
Pythonでやってみた12:APIで統計情報取得(e-Stat)

1.概要
政府統計の総合窓口(e-Stat)で提供している統計データをAPIを用いて取得します。APIを使用すれば最新の統計情報を高速で取得可能です。
2.環境構築
2-1.API KEY発行
まずはAPIを使用するためのKEYを発行します。「ログイン」→「マイページ」→「API機能(アプリケーションID発行)」へ移動します。
「アプリケーションIDの取得」ページへ移動後は必要な情報を適当に入力して「発行」ボタンを押すとappID(API KEY)が発行されます。

2-2.公式Pythonライブラリ:e-stat-api
e-stat公式より「中間アプリはe-Stat APIを使いやすくするためのPythonライブラリです。」とのことです。
本記事では使用しませんが、使いやすそうであれば別途記事作成します。
3.APIの使用方法
APIの使用方法について説明します。詳細は公式に記載しておりますが、一部理解しにくいため実例は追って説明します。
データ取得にはRequestを使用しますが要領は別記事をご確認ください。
3-1.APIサービスの種類
APIの仕様詳細は公式(API機能)の方でご確認ください。
政府統計の総合窓口(e-Stat)では取り扱うデータの種類や操作内容により、以下の7つの機能を提供します。
統計表情報取得
メタ情報取得
統計データ取得
データセット登録
データセット参照
データカタログ情報取得
統計データ一括取得
3-2.APIエンドポイントおよびHTTPメソッド
APIエンドポイントは各サービスで異なりますがルールはほぼ同じであり、戻り値の指定も指定できます。またHTTPメソッドもサービスごとで所定のものを選択します。
参考として「統計データ取得」のエンドポイント一覧は下表の通りです。

[APIエンドポイント:統計データ取得]
(XML形式) http(s)://api.e-stat.go.jp/rest/<バージョン>/app/getStatsData?<パラメータ群>
(JSON形式) http(s)://api.e-stat.go.jp/rest/<バージョン>/app/json/getStatsData?<パラメータ群>
(JSONP形式) http(s)://api.e-stat.go.jp/rest/<バージョン>/app/jsonp/getStatsData?<パラメータ群>
(CSV形式) http(s)://api.e-stat.go.jp/rest/<バージョン>/app/getSimpleStatsData?<パラメータ群>
HTTPメソッド GET3-3.APIパラメータ
HTTPメソッドを使用する時にデータを渡す(GETメソッドでのクエリパラメータやPOSTメソッド)必要があります。
appId(APIキー)は全サービスで必ずデータを渡す必要があります。

各サービスごとで必要なパラメータは公式Docsで調べる必要があり、下表は「統計データ取得」の一部となります。

3-4.APIの出力確認:サンプルコード
APIの出力を確認するためサンプルコードを実行します。サンプルは公式の「APIの使い方」"東京の老年人口割合[65歳以上人口]"を取得します。
【ポイント】
●URLの"app/"の後ろに"json"を指定することで戻り値はJSON形式
●statsDataIdの"C0020050213000"は東京都の社会・人口統計体系のデータ
●"cdCat01=%23A03503"で老年人口割合[65歳以上人口]を指定している。なお実際のコードは"#A03503"だが「パラメータ値は必ずURLエンコード(文字コードUTF-8)してから結合」する必要があるため"%23A03503"を使用した
●lang、statsNameListのようにデフォルト値があるものは省略可

[IN]
import requests
appId_estat= '<自分で発行したAPIキーを入力>' #APIキー
url = f'http://api.e-stat.go.jp/rest/2.0/app/json/getStatsData?appId={appId_estat}&statsDataId=C0020050213000&cdCat01=%23A03503' #エンドポイント
res = requests.get(url) #リクエスト送信(GET)
