
例文提示とグロスのつけ方:実践編

Leipzig Glossing Rules
理論編では、標準日本語のテ形への注釈づけを例に、個別主義的方針、普遍主義的方針、そして中道的方針をレビューしてきました。自分の専門とする言語について、そしてその中のいろいろな形態素について、なるべく中道的方針を心がけながらグロス付与を工夫していくのが肝要です。
ある程度、中道的方針に目配りがなされている用語・グロスのリストとその運用方針がMax Plank研究所によって提案されており(Leipzig Glossing Rules; LGR)、これが現在の言語学における代表的な例文注釈法になっています(ここからダウンロード)。まずはLGRをよく読み解きながら、ここで提案されている方針に詳しくなることを目指しましょう。同時に、理論編でも詳しく述べたように、LGRに対してもまた普遍主義的な方針により過ぎた選択をしていないかを常に批判的に検討する癖をつけましょう。その際、中道的方針1「新規用語の創出」も、慎重をきしながら行なっていきましょう。
残念ながらLGRの文章は英語のみです。以下では、全部で10の方針からなるLGRを1つ1つ取り上げながら、それをなるべく忠実に和訳した上で、その意図するところについて私自身の解説を付け加え、日本語の例を載せて実践的に議論していきます。
Rule 1 単語ごとに揃える
Interlinear glosses are left-aligned vertically, word by word, with the example.
インターリニア・グロス(複行式注釈)は、単語ごとに左揃えすること。
例文提示は、1行目に分析対象言語の例文(形態素分析済み)、2行目に1行目に対応するグロス、3行目に全文訳で構成される3段の方式で、これをinter-linerar gloss(複行式注釈)と呼びます。4段方式など,いくつかの変則式の提示法もよくおこなわれ(また必要なことがあり),それらについてはここの5節(p. 12-)を参照されてください。
複行式注釈法において、例文を単語ごとに分ち書きして、単語ごとにグロスをふると、一気に構造的特性が見やすくなります。(1)と(2)を比べれば、Rule 1にしたがっている(2)の方が断然、見やすくて理解しやすいですね。

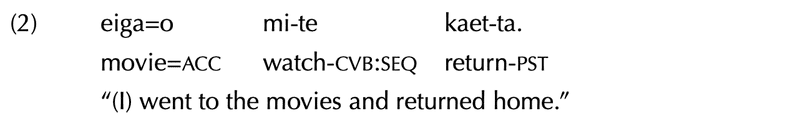
なお、「単語」の定義は、扱う言語によって異なり、それなりに難しい問題があると思います*。上の例では、アクセント付与の単位、すなわち伝統的に文節とされるものをLGRでいう「単語」相当に見立てて、文節ごとに分ち書きしています。
*日琉諸語に関するこの問題については以下の論考が参考になると思います。
宮岡伯人(2015)『「語」とはなにか・再考: 日本語文法と「文字の陥穽」』三省堂
下地理則(2020)「方言研究における例文提示法について」『方言の研究』5には、特に日琉諸語の事情に特化した詳しい解説があります。入稿前の原稿はここからダウンロード可能。
下地理則(2020)「フィールド言語調査における面接型調査の設計・実践・評価」国立国語研究所フィールドワークウェビナー(2020/12/9)において配布した,動詞活用の記述を行う実践的な手順解説。語境界を定める手順について特に詳しく書いています。ダウンロード可能。
左揃えにする方法
単語(1行目)とそのグロス(2行目)の左端を揃えることに注意してください。そうしないと、長い例文の時、いずれズレが拡大していってまずいことになります。Wordで論文を書くときは、まず一度エクセルで入力し、それをそのままワードに貼り付けると、ズレが全くない表形式でペーストされ、楽です(その後、表の枠線を消す)。

