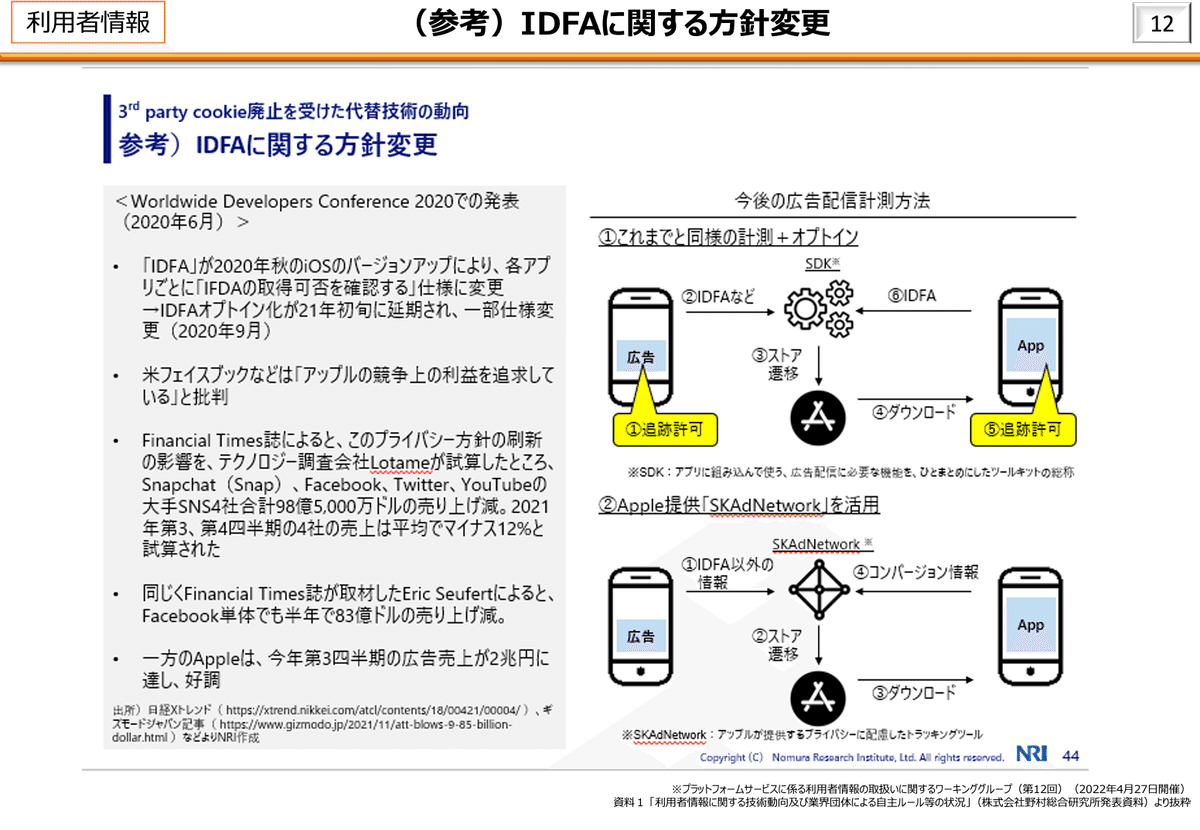
若干話が逸れたが、本中間整理と関連するのはPrivacy Sandboxであり、Privacy-Enhancing Technologies ("PETs") である。つまり、個人データの利活用は図りたいものの、官民問わずデータやプライバシー保護強化の流れがあり、利活用が進まないところを、PETsにより突破するという潮流があるようなのである。
近年、GAFAをはじめとしたテック企業によってPETsの研究開発・実用化が進められている。特にGoogle Chromeの3rd Party Cookie廃止、iOS/Androidの広告識別子(IDFA/AAID)取得時のオプトイン化といったデジタルマーケティング界隈の環境変化が圧力となり、広告技術は基盤から見直しに迫られている。こうした施策のひとつとしてPETsを活用したプライバシー保護の強化が講じられている。
本中間整理では、「4 その他」としてちょろっと言及がある程度で、PETsに関して大きく触れられていないが、次に見るように、経済界からはデータ利活用の目的で、またデータやプライバシー保護に寄与する団体からはプライバシー保護の目的で、PETsの法制化又はガイドライン化など、第二次3年ごと見直しにおいて一定の手当てをするよう求められている。
特に経済界の方は例によって声が大きいため、ひょっとするのではと思い、本稿を書いている。
4 その他
上記のほか、プロファイリング(本人に関する行動・関心等の情報を分析する処理)、個人情報等に関する概念の整理、プライバシー強化技術(「PETs」: Privacy Enhancing Technologies)の位置づけの整理、金融機関の海外送金時における送金者への情報提供義務の在り方、ゲノムデータに関する規律の在り方、委員会から行政機関等への各種事例等の情報提供の充実などの論点についても、ステークホルダーの意見やパブリック・コメント等の結果を踏まえ、引き続き検討する。
【参考】あるべき論について概説したもの
第二次3年ごと見直しにおける検討状況
興味深いのは、一般社団法人日本情報経済社会推進機構(JIPDEC)はOECDガイドラインやGDPR等の国際的な趨勢に沿って、PETsを個人データの利活用に対する防波堤として作用させる意図だと思われるところ、新経連や経団連はそれと真っ向から反する形で、一定のデータ処理により個人識別性が排除されプライバシー侵害のリスクが低減された場合、第三者提供規制を緩和することを求めている点である。

「ヒアリング資料(一般社団法人日本情報経済社会推進協会)」7頁

「個人情報保護法の見直しについて(新経済連盟)」10頁

「個人情報保護法の3年ごと見直しに対する意見(日本経済団体連合会)」7頁

「個人情報保護法の3年ごと見直しに対する意見(日本経済団体連合会)」14頁