res.json()
[OUT]
{'GET_STATS_DATA': {'RESULT': {'STATUS': 0,
'ERROR_MSG': '正常に終了しました。',
'DATE': '2022-08-07T14:36:01.245+09:00'},
'PARAMETER': {'LANG': 'J',
'STATS_DATA_ID': 'C0020050213000',
'NARROWING_COND': {'CODE_CAT01_SELECT': '#A03503'},
'DATA_FORMAT': 'J',
'START_POSITION': 1,
'METAGET_FLG': 'Y'},
'STATISTICAL_DATA': {'RESULT_INF': {'TOTAL_NUMBER': 11,
'FROM_NUMBER': 1,
'TO_NUMBER': 11},
~~~~以下省略~~~~
}}}}出力データの構成は基本的には下記3つで構成されます。さらに詳細の構成は下表をご確認ください。
【API出力データの構成】
1.APIの処理結果情報(RESULT)
2.APIが受信したパラメータ情報(PARAMETER)
3.API毎の出力(DATALIST_INF)
Pythonで実際に確認してみます。今回の出力では"GET_STATS_DATA"内にある3つのキー['RESULT'、'PARAMETER'、'STATISTICAL_DATA']に全データが保存されております。
[IN]
jsonData = res.json()
print(len(jsonData), jsonData.keys()) #KEYは1つ
print(len(jsonData['GET_STATS_DATA']), jsonData['GET_STATS_DATA'].keys()) #KEYは3つ
for key, val in jsonData['GET_STATS_DATA'].items():
print(key)
print(val)
print('*'*100)
[OUT]
1 dict_keys(['GET_STATS_DATA'])
3 dict_keys(['RESULT', 'PARAMETER', 'STATISTICAL_DATA'])
RESULT
{'STATUS': 0, 'ERROR_MSG': '正常に終了しました。', 'DATE': '2022-08-07T14:36:01.245+09:00'}
****************************************************************************************************
PARAMETER
{'LANG': 'J', 'STATS_DATA_ID': 'C0020050213000', 'NARROWING_COND': {'CODE_CAT01_SELECT': '#A03503'}, 'DATA_FORMAT': 'J', 'START_POSITION': 1, 'METAGET_FLG': 'Y'}
****************************************************************************************************
STATISTICAL_DATA
{'RESULT_INF': {'TOTAL_NUMBER': 11, 'FROM_NUMBER': 1, 'TO_NUMBER': 11}, 'TABLE_INF': {'@id': 'C0020050213000', 'STAT_NAME': {'@code': '00200502', '$': '社会・人口統計体系'}, 'GOV_ORG': {'@code': '00200', '$': '総務省'}, 'STATISTICS_NAME': '社会・人口統計体系', 'TITLE': {'@no': '13000', '$': '東京都'}, 'CYCLE': '-', 'SURVEY_DATE': 0, 'OPEN_DATE': '2017-06-23', 'SMALL_AREA': 0, 'MAIN_CATEGORY': {'@code': '99', '$': 'その他'}, 'SUB_CATEGORY': {'@code': '99', '$': 