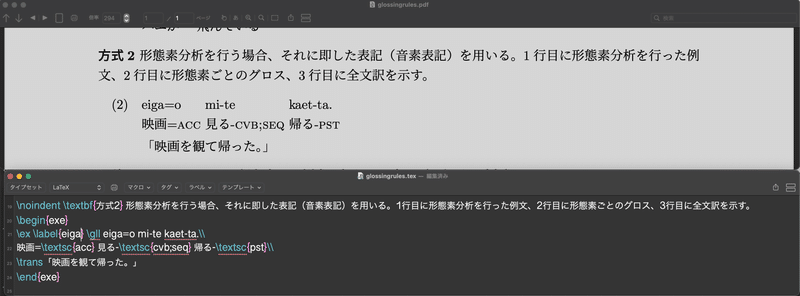
LaTeXを使っている人は、gb4eやexpexなど、例文提示に適したパッケージが豊富にあり、それらを使えば上記のような表を作る手間も省くことができ、さらにグロス一覧も自動で作成されたりという便利さもあって、例文作成の時間を大幅に節約できます。以下の図2に示すように、LaTeXの編集画面(図2の下半分)でベタ打ちで入力していけば、出力画面(上半分)では綺麗に単語ごとに揃った状態で出してくれます。今後、数千、数万の例文を書いていくであろう私たちの職業上、この例文作成の労を軽減するという意味でも、LaTeXに慣れておくことをお勧めします。LaTeXによる例文提示の何が良いのか,より具体的な解説と,より詳細な解説への橋渡しについて,ここを参照するといいです。
Rule 2 形態素とグロスの一対一対応
形態素とグロスの一対一対応
Segmentable morphemes are separated by hyphens, both in the example and in the gloss. There must be exactly the same number of hyphens in the example and in the gloss.
分析可能な形態素は、例とグロスの両方でハイフンで区切る。例とグロスの間で、ハイフンの数が完全に同じ一致するようにする。
例文は単語に分けるだけでなく、単語内部の形態素分析が可能なら、それも行います。単語内部の形態素境界はハイフンを用います。読者が形態素とグロスを見比べて吟味するときに混乱をきたさないように、例文1行目にある形態素の数が、2行目のグロスの数と常に一致している必要があります。この種の混乱の例をあえて再現してみます。日本語では、一般に名詞は複数接辞をつけなくても複数の意味が表せますが(「学生はみんな怒っている」cf. 「学生達はみんな怒っている」)、代名詞は複数接辞をつけない場合は常に単数の解釈しかできません。よって、「*私はみんな怒っている」とは言えません(cf. 「私たちはみんな怒っている」ならOK)。watasi「私」は単数形、watasi-tatiは複数形という形態的対立があるということです。正確にこれを書き表せば、「私」はwatasi-Ø(音形のないゼロの単数形態素を伴っている)ということになります。しかし、ここで、例文1行目のゼロ形態素(単数接辞)を省略してしまうと、以下のような例文提示になります。

これが、例文における形態素数とグロスの数が一致しない「悪い」例です。ゼロ形式の例文提示についてはRule 6も参照してください。
当該言語の正書法による行の追加
Since hyphens and vertical alignment make the text look unusual, authors may want to add another line at the beginning, containing the unmodified text, or resort to the option described in Rule 4 (and especially 4C).
ハイフンを使って区切ることと、(形態素とグロスを)縦方向に揃えるやり方は、当該言語の通常の正書法による書き方と大きく違う。そこで、1行目に正書法による例文を書き入れても良い。あるいは、Rule 4(特に4C)で説明されているやり方に従っても良い。
上記は、まさに日本語の例を考えるとわかりやすいでしょう。日本語は分ち書きをせず(語境界もなく)そのまま書いていく書記体系を有していますから、複行式グロスは見た目が大きく変わってしまいます。もし、例文を読む読者が日本人の場合、通常の日本語の表記による表示の行があった方が読みやすいかもしれません。そこで、以下のようにすることが提案されています。

英語も、その正書法による表記があまりに一般的であるため、音韻表記によるグロスづけを行う際は、見やすさのために正書法も添えるべきでしょう。(というか、日本語のカナ表記に比べると、正書法で書かれた例文に対して直接形態素分析を行なっていくこともある程度は可能ですね。)

上記の例を含め、英語の音韻表記、形態素分析、語境界の問題は以下の論文が参考になります。
Dixon, R.M.W. (2007) Clitics in English. English Studies, 88:5, 574-600, DOI: 10.1080/00138380701566102
挿入音素の扱い
Epenthetic segments occurring at a morpheme boundary should be assigned to either the preceding or the following morpheme. Which morpheme is to be chosen may be determined by various principles that are not easy to generalize over, so no rule will be provided for this.
形態素の境界で生じる挿入音素は、前の形態素または次の形態素のいずれかに属するようにする。前後どちらの形態素に属させるかは、さまざまな原則によって決まるはずで一般化はしにくいため、その方針はここでは示さない。
挿入母音などの挿入要素(epenthetic segment)は形態素ではないので、これは前か後ろのいずれかの形態素に含めて表示すること、というふうにLGRでは述べられています。これはどういう意味でしょうか?結論から言えば、これは上記の形態素とグロスの一対一対応を守るための方針です
例えば、日本語の動詞活用でテ形やタ形のいわゆる「T接辞」の作り方を記述するとしましょう。母音語幹動詞なら、mi-ta「見た」やtabe-ta「食べた」などのように、語根+過去接辞の2形態素からなる構造です。子音語幹動詞の場合も、(5a-c)のように、2形態素の構造を踏襲しますが、(5d)の/s/終わりの場合にだけ、語根とT suffixの間に/i/が生じることがわかります。これを、/s/と(T接辞の)/t/の間で生じる挿入母音であると考える立場があります(そうしない立場もあります)。そうすることで、すべての動詞を「語根+T suffix」という2つの形態素の合成だと一般化できます。この場合、単なる挿入要素である/i/は形態素ではないので、ハイフンで区切ることはできません(kas-i-taにはならない)。よって、接辞側に含めて、/s/終わりの場合には/ta/が/ita/という異形態を取る、という記述になります*。こうすることで、形態素(基底レベル)とグロスの一対一対応が守られます。

