
Word Cloud作ってみた

Word cloudとは
テキストマイニングの手法の一つ。上の写真のようにある文章を分析して頻出する単語を大きく表示し分析に役立てる方法。
pythonのwordcloudというライブラリを用いて作成可能。日本語のwordcloudを使用するためにMeCab(形態素分析用のライブラリ)を使用する。
またwordcloudの作り方の記事は他にも多くあるため、本noteでは作り方では記事の紹介で済ませ、つまづきポイントに絞って取り上げる。
1、ライブラリのインストール
wordcloudとMeCabをインストール。今回初めて知ったがpythonのライブラリのインストールにはpipとcondaの2つがよく使われる。そしてそれぞれ同じパッケージをインストールするとPCが壊れることがあるらしい(怖)
Anacondaを使っている人は大人しくcondaを使うようにしよう。インストール方法は以下サイト参照
wordcloud インストール
https://pypi.org/project/wordcloud/
MeCabインストール
https://techacademy.jp/magazine/24037
2,英文のWordCloudを作ろう
以下がサンプルコード
#ライブラリの読み込み
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
#WordCloudの作成
text = "ここに分析したい英文を入れる"
wordcloud = WordCloud().generate(text)
#作成したWordCloudを表示
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
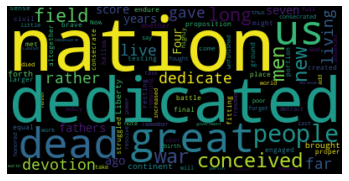
plt.show()これをコピペして変数Textに分析したい英文を入れればOK。以下のような画像が表示される。(テキストはリンカーン大統領のゲティスバーグ演説を使用)
英語は日本語と違い単語ごとに空白が開くため分析が簡単にできる。
3、日本語でWordCloudを作ろう
以下サンプルコード
#ライブラリの読み込み
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
from MeCab import Tagger
t = Tagger()
#分析したい文章と除外ワードを指定
text = """
ここに分析したいテキストを挿入
"""
#stop_wordsで除外したい言葉を指定
stop_words = [ u'てる', u'いる', u'なる', u'れる', u'する', u'ある', u'こと', u'これ', u'さん', u'して', \
u'くれる', u'やる', u'くださる', u'そう', u'せる', u'した', u'思う', \
u'それ', u'ここ', u'ちゃん', u'くん', u'', u'て',u'に',u'を',u'は',u'の', u'が', u'と', u'た', u'し', u'で', \
u'ない', u'も', u'な', u'い', u'か', u'ので', u'よう',\
u'です', u'ます', u'まし', u'この', u'あの', u'その', u'どの',u'という',u'から',u'なり',u'でしょ',u'ませ', \
u'まで',u'について',u'なく',u'なら',u'']
#テキストを単語ごとに分割
splitted = " ".join([x.split("\t")[0] for x in t.parse(text).splitlines()[:-1]])
#WordCloudの作成
wordcloud = WordCloud(background_color="white", width=1000, height=600, font_path="/Library/Fonts/Songti.ttc",stopwords=set(stop_words)).generate(splitted)
#作成したWordCloudを表示
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()使い方は英文の場合と同じ。text変数に分析したい日本文を入れればOK。
日本語のWordCloud作成にあたり課題は2点
1点目:単語ごとに分割が必要
これについてはMecabというpythonライブラリを用いて解決ができた。日本語をかなり正確に分割することが可能。コードの「#テキストを単語ごとに分割」の部分が分割の操作に相当する。
Mecabを使うと以下のようにテキストが分割される。品詞間に空白ができていることがわかる。
”””日本語 で WordCloud を 作ろ う”””
課題2点目:助詞、助動詞が大きく表示され分析ができない

こんな感じで「です」、「まし(た)」、「こと」、「この」のような意味のない言葉が大きく表示されてしまう。
これについてはWordCloudのstopwordsオプションで除外できる。コードでは「#stop_wordsで除外したい言葉を指定」で除外リストを作成して除外を行なっている。これについては除外とWordCloud作成を繰り返していい感じになるまで泥臭く除外を行わなければならない。
完成したWordCloudはこちら。Tedのスピーチを適当に使用している。

このWordCloudからでも教育に関する自己啓発系のスピーチであることがわかる。
おまけ:リスト型のデータでWordCloudを作ろう
今回は演説やスピーチのWordCloudを作成した。しかし実戦で使用するとなるとデータベースなどに保管されているテキストデータを分析することが多いだろう。Pythonはcsvやexcelファイルのインポートができるので特に問題ない。しかしそのような場合リスト型のデータ扱うことになるので最後にリスト型のデータでWordCloudを作る。
サンプルコード
#ライブラリの読み込み
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
#リスト型のデータを記入(例)
text = ["apple", "lemon", "orange","apple", "banana"]
#wordcloudを作成
wordcloud = WordCloud().generate(" ".join(text))
#作成したWordCloudを表示
plt.imshow(wordcloud, interpolation='bilinear')
plt.axis("off")
plt.show()textにリスト型のデータを入れていることがわかる。実際に使用する場合はここに読み込んだデータを代入する。
データ代入後、「#wordcloudを作成」でリストのデータを結合してしまう(" ".join(text))ことでエラー出さずにwordcloudを作成できる。
日本語のリストの場合は一度リストを結合した変数を作成。
Mecabでその変数に対して単語の分割を行う。
という手順を行えば、wordcloudを作ることができる。
感想
日本語のテキストマイニングは本当に難しい。今まで何度かやってみようと思ったものの定性データをどうやってプログラミング(0、1の定量の世界)に落とし込めばいいのかわからなかった。
今回のWordCloudはそこまで詳細なデータを分析できるわけではないが、テキストマイニングの取っ掛かりとしてはとてもいいと思う。簡単かつ成果がわかりやすい。
また作成の途中で使用したMeCabは日本語を品詞ごとに分割してくれる優れものでこれからテキストマイニングを行うときに役立ちそうだと感じた。
この記事が気に入ったらサポートをしてみませんか?