'その他'}, 'OVERALL_TOTAL_NUMBER': 86953, 'UPDATED_DATE': '2017-06-23'}, 'CLASS_INF': {'CLASS_OBJ': [{'@id': 'tab', '@name': 'データ種別', 'CLASS': [{'@code': '001', '@name': '基礎データ', '@level': '1'}, {'@code': '002', '@name': '指標データ', '@level': '1'}]}, {'@id': 'cat01', '@name': '項目', 'CLASS': {'@code': '#A03503', '@name': '老年人口割合[65歳以上人口]', '@level': '1', '@unit': '%'}}, {'@id': 'area', '@name': '都道府県・市区町村名', 'CLASS': {'@code': '13000', '@name': '東京都', '@level': '1'}}, {'@id': 'time', '@name': '調査年度', 'CLASS': [{'@code': '1975', '@name': '1975', '@level': '1'}, {'@code': '1976', '@name': '1976', '@level': '1'}, {'@code': '1977', '@name': '1977', '@level': '1'}, {'@code': '1978', '@name': '1978', '@level': '1'}, {'@code': '1979', '@name': '1979', '@level': '1'}, {'@code': '1980', '@name': '1980', '@level': '1'}, {'@code': '1981', '@name': '1981', '@level': '1'}, {'@code': '1982', '@name': '1982', '@level': '1'}, {'@code': '1983', '@name': '1983', '@level': '1'}, {'@code': '1984', '@name': '1984', '@level': '1'}, {'@code': '1985', '@name': '1985', '@level': '1'}, {'@code': '1986', '@name': '1986', '@level': '1'}, {'@code': '1987', '@name': '1987', '@level': '1'}, {'@code': '1988', '@name': '1988', '@level': '1'}, {'@code': '1989', '@name': '1989', '@level': '1'}, {'@code': '1990', '@name': '1990', '@level': '1'}, {'@code': '1991', '@name': '1991', '@level': '1'}, {'@code': '1992', '@name': '1992', '@level': '1'}, {'@code': '1993', '@name': '1993', '@level': '1'}, {'@code': '1994', '@name': '1994', '@level': '1'}, {'@code': '1995', '@name': '1995', '@level': '1'}, {'@code': '1996', '@name': '1996', '@level': '1'}, {'@code': '1997', '@name': '1997', '@level': '1'}, {'@code': '1998', '@name': '1998', '@level': '1'}, {'@code': '1999', '@name': '1999', '@level': '1'}, {'@code': '2000', '@name': '2000', '@level': '1'}, {'@code': '2001', '@name': '2001', '@level': '1'}, {'@code': '2002', '@name