*本当はどっちのも属していない(境界に生じる挿入音素)とみていたとしても、グロス付与の便宜上、そのようにするということです。
上記の(5)の/i/のケースで,本当は語根・接辞のどちらにも所属していないのに,無理にどちらかの異形態として考えるのはやはり抵抗があるという人もいるでしょう。上記は,言語学的な分析の問題というよりも,例文提示法の問題であって,提示法をより適切なものにすれば,/i/をどちらにも所属させずに提示することができます。それは,例文を4段方式にすることです。
(5') kasita 表層
kas-ta 基底
lend-PST グロス
"lent"
接語境界について
Clitic boundaries are marked by an equals sign, both in the object language and in the gloss.
接語の境界は、対象言語とグロスの両方でイコールサインで示す。
単語内部の形態素境界はハイフンで、というのがLGRの基本原則です。しかし、すでに上記の例に出てきているイコールサイン(eiga=oの=)に気づいた人も多いでしょう。これは接語(あるいは付属語とも)の境界を示す記号です。接語(clitic)とは、自立語(word)と接辞(affix)に対立する語性に関する用語です。非常に大雑把に言えば、以下のような関係を頭に入れておいてください(Haspelmath and Sims 2010)。自立語は、形態的な観点でも音韻的な観点でも立派に自立した要素、接辞はそのいずれの点でも従属的な要素、そして接語は、形態的には自立しているものの(=単語の外に位置するものの)、音韻的には接辞と同様に従属的である要素です。
表1. 語性の関係

例えば、上記の対格助詞=oは、名詞という単語の外にありつつも(なぜなら名詞句全体が対格であることを示すために、句全体につくから)、しかし一方で、アクセントの点ではeiga=o全体で1つのアクセント単位を形成します。よって、=oは(句全体にくっつく点で)形態的にはそれ自体が単語であるが、(アクセントの点で)音韻的には単語になりきれていない要素、つまり接語だと言えるのです。上記の例で「単語」相当として分ち書きによって切り出した「文節」は、一人前の単語(自立語)に接語がくっついてできたものなのです。よって、接語境界は特別に=で表すという慣習が、特にフィールド言語学の世界では普通になってきています。
上の表で、空き間になっている部分に注目してください。形態的に従属的でありながら(自立語の中にありながら)、しかし音韻的に自立した要素です。Haspelmath and Sims (2010)をはじめとした教科書においても、多くの場合取り立てて名前のついていないこの要素は、個別言語を眺めていけば割とありふれた要素であることがわかります(Dixon 1977はYidiny語の記述でNon-cohering suffixなどと名前をつけていますし、Bowden 1997はParticleという用語を採用しています)。
Haspelmath, Martin, and Andrea Sims (2010) Understanding Morphology: Second Edition. Routledge.
Dixon, R.M.W. 1977. A grammar of Yidiny. Cambridge: CUP.
Bowden, John. 1997. Taba (Makian Dalam): description of an Austronesian language from Eastern Indonesia. PhD thesis, University of Melbourne.
例えば、日本語の「脱原発」や「反自民」のような表現があるとき、これらは確かに1つの自立語を成しており、脱(/datu-/)や反(/haN-/)は形態的には(接辞のような)従属要素です。一方、アクセントに注目すると、これらの接辞は独自のアクセント核を持っています(/da]tu-geNpatu/、/ha]N-zi]miN/)。これら(いわゆるAoyagi prefixと呼ばれる)「アクセントを持つ接頭辞」は、表2の空き間にあたる要素の具体例です。他にも、独自のアクセントを持つ複合語の語幹など、色々な例が思い付きます。この要素に関するグロス付与が、次のLGR Rule 2Aです。
Rule 2A (補則)
If morphologically bound elements constitute distinct prosodic or phonological words, a hyphen and a single space may be used together in the object language (but not in the gloss).
形態的に従属的な要素が異なる韻律語または音韻語を構成する場合、ハイフンとスペースを併用することでこれを表示しても良い。(ただしグロスではハイフンのみ)
上で見たAoyagi prefixを使った例を、この補則に従って表示すると以下のようになります。1行目がdatu-の後にスペースがある点と、2行目のグロスにはそのスペースがない点に注意してください。