かねてより、経団連は、「DXを推進するうえでは、個人の安心・安全の確保を前提としつつ、様々な主体間で個人情報を含むデータを連携・共有しながら新たな価値を創出することが欠かせない」として規制緩和を求めてきた(2023年度規制改革要望No. 34. 個人情報・仮名加工情報の第三者提供規制の緩和)。
【参考】仮名加工情報の利活用について概説したもの
しかし、既に識者により正しく論じられているように、プライバシー保護の観点から必要なのは処理される個人データの「最小化」(GDPR第5条第1項(c))と安全管理措置の一環としての匿名化や仮名化(同第6条第4項、第25条第1項参照)である。
PETsを導入したからといって第三者提供が許されてよいということになるわけではない。(中略)
PETsを導入することで規制を迂回できるのではなく、合法な処理においてPETsを利用できるということであり、その際のPETsの意義は安全管理措置上の安全性強化にある。日本法における真の課題は、PETsが利用できないことではなく、個人データを統計量に集計する利用に対して第三者提供の制限が過剰な規制となっているところにある。
筆者は、以前の記事において、仮名加工情報(これはGDPRにもある概念(同第4条第5号))の共同利用(これはAPPI独自概念(同第41条第6項、第42条第2項、第27条第5項第3号))により、事実上、PETsを用いて行おうとしている「秘密計算」や「統合学習」(統合分析)のような、複数のエンティティの間で、個人データを連携・共有し、データを掛け合わせることで、さらなるデータの利活用・業務効率化を図ることが可能であると示した。
この考えは変わっていないものの、仮名加工情報を共同利用することで「複数のエンティティの間で、個人データを連携・共有し、データを掛け合わせること」はやはり本来想定されていない使われ方というイメージ(法には反していないがコンプライアンスに反する的なイメージ)であり、第二次3年ごと見直しにより法制化又はガイドライン化など一定の手当てがされるのが望ましいと考えている。
そこで、この機にPETsについて簡単にまとめるのが本稿のねらいである。
PETs
PETsに関しては、OECDのPAPERである "EMERGING PRIVACY ENHANCING TECHNOLOGIES CURRENT REGULATORY AND POLICY APPROACHES" (OECD PAPERS) に詳しい。
以下では、OECD PAPERS に沿ってPETsを概説するが、ところどころわかりづらいため、適宜別の資料を参照する。
なお、2022年のコミュニケ("The 2022 Communiqué")においてもPETsの重要性にはスポットライトが当たっており、PETsの利用推進を追求することや技術基準や認証制度の策定を要請することが謳われていたのに、我が国は何をやっていたのだろうか。