': '2002', '@level': '1'}, {'@code': '2003', '@name': '2003', '@level': '1'}, {'@code': '2004', '@name': '2004', '@level': '1'}, {'@code': '2005', '@name': '2005', '@level': '1'}, {'@code': '2006', '@name': '2006', '@level': '1'}, {'@code': '2007', '@name': '2007', '@level': '1'}, {'@code': '2008', '@name': '2008', '@level': '1'}, {'@code': '2009', '@name': '2009', '@level': '1'}, {'@code': '2010', '@name': '2010', '@level': '1'}, {'@code': '2011', '@name': '2011', '@level': '1'}, {'@code': '2012', '@name': '2012', '@level': '1'}, {'@code': '2013', '@name': '2013', '@level': '1'}, {'@code': '2014', '@name': '2014', '@level': '1'}, {'@code': '2015', '@name': '2015', '@level': '1'}, {'@code': '2016', '@name': '2016', '@level': '1'}]}]}, 'DATA_INF': {'NOTE': [{'@char': '***', '$': 'データが存在しないことを示している'}, {'@char': '+', '$': 'データが秘匿されていることを示している'}, {'@char': '-', '$': 'データが得られないことを示している'}], 'VALUE': [{'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2005', '@unit': '%', '$': '18.3'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2006', '@unit': '%', '$': '19.1'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2007', '@unit': '%', '$': '19.7'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2008', '@unit': '%', '$': '20.2'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2009', '@unit': '%', '$': '20.9'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2010', '@unit': '%', '$': '20.4'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2011', '@unit': '%', '$': '20.6'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2012', '@unit': '%', '$': '21.3'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2013', '@unit': '%', '$': '21.9'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2014', '@unit': '%', '$': '22.5'}, {'@tab': '002', '@cat01': '#A03503', '@area': '13000', '@time': '2015', '@unit': '%', '$': '22.7'}]}}