Rule 3 文法形態素のラベル
Grammatical morphemes are generally rendered by abbreviated grammatical category labels, printed in upper case letters (usually small capitals). A list of standard abbreviations (which are widely known among linguists) is given at the end of this document. Deviations from these standard abbreviations may of course be necessary in particular cases, e.g. if a category is highly frequent in a language, so that a shorter abbreviation is more convenient, e.g. CPL (instead of COMPL) for "completive", PF
(instead of PRF) for "perfect", etc. If a category is very rare, it may be simplest not to abbreviate its label at all. In many cases, either a category label or a word from the metalanguage is acceptable.
文法形態素は一般的に、文法カテゴリ名の略号ラベルで表される。これらのラベルは通常、大文字で(たいてい小型大文字)書かれる。一般に知られている標準的な略号(言語学者の間でよく知られているもの)の一覧がこの文書の最後に掲載されている。場合によっては、これらの標準的な略号からの逸脱が必要になり得る。例えば、当該言語で使用頻度が高いカテゴリの場合は、より短い省略形が便利な場合がある(例:COMPLの代わりにCPL、PRFの代わりにPFなど)。カテゴリが非常に珍しい場合は、そのラベルを全く省略せずに表記するのが最も簡潔であろう。カテゴリの略号に代わって、翻訳対象言語(例えば英語論文なら英語)の対応する表現があればそれでも良い。
LGRが用意している略号リストは2024年1月現時点で84あります。これは中道的な方針(理論編参照)に従った、非常にバランスの良いリストですが、個別言語の記述をしていると、当然、それだけでは足りなくなります。言語の文法カテゴリーは言語ごとに多様であり得るからです。新しい言語の記述が進むほど、必要なグロスは増えていくと考えるべきです。例えば、私(下地理則)が2018年に『南琉球宮古語伊良部島方言』を出版した際、略号リストは94個の略号からなり、このうちLGRにないものが54個です。実に半数以上がLGRに頼れなかったものであり、自ら考案するか、あるいはさまざまな先行研究(例えば日本語標準語の研究や他の琉球諸語の記述研究)から借りてきたものです。
日琉諸語のグロスリスト
LGRにないグロスについて、いちいち自分で用語を考案して略号まで考えていくのは大変なだけでなく、そのような取り組み方があちこちで散発すると、1人の人しか使わない大量のグロスが量産されるだけです。
そこで私は、日琉諸語の研究者がLGR以外のグロスを作り出す手間をなるべく抑えることができ、また日琉諸語の中で十分に比較可能な文法カテゴリーに対して標準的なグロス略号を用意できないか、と考え、所属学生の宮岡大氏(2024年現在、D3)に依頼し、下地理則の研究室・方言グロスリストを作成してもらいました。このリストを参照すると、どの略号がどの研究で使われているかが一目瞭然(つまり、どれくらい標準化されている略号かがわかる)です。また、Googleスプレッドシートなので検索も用意です。例えば、「可能」という、日琉諸語では代表的な文法カテゴリーで検索すると、以下のような結果がヒットします。かなり多くの研究がpotentialという文法カテゴリーラベルを使用し、その略号としてPOTという3文字を使っていることがわかります(一部の研究はPTという「異形態」で使用していることもわかります。異形態という言い方に宮岡氏の形態論への愛を感じます)。また、これがLGRに載っていないことも(1列目の「LGR」に丸印がついていないことから)わかります。

略号かメタ言語か
上記のRule 3の最終文に「カテゴリの略号に代わって、翻訳対象言語(例えば英語論文なら英語)の対応する表現があればそれでも良い。」とあります。これは、構造が似ている言語間のグロス付けでよく見られるものです。例えば、日琉諸語研究で、琉球語の例文を日本語に訳すとき、このような方策がよく取られます。以下は宮古語伊良部島方言の例文を日本語に訳したものです。すべての形態素について、日本語に対応する形態素を用いています。