11. A particular focus amongst the G7 should be on privacy enhancing technologies (PETs).
(訳) G7において特に焦点を当てるべきなのは、プライバシー強化技術(PETs)である。
25. Privacy-enhancing technologies (PETs) – such as trusted research environments, federated learning, differential privacy, zero knowledge proofs, secure multiparty computation and homomorphic encryption – help organizations implement or improve data protection by design through processes which mask or transform personal data to reduce its identifiability.
(訳) PETsには、信頼可能研究環境、統合学習、差分プライバシー、ゼロ知識証明、セキュアマルチパーティ計算、同準型暗号等が含まれ、個人データをマスキング又は変換して識別可能性を低減するプロセスを通じ、データ保護バイ・デザインを実施・改善するのに役立つ。
26. In recognition of these benefits we, as the G7 data protection and privacy authorities, will seek to promote the responsible and innovative use of PETs to facilitate data sharing, supported by appropriate technical and organizational measures.
(訳) G7 データ保護及びプライバシー当局は、適切な技術的及び組織的措置の支援を受け、データ共有を促進するための責任ある革新的なPETsの利用推進を追求する。
27. In tandem with taking action ourselves to support organizations to use PETs in compliance with data protection and privacy law, we call on industry to develop the technical standards and certification schemes needed to give organizations confidence that they are using PETs responsibly and in compliance with the law.
(訳) データ保護/プライバシー法を遵守してPETsを使用する組織を支援するために行動することと並行して、組織がPETsの使用に責任を持ち法律を遵守しているという確信を与えるために必要な技術基準と認証制度を策定するよう産業界に要請する。
PETsとは
PETsは、国際的には特に目新しい概念ではなく、2002年頃には存在していたようである。その頃は次のような概念であった。
Privacy-enhancing technologies (PETs) commonly refer to a wide range of technologies that help protect personal privacy. Ranging from tools that provide anonymity to those that allow a user to choose if, when and under what circumstances personal information is disclosed, the use of privacy-enhancing technologies helps users make informed choices about privacy protection.
(訳) プライバシー強化技術(PETs)とは、一般的に、個人のプライバシー保護に役立つ幅広い技術を意味する。匿名性を提供するツールから、個人情報を開示するかどうか、するとしていつどのような状況で開示するかをユーザーが選択できるようにするツールに至るまで、ユーザーは、PETsの利用により、プライバシー保護について十分な情報を得た上で選択することができる。
現時点では、次のように定義されており(OECD PAPERは2023年3月公表)、基本的には下記USの定義(2022年6月公表)によっているものと思われる。
Privacy-enhancing technologies (PETs) are a collection of digital technologies and approaches that permit collection, processing, analysis and sharing of information while protecting the confidentiality of personal data. In particular, PETs enable a relatively high level of utility from data, while minimising the need for data collection and processing.
(訳)プライバシー強化技術(PETs)は、個人データの機密性を保護しながら、データの収集・処理・分析・共有を可能にするデジタル技術と方法の集合体。特に、PETsによれば、データの収集・処理の必要性を最小限にとどめつつ、データから比較的高いレベルの有用性を引き出すことが可能。
Terminology: Privacy-enhancing technologies (PETs) refer to a broad set of technologies that protect privacy, which are within the scope for this RFI. We are particularly interested in privacy-preserving data sharing and analytics technologies, which describes the set of techniques and approaches that enable data sharing and analysis among participating parties while maintaining disassociability and confidentiality.