****************************************************************************************************3-4ー1.RESULTタグ
RESULTタグの出力内容は下表のとおりです。

3-4ー2.PARAMETERタグ
PARAMETERタグは各サービスで異なります。参考として「統計データ取得(getStatsData)」のタグを下表に示します。

3-4ー3.DATALIST_INFタグ
DATALIST_INFタグは各サービスで異なります。参考として「統計データ取得(getStatsData)」のタグを下表に示します。

4.データの選択方法
データは「統計データを探す」から調べることが可能です。

参考までに「分野」で確認すると下記データがあります。

5.実演処理フロー:人口情報の取得
本章では人口データを取得して可視化します。一部のコードは「【e-Stat】政府統計人口データをPythonで可視化する」を参考にしました。
5-1.取得データのAPIエンドポイント確認
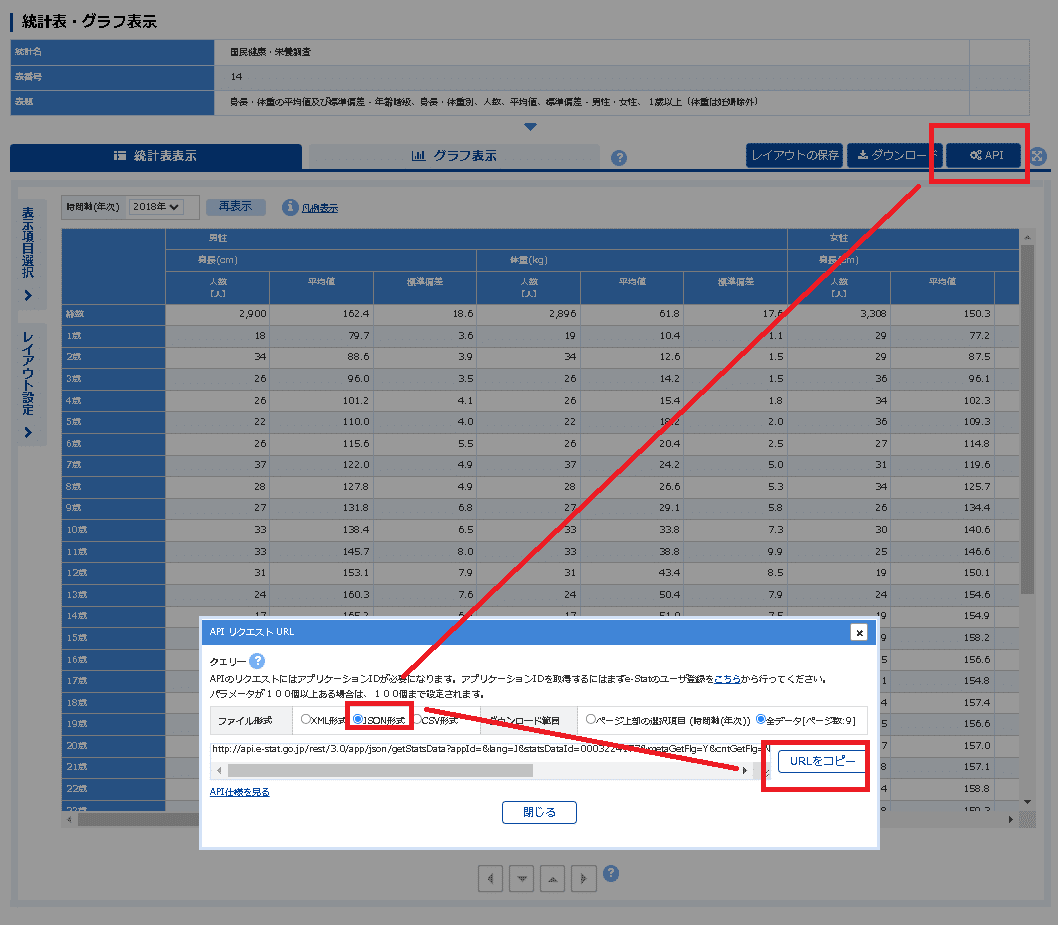
まず初めにデータのAPIエンドポイントを確認します。確認方法は必要なデータセットを調べて「表示・ダウンロード」の”API”を押します。

下記の通りURLが出ますので①ファイル形式を選択、②サービス・パラメータの確認を行います。今回は"getStatsData(統計データ取得)"のためHTTPメソッドはGETでありパラメータはクエリパラメータで渡します。

[APIエンドポイント:JSON形式]
http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData?appId=&lang=J&statsDataId=0003412313&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=05-2.取得データのAPIエンドポイント確認
URLをエンドポイントとクエリパラメータに分けてGETメソッドを実行するとJSON形式でデータを取得できました。
[IN]
import requests
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
appId_estat = '<自分のAPIキーに差し替え>' #APIキー
url = 'http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData' #エンドポイント
params = {'appId':appId_estat,
'lang':'J',
'statsDataId':'0003412313',
'metaGetFlg':'Y',
'cntGetFlg':'N',
'explanationGetFlg':'Y',
'annotationGetFlg':'Y',
'sectionHeaderFlg':'1',
'replaceSpChars':'0'} #パラメータ
res = requests.get(url, params=params)
jsonData = res.json()
print(len(jsonData), jsonData.keys()) #KEYは1つ
print(len(jsonData['GET_STATS_DATA']), jsonData['GET_STATS_DATA'].keys()) #KEYは3つ
data_static = jsonData['GET_STATS_DATA']['STATISTICAL_DATA'] #STATISTICAL_DATAのデータを取得
print(len(data_static), data_static.keys()) #KEYは4つ
[OUT]
1 dict_keys(['GET_STATS_DATA'])
3 dict_keys(['RESULT', 'PARAMETER', 'STATISTICAL_DATA'])
4 dict_keys(['RESULT_INF', 'TABLE_INF', 'CLASS_INF', 'DATA_INF'])5-3.JSONデータ解析および可視化
取得したJSONの中身を確認しながらほしいデータを抽出します。データ構造を理解するところが一番時間がかかるためため、とりあえず結果だけ出力しました。
[IN]