ただし、このやり方にも限界があります。上の例で言えば、焦点助詞=duは、現代の日本語では相当するものがなく、あえて「ぞ」という古典語の表現を借りています。同様に、-karについても、歴史的な観点からカリ活用である点を考慮して無理に「かり」(「ぞ」に応じて連体形で結ぶと言う点まで反映させれば「かる」)と訳をつけていますが、そもそも、このようなグロスをつけて理解できる人に、グロスは必要でしょうか?
このやり方のもう1つの問題点は、2言語間の形態素の対応が自明のものとなってしまっている点です。例えば、banti「私たち」に注目すると、確かにbanが「私」、-tiが「たち」に対応するように見えます。しかし、-tiは(琉球諸語でよく見られる)除外複数の「たち(聞き手を含まない)」です。よって、bantiを上のように逐訳するのはこの特徴に関して情報のロスになります。さらに、-gamaという形態素は指小辞で、小さいもの、愛らしいものなどを表す形態素ですが、これはさまざまなものにつき、日本語の「ちゃん」とは機能がかなり異なります。
よって、やはり、メタ言語(翻訳対象言語、上記の例では標準語)による訳を逐次的につけていくやり方は、私はどんな場合でも推奨しません。以下のようにやる方が、グロスの本来の目的(すなわち「当該言語を知らない人が、例文を理解する際の助けになる」という目的)にかなうと考えます。以下で、EXCLは1人称除外(exclusive)、GENは属格(genitive)、DIMは指小辞(diminutive)、PLは複数(plural)、FOCは焦点(focus)で、VLZは動詞語幹化(verbalizer)、NPSTは過去(nonpast)で、DIM以外はすべてLGRにあります。もちろんこれらはすべて、方言グロスリストにあります。

Rule 4: 一対多の対応
When a single object-language element is rendered by several metalanguage elements (words or abbreviations), these are separated by periods. The ordering of the two metalanguage elements may be determined by various principles that are not easy to generalize over, so no rule will be provided for this.
1つの対象言語要素が翻訳対象言語における複数の要素(単語または略号)によって表示される場合、これらはピリオドで区切る。翻訳対象言語における要素の順序は、さまざまな原則が絡むため、ここでは一般化しない。
例えば、以下の例で、yotta「酔った」の語根yot-(基底形はyow-)は英語ではget drunkに対応するので、get.drunkとしてyow-に対応させます。これが、上記の文の1行目における(単語または略号)のうちの「単語」が複数対応する例です。

次の例は略号(すなわち文法カテゴリーのグロス)に関する1対多のパターンです。禁止(否定命令)形態素 -runaに注目してください。これは、肯定命令形の-e/roと同様、命令文という特定の文タイプに出現するので、命令(imperative; IMP)という文法カテゴリーを有していると分析できます。一方、否定極性項目(例えば「しか」のような、否定素性を持つ要素と呼応する項目)と共起できるので、否定という文法カテゴリーも有しているはずです。つまり、否定(negative; NEG)+命令(IMP)という文法カテゴリーの合成だと考えて良いでしょう。

次の例で、形容動詞に後続するコピュラ=naは、名詞にかかっていく連体形です。終止形=daとコピュラ(copula; COP)であり、かつ連体形(adnominal; ADN)なので、=naという1形式に対して2つの略号を対応させます。

次の例は、いずれも形態音韻交替による接合形式(複合語幹の特別な形式)に絡むグロスづけです。一部の名詞語根は、アプラウトによる交替形をもち、これによって複合語幹であることを明示します(歴史的には露出形 vs. 被覆形の対立として知られる現象です)。接合形式をconjunction (CONJ)としてグロスを振るとしましょう。基底で/e/で終わる語根がアプラウトで/a/に交替するという形態音韻交替が(形態素のように)接合形式を表示するとみます。よって、CONJに対応する形態素はなく、(12a)の場合、語根amaが「雨」という意味とCONJという機能を持つ、というふうに一対多対応させます。

There are various reasons for a one-to-many correspondence between object language elements and gloss elements. These are conflated by the uniform use of the period. If one wants to distinguish between them, one may follow Rules 4A-E.
対象言語要素と用語要素の間に1対多の対応関係のあり方はさまざまであるが、すべて一貫してピリオドを使用することで統一的に示す。そのあり方ごとに区別したい場合は、ルール4A-Eに従うこと。
この但し書きについて、例えば(9)のような場合の「1対多」の対応(語彙の1対多)と(11)のような対応(文法形態素の1対多)、(12)のような形態音韻交替が絡む対応(形態音韻交替が「意味」を生む場合の1対多)など、すべてピリオドで区切っていますが、これらを区別したい場合には、以下に述べていく補則が適用される、ということです。
Rule 4A (補則)
If an object-language element is neither formally nor semantically segmentable and only the metalanguage happens to lack a single-word equivalent, the underscore may be used instead of the period.
もし対象言語の要素が形式的にも意味的にも分割できず、かつ翻訳対象言語では1単語で表現できない場合、ピリオドの代わりにアンダースコア(_)を使用することができる。
この状況は、すでに見た(9)の例です。

Rule 4B (補則)
If an object-language element is formally unsegmentable but has two or more clearly distinguishable meanings or grammatical properties, the semi-colon may be used.
対象言語の要素が形式的には分割できないが、複数の意味や文法的な特性に分割できる場合、セミコロンを使用する。
これは(10)(11)のケースに相当します。以下に、この補則を適用させて再掲します。