(訳) プライバシー強化技術(PETs)とは、プライバシーを保護する広範な技術を指し、本 RFI の対象範囲である。特に、プライバシーを保護するデータの共有・分析技術に関心があり、これは、分離可能性と機密性を維持しつつも、参加当事者間でのデータの共有・分析を可能にする、一連の技術とアプローチを説明するものである。
Such technologies include, but are not limited to, secure multiparty computation, homomorphic encryption, zero-knowledge proofs, federated learning, secure enclaves, differential privacy, and synthetic data generation tools.
(訳) これらの技術には、秘匿マルチパーティ計算、同準型暗号、ゼロ知識証明、統合学習、セキュアエンクレーブ、差分プライバシー、合成データ生成ツール等が含まれるが、これらに限られない。
ポイントは2点で、①プライバシー保護、つまりデータ収集等処理を最小化しながら(処理されるデータやデータ処理は少なければ少ないほど個人にとっては望ましい)、②複数エンティティの間においてデータの共有と分析を可能にし、それによりデータの有用性を高めることができる点にある。
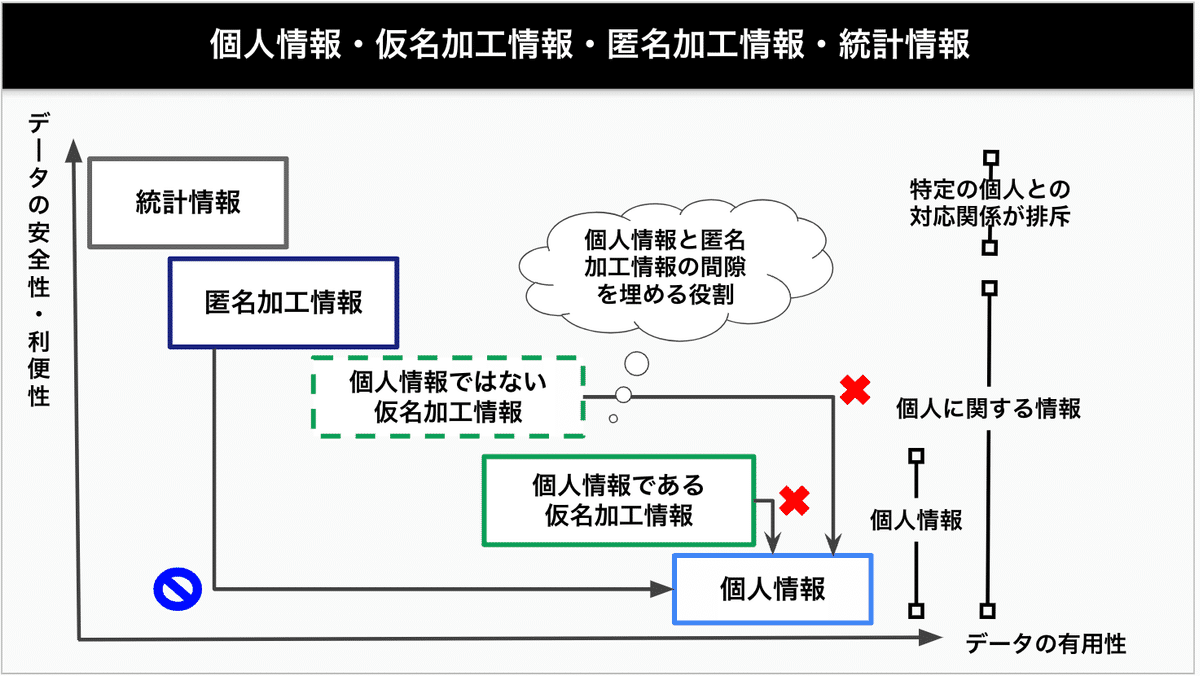
※常識的にはこのようにデータの安全性と有用性は相反する
しかし、PETsは「特効薬」ではないし、法的フレームワークに置き換わるものでもない。あくまで法的フレームワークの中で機能する技術を提供するだけである。
PET should not be regarded as “silver bullet” solutions. They cannot substitute legal frameworks but operate within them, so that their applications will need to be combined with legally binding and enforceable obligations to protect privacy and data protection rights.