def get_data(res=res.json(), cat01="001",cat02="001"):
x = []
y = []
for value in res["GET_STATS_DATA"]["STATISTICAL_DATA"]["DATA_INF"]["VALUE"]:
if value["@unit"]=="千人" and value["@cat01"]==cat01 and value["@cat02"]==cat02:
x.append(int(value["@cat03"])-1001)
y.append(int(value["$"]))
return x,y
def showgraph():
x_sum,y_sum = get_data(cat01="001",cat02="001")
x_male,y_male = get_data(cat01="002",cat02="001")
x_female,y_female = get_data(cat01="003",cat02="001")
plt.figure(figsize=(12, 6))
plt.plot(x_sum[1:],y_sum[1:],label="Sum")
plt.plot(x_male[1:],y_male[1:],label="Male")
plt.plot(x_female[1:],y_female[1:],label="Female")
plt.tick_params(labelsize=15)
plt.xlim(0,100); plt.ylim(0,2500)
plt.xticks(np.arange(0,110,10))
plt.legend(fontsize=13)
plt.grid()
plt.xlabel("年齢 [歳]",fontsize=15)
plt.ylabel("人口 [千人]",fontsize=15)
plt.show()
showgraph()
[OUT]
6.統計データの解析実践:(生活編)
本章では「APIで何ができるか」を理解するために、説明無しでアウトプットだけ紹介します。
6-1.身長・体重の平均値及び標準偏差
「国民健康・栄養調査14 身長・体重の平均値及び標準偏差」から各年齢の身長を男女別で可視化します。正直データの解析がしんどいので繰り返しがなければ手動でCSVをダウンロードする方が早かったです。
手順としては下記の通りです。
目的データの確認:取得したいデータがあるかe-statのサイトで確認
URL取得:e-statのサイトから「API」ボタンを押し「APIリクエストURL」からファイル形式を指定(今回はJSON or CSV)してURLをコピー
リクエスト:Requests(HTTPクライアント)でAPIからデータを抽出
データの中身確認:JSON:各KEYから中身を確認、CSV:いったんCSVファイルを作成して中身を確認
データ解析:基本的にはPandasを使用して可視化するためのデータを抽出できるように前処理
可視化:グラフ作成
下記コードではJSONとCSVの両方でリクエストを送り下記実施しました。
●JSON:出力のKEYを作成してどのようなKEYがあるか確認した。第一出力は['GET_STATS_DATA']のみ、['GET_STATS_DATA']には『(['RESULT', 'PARAMETER', 'STATISTICAL_DATA']』の3つがあり、基本的に全データ['STATISTICAL_DATA']に含まれていた。
●CSV:出力はテキスト形式で取得される。Pandasで処理したいため一度CSVファイルに書き込む(CSVファイルの中身は下図の通り)。
[IN]
import requests
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
import os
import glob
#APIリクエストURLのAPIキーを置き換える関数
def insert_APIkey(endpoint, appId):
return endpoint.replace('appId=', f'appId={appId}')
#APIでデータ取得
appId_estat = 'APIキーを入れてね' #APIキー