(12)のケースは単に「対象言語の要素が形式的に分割できない」わけではないので、ここでは扱いません。Rule 4Dを参照してください。
Rule 4C (補則)
If an object-language element is formally and semantically segmentable, but the author does not want to show the formal segmentation (because it is irrelevant and/or to keep the text intact), the colon may be used.
対象言語の要素が形式的かつ意味的に分割可能であるが、そのような分割を表示したくない場合(目下の議論に影響がない場合やテキストをそのままにしたい場合など)、コロンを使う。
これはいわば「意図的に1対多対応にする」ケースです。例えば、すでに見た(4)を以下に再掲します。これは、実際にそうしているように、きちんと1対1対応の注釈がつけられますが、読者の興味が形態素のそれぞれの意味にない場合(例えば語順についてだけ議論している場合など)、むしろ形態素境界とグロスの対応を読み解くのが邪魔になる場合がありえます。そういう場合は、形態素分析をせず、(14)のようにしてしまうのです。


Rule 4D (補則)
If a grammatical property in the object-language is signaled by a
morphophonological change (ablaut, mutation, tone alternation, etc.), the backslash is used to separate the category label and the rest of the gloss.
もし、対象言語において文法カテゴリーや特性が音韻的変化(アプラウト、音素置換、音調交替など)によって示される場合、バックスラッシュによってそのカテゴリラベルと残りのグロスを区切る。
すでに見たアプラウトのケース(以下に再掲)は、Rule 4Bで見た(10)(11)と違って、単に「対象言語の要素が形式的に分割できない」というわけではありません。

これらの、いわゆる「被覆形・露出形」の対立は、共時的には(基底の)/e/を(接合形式にしか出てこない)/a/に交替させるという点で、明らかにこの音韻交替が「取り出せ」て、それが接合という意味に対応しています。補則における「対象言語において文法カテゴリーや特性が音韻的変化によって示される」状況そのものです。
/ame/ (rain) + アプラウト (CONJ) = /ama/ (rain.CONJ)
よって、補則を適用し、以下のように書き表すことにします。

標準語ではアプラウトによる文法カテゴリーや文法特性の表示は珍しいですが、方言にはより豊富に存在している可能性があります。例えば琉球諸語では、代名詞の複数をアプラウトで標示する場合があります。特に沖縄語でこれがよく見られます。以下は伊江島方言の2人称単数と複数の作り方の例です。

Rule 5 人称と数のラベル
Person and number are not separated by a period when they cooccur in this order.
人称とその数は、この順で示す場合はピリオドで区切らない。
これは例えば1人称単数を1.SGとせず、1SGとする、というような意味で、特に解説はいらないでしょう。
Rule 5A (補則)
Number and gender markers are very frequent in some languages, especially when combined with person. Several authors therefore use non-capitalized shortened abbreviations without a period. If this option is adopted, then the second gloss is used in (21).
人称と数・性の組み合わせが非常に頻繁に使われる言語がある。その場合、ピリオドを付けず、また大文字にもしない短縮形の略語を使用してもよい。このオプションを採用する場合、(21)における2段目のグロスのようにする。

これについても、特に解説の必要はないでしょう。
Rule 6 音形のない要素
If the morpheme-by-morpheme gloss contains an element that does not correspond to an overt element in the example, it can be enclosed in square brackets. An obvious alternative is to include an overt "Ø" in the object-language text, which is separated by a hyphen like an overt element.
もし、形態素ごとの注釈において、音形に対応しない要素が含まれている場合、それらは角括弧で囲むことで表示しても良い。あるいは、別の方法として「Ø」を対象言語のテキストに含める。この後者の場合、音形を持つ要素と同様にハイフンで区切ること。
いわゆるゼロ形態をどう扱うか、に関わる重要な規則です。ゼロ形態は、音形がないが、形態素としてはそこに存在すると分析できるものです。単に「存在しない」こととは違います。この点は混同する人も多いので、以下で日本語の複数形式を例に詳しく議論します*。
この点についてより理解を深めたい人は、以下の優れた論考を参照すると良いです。
McGregor, William. 2003. The nothing that is, the zero that isn’t. Studia Linguistica 57 (2): 75-119.
不在とゼロの区別
日本語の人間普通名詞、例えば「学生」は、単複両方の解釈が可能です。「学生はみんな怒っている」でも、「学生たちはみんな怒っている」でも良いからです。この場合、「学生」自体には、「単数」という積極的な意味がないことになり、むしろ数について情報がないという方が正確です。文脈によって、あるいは-tatiをつけることで、複数の解釈を明示します。この場合、-tatiは「学生」に後続することで、複数の意味を「足し」ます。以下の図の左側の状況です。2つの形態素が横並びに生じ、2番目(-tati)が足し算的に生じる段階で、意味が限定されるというのは、言語記号同士の顕在的な関係、すなわちシンタグマティックな関係と言いますね。
一方、人称代名詞「私」の場合は、これ自体ですでに単数の解釈しかできません。「*私はみんな怒っている」とは絶対に言えないことからもわかります。「私」は、「私たち」という複数形式に対して、この-tatiを伴っていないという事実(-tatiを欠くという事実)により、単数であるという意味を表しています(図の右側)。「私」の後に、必ず指定される「単数か複数か」の単複選択のスロットがあって、-tatiという複数形態素が入れば複数として、それが入らなければ、スロットが「埋まっていない」こと自体に単数の意味が出てくるというわけです。これが、音形のない単数形態素、すなわちゼロ形態素の例です。上記の顕在的な「足し算」の関係(シンタグマティックな関係)に対して、どちらかの記号を「選択」する関係、つまり片方は選ばれない点で潜在的にしか存在しない、言語記号の潜在的な関係、すなわちパラディグマティックな関係と言います。