PETs are often addressed explicitly and/or implicitly in countries’ privacy and data protection laws and regulations through: legal requirements for privacy and data protection by design and by default; requirements for de-identification, digital security and accountability; and/or regulatory mandates to PEAs to further promote adoption of PETs.
(訳) PETsは、各国のプライバシー/データ保護に関する法規制の中において 明示的/黙示的に扱われることがある。例えば、プライバシー・バイ・デザインやプライバシー・バイ・デフォルト、非識別化、デジタルセキュリティや説明責任に関する法的要件、PETsの適用をより一層促進するための当局への法的義務を課すなど。
※ "PEAs" = "privacy enforcement authorities"
*Data protection by design and by default ("DPbDD")
PETsの種類
OECD PAPERによれば、PETsは次の4つのカテゴリと12の種類に区別される(同 pp.15)。★を付けたものが有名どころ。
1. Data obfuscation tools(データ難読化)
①Anonymisation / Pseudonymisation(匿名化/仮名化)
②Synthetic data(合成データ)
③Differential privacy(差分プライバシー)★
④Zero-knowledge proofs(ゼロ知識証明)
2. Encrypted data processing tools(暗号化データ処理ツール)
⑤Homomorphic encryption(準同型暗号)★
⑥Multi-party computation(マルチパーティ計算)
⑦Trusted execution environments(TEE)(信頼可能実行環境)
3. Federated and distributed analytics(フェデレート・分散分析)
⑧Federated learning(統合学習)★
⑨Distributed analytics(分散分析)
4. Data accountability tools(データアカウンタビリティツール)
⑩Accountable systems(説明責任)
⑪Threshold secret sharing(しきい値秘密分散)★
⑫Personal data stores / Personal Information Management Systems(個人データ保管/個人データ管理システム)

以前の記事で紹介した「秘密計算」は、暗号化+複数エンティティの持ち寄りだったことから、準同型暗号としきい値秘密分散やマルチパーティ計算の組み合わせのようなイメージである。
このあたりに関しては一般社団法人データ社会推進協議会「秘密計算の活用例〜秘密計算を利用した安全な組織間でのデータ活用への期待〜」においては「『秘密計算』をデータを秘匿しながら処理できる技術の総称と捉え、⽅式や要素技術は⾔及しない」とされているように(同10頁)、内訳を探るのは野暮かもしれない。
【参考】なんか見つけた
差分プライバシー (Differential privacy)
ポイントは、分析結果を得るに際して、データに一定量のノイズを加えることで、個々のデータポイントを特定しづらいように加工(難読化)する点にある。
Differential privacy: These techniques make small changes (add noise) to the raw data to mask the details of individual inputs, while maintaining the explanatory power of the data. The idea is that small changes to individual records can securely de-identify the inputs without having a significant impact on the aggregated results. Noise can be added at the time of data collection (distributed) or at the central location before the data are released (centralised) (Royal Society, 2019[15]).
(訳) これらの技術は、データの説明能力を維持しながら、個々の入力データの詳細を見えないよう、生データに軽微な変更を加える(ノイズを加える)。個々の記録に軽微な変更を加えることで、集計結果に重大な影響を与えることなく、入力データを安全に非識別化できる。ノイズはデータ収集時(分散型)に加えることもできるし、データがリリースされる前に中央で加えることもできる(中央集権型)。
Differential privacy is relevant as a PET because it provides data subjects with some protection of deniability in cases where someone attempts to re-identify released data. Noise introduced into the dataset should not alter any large-scale analysis but makes any individual data less reliable and protective for the data subjects. Policy makers may need to provide guidance about the amount of noise that must be introduced to protect the privacy of data subjects.
