
AIを支えるベンチマークの悩ましい課題

「ベンチマーク」とは何かを評価するときの指標で、どちらかというと裏方のイメージがあります。
そんな「ベンチマーク」の改善こそがAIの性能を左右する、という興味深い記事がScience誌(5/5)に投稿されています。
要は、
ベンチマークの改善がAIの性能を急激に押し上げているが、ベンチマークを開発するインセンティブにはもう少し工夫が必要、
という話です。
AIは今第三次ブームと呼ばれ、その貢献は「ディープラーニング(深層学習)」にあります。
そのディープラーニングの性能を見せつけたのは、まさにベンチマークを使った国際画像コンテスト(ILSVRC)です。
時系列でみたディープラーニング登場前後の推移を紹介した記事を引用します。
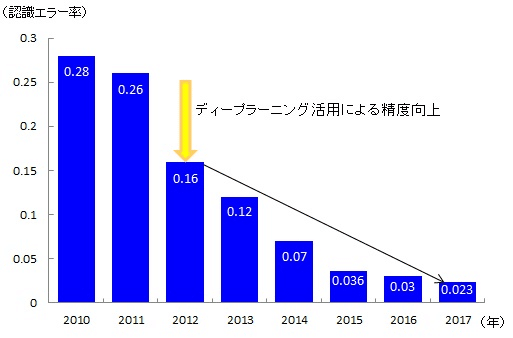
そのほかのベンチマーク含めて、冒頭記事では既に人間の性能を超えている結果を引用しています。

ただ、今回はこのベンチマーク自身が現実世界では結構もろいのと、それを改善するプロセスに課題があることを触れています。
確かに、評価する物差し自体がくるっていたら大問題です。
今回の記事以外でも、近い疑問を呈した論文も出ています。
要は、
画像の正解を与えるラベル張り(アノテーションと呼ばれます)自身の性能に問題がないか?
ということです。
冒頭記事が例示しているDnynabenchというベンチマークでは、テストデータの学習のさせ方をコンピュータだけでなく不特定多数の人間(Crowd)に委ねるという方式を採用しました。
特に期待したのは、ベンチマーク自身をだませるような意地の悪いフレーズを考えてもらってインセンティブを与える、というものです。
画像認識でも、例えばある病院で診断に使う画像データセットを使ったベンチマークと、別の画像データセットとで結果がが異なるという課題はあります。
そしてそれ自体の差異を修正するアルゴリズムWILDSを開発した、と冒頭記事では紹介されています。
ちょっと込み合ってきましたが、「要は汎用的に使えるベンチマークを創るためのベンチマーク」ということです。
これは、病院での画像診断以外に、社会的偏見を評価する用途にも使えるそうです。
ただし、偏見を正すベンチマーク開発は躊躇がある、という文中研究者のコメントがあり、これは心情的に共感します。
どうしても、偏見は主観的判断なので、最終的には人間の倫理的判断に寄らざるを得ないからだと思います。(正義という言葉も近い響きがあります)
今は余り紹介されなくなりましたが、一時期はAIを測るテストに「チューリングテスト」というものがありました。(今でもあります)
コンピュータ科学者アラン・チューリングが由来で、彼が元々アイデアとして構想したものを、とある大富豪が彼の死後に賞金付きのコンテストとして開きました。
これは、対話相手が人間か機械かを当てるテストで一定(30%)以上だませたら「合格」となります。
2014年に初めて合格者が出ましたが、これがAIの性能を引き上げたとは思えません。関心を呼んだことぐらいでしょうか。
この例だけでなく、ベンチマークは全てではなくあくまで一部の見方です。
有名な実験で、ある工場で電灯の明るさと作業生産性を評価したところ、なんと明るくするほど生産性が上がるという結果が出ました。
一見すごそうですが、今度は逆に暗くしても上がりました。
オチを言うと、測定することを作業者に伝えること自体でその生産性が高まったことを表しています。
ベンチマーク全体でも、人間が関わることでどうしても測定の目標化による問題は生じてしまいます。
なかなか悩ましいのが本音ですが、少なくともベンチマークだけを鵜呑みにしないようにしようと思います。
この記事が気に入ったらサポートをしてみませんか?