この、後者の場合にのみ、ゼロという形式を立てる意義があります。音形の欠如が、特定の意味に対応するからです。ここに注意しながら、自分の記述している現象が、ただの「不在」(図の左側)なのかゼロの「実在」(図の右側)なのか、慎重に見極めた上で、Rule 6にしたがってグロスをつけましょう。
Rule 7 内在的カテゴリー
Inherent, non-overt categories such as gender may be indicated in the gloss, but a special boundary symbol, the round parenthesis, is used.
語彙に内在的で形式を持たないカテゴリー(例えば性)はグロス付与の対象になるが、その場合( )で表示する。
語彙に内在的なカテゴリーは、LGRの例では性になっていますが、日本語や日琉諸語全般を扱う場合、例えば類別クラス(「有生」なら「いる」動詞をとり、「無生」なら「ある」動詞を取る、とか、数詞の形成が変わるとか)などがそれに当たります。ただし、類別クラスが常にグロス付与されるとは考えにくいですし、類別クラスの場合、性と違って、少数のカテゴリーに収斂しているわけでもないので、煩雑なグロスになりがちです。取り立てて議論の中心になっている場合のみ、関係のある例文表示に限って、この規則に従ってグロス付与することになるでしょう。例えば以下では、日本語で主要な類別クラス(有生 vs. 無生)によって存在動詞の取り方が違う点と、さらに細かいクラス(あるいはプロトタイプ)によって、数詞の接辞の取り方が変わる点を紹介する、という文脈を想定した場合です。

Rule 8 両肢要素(bipartite element)
Grammatical or lexical elements that consist of two parts which are treated as distinct morphological entities (e.g. bipartite stems such as Lakhota na-xʔu̧ 'hear') may be treated in two different ways:
(i) The gloss may simply be repeated
(ii) One of the two parts may be represented by a special label such as STEM
二つの部分から成る文法的または語彙的要素(例:Lakhota語の na-xʔu̹ 'hear' のような両肢語幹)は、次の2つの方法で処理される:
(i) グロスを単純に繰り返す
(ii) 2つの部分のうち1つをSTEMのような特別なラベルで表す
この両肢要素(bipartite element)は、日本語および日琉諸語全般ではなかなかこの類例を探すのが難しいので、まずはLGRがあげる例をそのまま以下に書きます(例文番号もそのまま)。

このLakhota語の例で、na-xʔu̹は、このように分離された状態で語彙項目になっていると考えられます(そしてこの点が、Rule 9で見るinfixの絡む語幹と違う)。この2つのパーツが、離れたままで1つの意味"hear"を共に表しているので、グロスを対応させる際に(i)のように単純に繰り返すか、(ii)のように1つをSTEMのようにして対処するということになるのです((ii)の対処例は以下)。