(訳) 差分プライバシーは、リリースされたデータが再識別されようとする場合に、データ対象者が一意に定まらず保護されるため、PETと関連性がある。データセットに加えられたノイズは、大規模な分析に影響を与えることはないが、個々のデータの信頼性を低下させ、データ対象者を保護する。立法者は、データ対象者のプライバシー保護のために加えなければならないノイズの適正な量について、指針を示す必要があろう。

差分プライバシーには、次のような課題・限界があるとされている(OECD PAPER pp.19)。普通に考えて当たり前な課題である。
差分プライバシーではノイズが追加されるが、生データのまま残るものもある
どの程度のノイズを追加するか合意された基準が存在しない
準同型暗号 (Homomorphic encryption: HE)
ポイントは、データを暗号化したまま復号することなく、徹頭徹尾、暗号化されたデータで計算・分析を行うことができる点である。データ難読化とは対照的に、使われるデータ自体は変更がされない特徴がある。暗号化が鍵になるとされている(OECD PAPERS pp.16)。
Homomorphic encryption (HE): HE computes over encrypted data that the organisation never can see. The data subjects locks the data (with a key only they have) before passing them on to the data processor. The processor can then perform simple (but increasingly complex) calculations over the encrypted data to extract an encrypted result that can only be unlocked with the data subject’s key.
(訳) HEは、暗号化されたデータに対して計算を行うため、データの中身を見ることができない。データ主体は、データ処理者にデータを渡す前に、データ主体だけが持つ鍵でデータを暗号化する。データ処理者は暗号化されたデータに対して簡単な(しかし次第に複雑化する)計算を行い、暗号化された結果を取り出します。
HE can enhance privacy and data protection because it allows data to remain encrypted while in use. This allows data subjects or controllers to maintain strict confidentiality over their data in cases where previously it needed to be visible for use in analysis. It thus reduces the security risks of data in use. As HE applications appear, policy makers will need to assess how the processing of encrypted personal data used in these models should be treated under the law.
(訳) HEによりデータを暗号化したまま使用できるため、プライバシー/データ保護を強化に資する。これにより、(中略)データの厳秘性を維持でき、データ使用時のセキュリティリスクを軽減することもできる。HEの登場により、立法者は、暗号化された個人データの処理が法律のもとでどのように扱われるべきか評価する必要がある。
Homomorphic computation methods are used in other PETs such as multi-party computation (MPC, see below) and are widely trusted and increasingly deployed. However, homomorphic computation on its own is much less efficient than standard data analytics. Consequently, it takes longer and costs more in computation power. This trade-off between efficiency and privacy means that homomorphic encryption is only optimal for cases where the privacy benefits can justify the increased costs of computation and analysis. For now, most applications are done at a small scale. However, that could change with a stronger policy push for encrypting data in use and as the process becomes more efficient.
(訳) HEはマルチパーティ計算(MPC)など他のPETsでも使用されており、広く信頼され導入されることも増えている。しかし、HEは、標準的なデータ分析よりもはるかに効率が悪く、結果として計算時間が長くなり、計算コストも高くなる。効率性とプライバシーのトレードオフは、プライバシーベネフィットが計算・分析のコスト増を正当化できる場合にのみHEが選択肢となることを意味する。現在、ほとんどのアプリケーションは小規模で行われている。しかし、使用時のデータを暗号化することを政策的に強く推し進めることにより、プロセスがより効率的になれば、変わる可能性はある。

ここで興味深いのは "policy makers will need to assess how the processing of encrypted personal data used in these models should be treated under the law." とされている点である。
ちなみに、APPIのもとでは、「個人に関する情報」は暗号化等により秘匿化されているかどうかを問わないとされており(ガイドライン通則編2-1)、暗号化されてもなお「特定の個人を識別することができるもの(他の情報と容易に照合することができ、それにより特定の個人を識別することができることとなるものを含む。)」(APPI第2条第1項第1号)に該当すれば、個人情報(個人データ)である。
「個人に関する情報」とは、氏名、住所、性別、生年月日、顔画像等個人を識別する情報に限られず、ある個人の身体、財産、職種、肩書等の属性に関して、事実、判断、評価を表す全ての情報であり、評価情報、公刊物等によって公にされている情報や、映像、音声による情報も含まれ、暗号化等によって秘匿化されているかどうかを問わない。
なお、漏えいした個人データ又は漏えいしたおそれがある個人データにつき「高度な暗号化その他の個人の権利利益を保護するために必要な措置」が講じられている場合については報告を要しないとされており(APPI施行規則第7条第1号、ガイドライン通則編3-5-3-1)、その限りでは暗号化等による秘匿化の意義がある。
報告を要しない「漏えい等が発生し、又は発生したおそれがある個人データについて、高度な暗号化等の秘匿化がされている場合」に該当するためには、当該漏えい等事案が生じた時点の技術水準に照らして、漏えい等が発生し、又は発生したおそれがある個人データについて、これを第三者が見読可能な状態にすることが困難となるような暗号化等の技術的措置が講じられるとともに、そのような暗号化等の技術的措置が講じられた情報を見読可能な状態にするための手段が適切に管理されていることが必要と解されます。
第三者が見読可能な状態にすることが困難となるような暗号化等の技術的措置としては、適切な評価機関等により安全性が確認されている電子政府推奨暗号リストやISO/IEC18033等に掲載されている暗号技術が用いられ、それが適切に実装されていることが考えられます。
また、暗号化等の技術的措置が講じられた情報を見読可能な状態にするための手段が適切に管理されているといえるためには、①暗号化した情報と復号鍵を分離するとともに復号鍵自体の漏えいを防止する適切な措置を講じていること、②遠隔操作により暗号化された情報若しくは復号鍵を削除する機能を備えていること、又は③第三者が復号鍵を行使できないように設計されていることのいずれかの要件を満たすことが必要と解されます。
HEを含む暗号化データ処理には、次のような課題・限界があるとされている(OECD PAPER pp.21−22)。
データクリーニング(使用前に各データ主体で前処理チェックが必要)
分析結果から元データが漏えいしない保証はない
計算コストが嵩む
統合学習 (Federated learning)
統合学習は、学習用の1つのデータセットを作成する必要がなく、複数のデータベースやデバイスに分散しているデータをそのまま学習し、学習結果のみが共有される点に特徴がある。機械学習モデルとして使われるようである。
Federated learning: Traditional data analytical techniques require data to be linked and processed as a single dataset. With new federated learning methods, raw data are pre-processed at the level of the data source (e.g. at the level of the data subject). Only the summary statistics and results are transferred to the data processor to be combined with similar data from others. Federated learning reduces the need for sensitive data to leave the data subject’s device and be stored by data processors.
(訳) 従来のデータ分析手法においては、データは単一のデータセットとして整理され、処理される。この統合学習では、生データはデータソースのレベル(例えばデータ主体のレベル)で前処理される。要約統計と結果のみがデータ処理者に送信され、他のデータからの類似データと結合される。統合学習により、機密データがデータ主体のデバイスを離れ、データ処理者にのもとで保管される必要性が減少する。
Federated learning can enhance privacy and data protection where it reduces the need for data controllers and processors to view and hold sensitive data from data subjects. Pre-processing the data locally at the data subject level means that sensitive data can stay with the data subject. Only learnt parameters from a model are transferred back to the data controller to be used in refining models. Policy makers may decide that certain data must be pre-processed locally to protect the sensitive personal data of data subjects.