さて、日本語や日琉諸語全般を見た時、両肢要素に類似する現象は、例えば「お〜になる」のような尊敬表現でしょうか(山田2021が指摘)。これも、/o/という要素と/ninaru/という要素が決してくっつくことがなく、必ず間に動詞連用形が入り、しかもこの2つで「尊敬」(honorific; HON)を表すように見えます。
山田彬尭(2021) 「尊敬語の類型論」日本言語学会第162回大会予稿集. 2021, 162: 82-88.
しかし、私(下地理則)としては、これを上記のような両肢要素とは見ません。というのも、/o/はそれ単体で尊敬の接頭辞として機能することがあり、つまりそれ自体に接頭辞として認定する必要があります。/ninaru/も、適正に形態素分析すれば、与格/=ni/、動詞語根/nar-/「なる」に分析でき、それぞれが独自の形態素になっています。/o-/ + /=ni/ + /nar-/は、3形態素からなる構造体(construction)だと見た方が適切だと思います。一方、Lakhota語の場合、形としては2つに明確に分解できるna-xʔu̹が、形態素としては(意味を持つ単位としては)1つである、という点が大きく違います。
さて、両肢要素は、Lakhota語の両肢語幹よりも、一般的には以下のような両肢接辞、すなわち接周辞が有名です。オーストロネシア語族の言語でよく見られるヴォイス接辞など(e.g. インドネシア語の自発 /ke- -an/)に加えて、(私には意外でしたが)LGRが例示しているのはドイツ語の分詞を作る形態素です。

Rule 9 接中辞
Infixes are enclosed by angle brackets, and so is the object-language counterpart in the gloss.
接中辞は< >で囲み、対応するグロスも< >で囲む。
接辞の中でも、語幹の前にくるものが接頭辞、後に来るのが接尾辞だとすると、接中辞は、語根を分断する接辞です。以下はLGRが提供するタガログ語の例です。

分断された語根(上でbili)は、見かけ上2つに分離されますが、これはRule 8で見た両肢要素と異なる点に注意してください。上記の両肢要素は、常に離れた状態で存在する形態素で、そういう形で語彙登録されている形態素です。しかし、接中辞で分断される語根は、接中辞が入り込むという操作の結果、分断されているだけです。
日本語および日琉諸語にその類例を探すのは難しいですが、那須(2004)は強意の特殊モーラQ/N(e.g. 「ばったり」「ふんわり」)を接中辞/µ/だとする興味深い義論を行なっています(那須2004)。
那須昭夫 (2004)「韻律接中辞と左接性―日本語オノマトペの強調語形成―」『日本語と日本文学』第 38 号, 1– 14.
ただし、これについてもまた、私は反対です。というのも、接中辞が「接辞」という形態素クラスをなすならば、ほかの接辞と同様に、語根と独立して存在する形態であるべきで、「語根の音韻・韻律情報をもとに作られる」要素(強意の「っ」)は接辞と呼ぶべきではないと思うからです(そして、これは理論的な立場によるのでしょう)。ちょうど、重複(reduplication)によるコピー要素を接辞と見ないことと同じロジックです。すなわち、語基(元となる語根)を発生源とする形態的由来物(語基由来要素)のように考えるべきだと思っています。ある言語におけるLexiconを考えた時、語彙素がp個、接辞がq個、合わせてp+q個の「記憶容量」を要するはずですが、p個の語彙素の韻律情報をもとに(そしてそれのみで)形成できる「接中辞」は、接辞の数の中に含めるべきではない、ということです*。
*那須は、接中辞の特異性(音韻的・韻律的要因に依存すること)を鋭く指摘しており、ひょっとすると「接中辞」を便宜的なラベルとして用いており、私がいうreduplicantと同等の「語基由来要素」とみなしている可能性もあります。
Rule 10 重複形式
Reduplication is treated similarly to affixation, but with a tilde (instead of an
ordinary hyphen) connecting the copied element to the stem.
重複は接辞化と同様に扱うが、コピー要素はハイフンではなくチルダ(~)で結ぶ。
例えば、日本語の離散的・非均一的複数を表す「山々」「神々」「村々」などは、重複の代表的な例です。今、この複数という意味をPLとしてグロスを振ります。コピー要素に割り当てられることになります。
(28) yama~yama
山 ~PL
(29) kami~gami
神~PL
LGRが言うところの「重複は接辞化と同様に扱う」というのは、語基(重複の元)とコピーを線形に並べて、コピーを1つの形態素のようにみなす、ということです。しかし、私は個人的にはここに疑問を持っています。というのも、重複は上記Rule 9で述べた「語基由来要素」であることは明らかですから、以下のような入力・出力の関係を想定でき、このうち重複という形態音韻操作そのものに「意味」が生じるはずです。出来上がったコピー(具体的な「山」や「神」)に「離散的複数」の意味が加わるわけではないということです。
yama「山」-> 重複 -> yama~yama「山々」
kami「神」-> 重複 -> kami~gami「神々」
ただ、そういう規則がすでに提案され、流通しているのは事実ですので、これに従うと上記(28)(29)のようになるということを紹介しておきます。私自身は、語基とコピー要素を ~で区切るところまでは従いつつ、コピーに対しては一貫してRED(reduplication)というグロスを振って、意味はその全体から計算される、という(私の)方針を守っています。
この記事が気に入ったらサポートをしてみませんか?