(訳) 統合学習により、データ管理者とデータ処理者がデータ主体の機密データを閲覧し、保持する必要性が減少し、プライバシー/データ保護が強化される。データ主体レベルでローカルにデータを前処理することは、機密データをデータ主体に残せることを意味する。モデルから学習されたパラメータのみがデータ管理者に転送され、モデルの改良に使用される。立法者は、データ主体の機密データを保護するため、特定のデータをローカルで前処理すべきことを定めることができる。
Federated learning is widely deployed by companies such as Google for predictive text applications. However, there remain concerns that the features/parameters pulled from federated learning can still leak personal information in certain cases (Hard et al., 2018[58]), and there are increasingly attacks that aim to recover some of the training data in certain cases. (Jiang, Zhou and Grossklags, 2022[59])
(訳) 統合学習は、Google等により予測テキストアプリケーションに広く導入されている。しかし、統合学習から引き出される特徴/パラメータが、特定のケースでは個人情報を漏えいさせる懸念が残っており、学習データの復元を意図する攻撃が増加する懸念もある。

統合学習や分散分析には、次のような課題・限界があるとされている(OECD PAPER pp.23)。
データ管理者に送り返されるパラメータ内のデータが漏えいする可能性がある
安定的な接続に依存する
しきい値秘密分散 (Threshold secret sharing: TSS)
しきい値秘密分散は、データを断片化し、一定のしきい値以上の断片が集まらないと復号できない状態にし、複数のエンティティが協力して計算を行うことで、個々のデータが漏えいしづらくする点に特徴がある。
Threshold secret sharing (TSS) – also known as Multi-party Computation Threshold Signing (MPCts): This cryptographic tool requires a predetermined number of keys to unlock encrypted data. It is the digital equivalent to a secure box that is locked with multiple separate locks, whose keys are held by different people. A predetermined number of key holders must all agree to use their keys to unlock it.
(訳) マルチパーティ計算閾値署名(MPCts)としても知られる。この暗号化ツールは、暗号化されたデータを復号するために、あらかじめ決められた数の鍵を必要とする。複数かつ別々の鍵で暗号化され、それぞれの鍵が異なる人により保持されるセキュアボックスのデジタル版に相当する。復号するためには、あらかじめ決められた数の鍵の保持者全員が、その鍵を使用して復号することに同意する必要がある。
TSS can enhance privacy and data protection because it can impose thresholds that must be met before data are available and accessible to data controllers. These thresholds could be agreed upon and set by data subjects or set via regulation. However, to date, little to no guidance is offered about thresholds that are safe for specific use cases. For example, what are best practices for threshold setting in different scenarios?
(訳) データが利用可能になり、データ管理者がアクセスできるようになる前に、満たすべきしきい値を設定することができるため、TSSはプライバシー/データ保護を強化できる。このしきい値は、データ主体の合意により設定されることもあり、規制により設定されることもある。しかし、現在時点では、特定のユースケースにとって安全なしきい値に関する指針はほぼ提供されていない。例えば、様々なシナリオにおけるしきい値設定のベストプラクティスはなにか。
TSS services are available on cloud platforms for specific use cases. For now, they have narrow applications. TSS also performs slowly on large data sets due to the cryptographic overhead. Current applications have largely targeted smaller amounts of data. For example, one work-around is using TSS to secure strong passwords rather than to secure the data themselves (Koens, 19 January 2021[64]).
(訳) TSSサービスは、特定のユースケース向けのクラウドプラットフォームで利用可能だが、現在の用途は限定的。TSSは暗号化コストのため、大規模なデータセットではパフォーマンスが低下する。現在のアプリケーションは、主に少量のデータを対象とする。例えば、データ自体を保護するのではなく、強力なパスワードを保護するためにTSSを使用することが回避策の1つとして考えられる。

以上
この記事が気に入ったらサポートをしてみませんか?