endpoint_csv = 'http://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId=&lang=J&statsDataId=0003224177&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0'
endpoint_json = 'http://api.e-stat.go.jp/rest/3.0/app/json/getStatsData?appId=&lang=J&statsDataId=0003224177&metaGetFlg=Y&cntGetFlg=N&explanationGetFlg=Y&annotationGetFlg=Y§ionHeaderFlg=1&replaceSpChars=0'
url = insert_APIkey(endpoint_json, appId_estat) #エンドポイント
res_json = requests.get(url) #リクエスト送信(GET)
#JSONの解析
keys = res_json.json()['GET_STATS_DATA'].keys()
print(keys) #dict_keys(['RESULT', 'PARAMETER', 'STATISTICAL_DATA'])
main_data = res_json.json()['GET_STATS_DATA']['STATISTICAL_DATA'] #STATISTICAL_DATAのデータを取得
print(main_data.keys()) #dict_keys(['RESULT_INF', 'TABLE_INF', 'CLASS_INF', 'DATA_INF'])
#CSVの解析
url = insert_APIkey(endpoint_csv, appId_estat) #エンドポイント
res_csv = requests.get(url) #リクエスト送信(GET)
if not os.path.exists('data'):
os.makedirs('data')
with open('data/csv_data_身長体重.csv', 'w') as f:
f.write(res_csv.text)
[OUT]
dict_keys(['RESULT', 'PARAMETER', 'STATISTICAL_DATA'])
dict_keys(['RESULT_INF', 'TABLE_INF', 'CLASS_INF', 'DATA_INF'])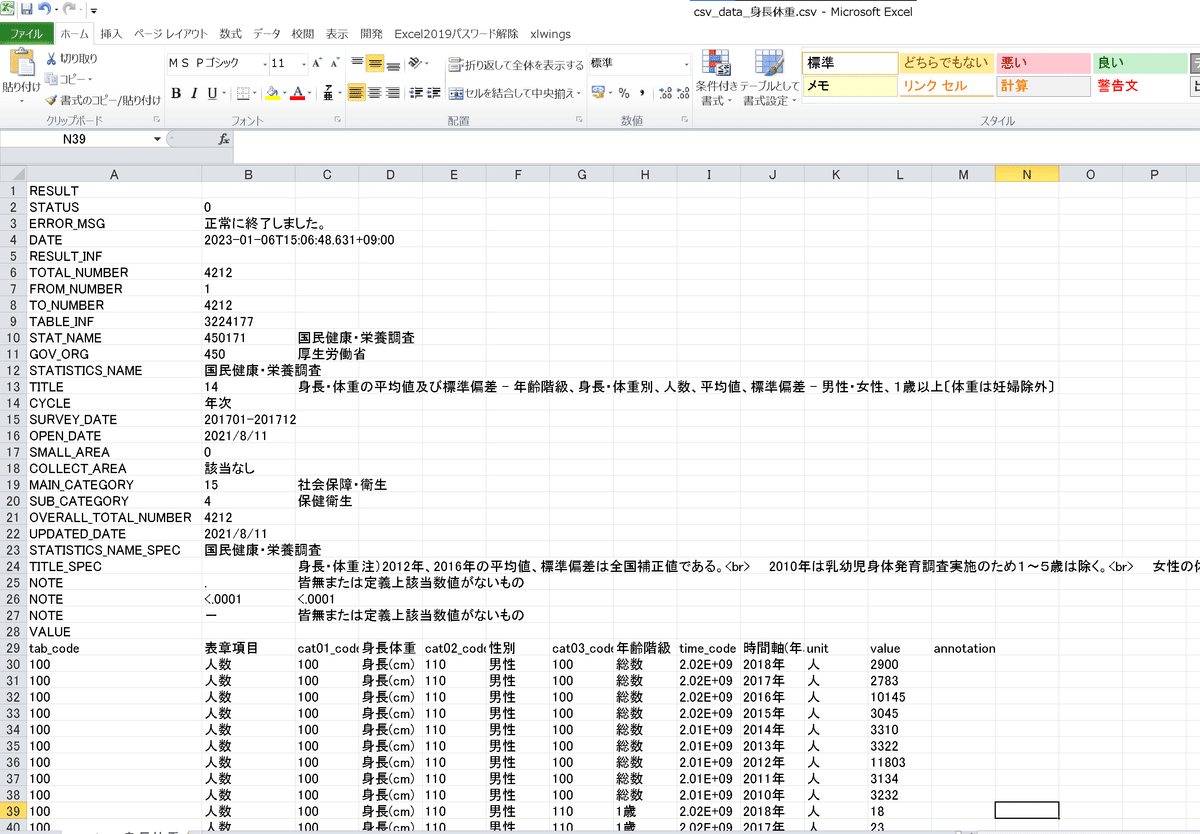
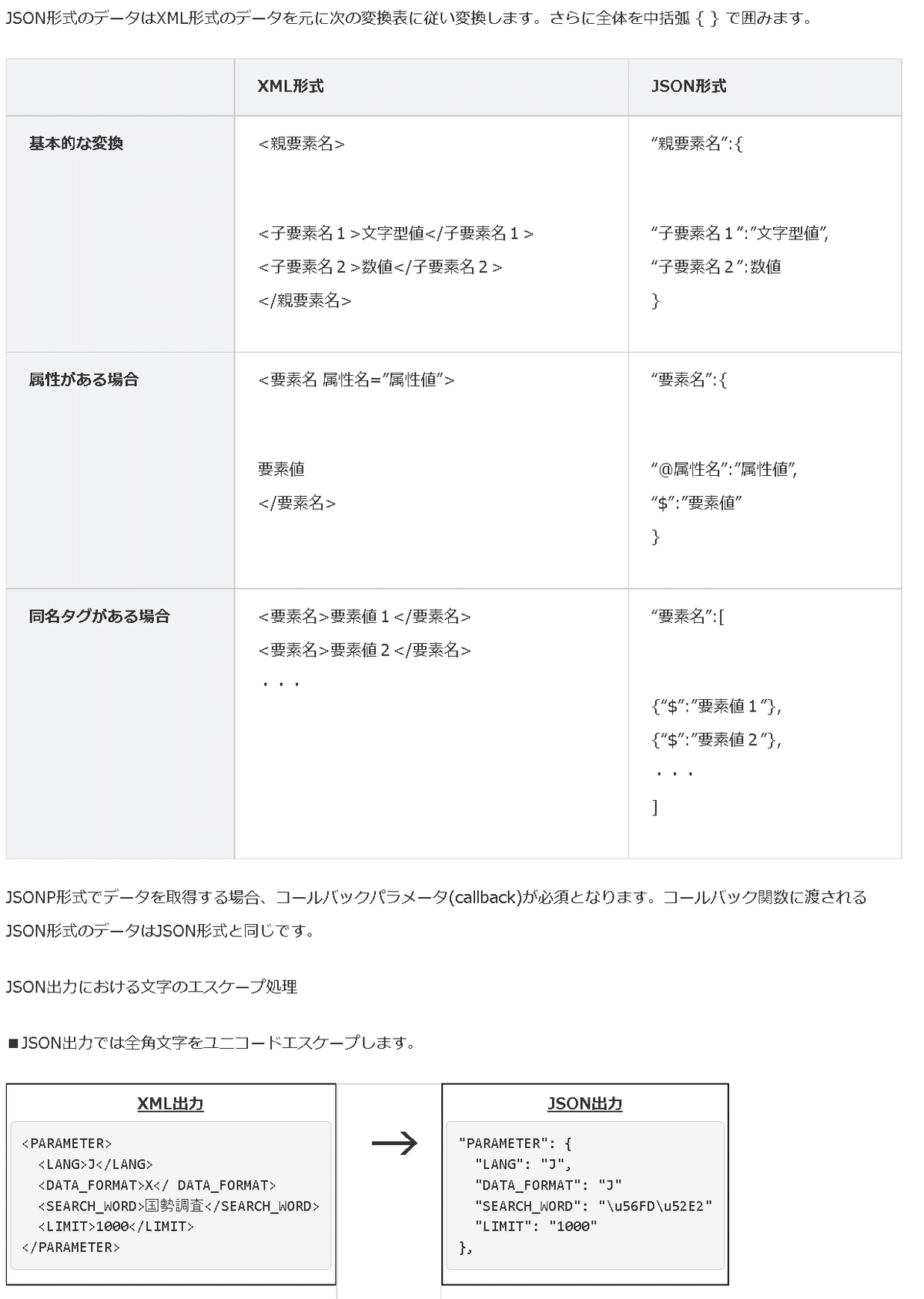
データが取得できたら、後はコツコツとKEYからデータを抽出していき最後にグラフを作成しました。下記はJSON形式で処理しておりますが、中身は下記の通りです。
統計データは['DATA_INF']['VALUE']、クラス情報は['DATA_INF']['VALUE']に入っている。
統計データ:['DATA_INF']['VALUE']は単一カラムである。よってサイトの形式とは異なることに注意が必要である(CSV形式でも同様)。
統計データ['DATA_INF']['VALUE']の初期値ではカテゴリカルデータ(例:性別や年齢階級など)が数値で入力されている。カテゴリカルデータの対応値は['DATA_INF']['VALUE']に入っているため、各idでデータの前処理が必要
欲しいデータを抽出する必要があるためPandasのqueryメソッドを使用
queryメソッドでなぜか「年齢階級の再掲」をうまく処理できなかったため、別処理を追加
統計量はColumnsの['$']に入っている。初期値?は文字列のため、Floatに変換
[IN]
df_data = pd.DataFrame(main_data['DATA_INF']['VALUE'])
df_class = pd.DataFrame(main_data['CLASS_INF']['CLASS_OBJ'])
#カラム名を整える
def replace_col(col_origin, col_rep):
output = list(col_origin.copy())
#originの長さがrepの長さより短い場合はError
if len(col_origin) < len(col_rep):
raise ValueError('交換元の列のデータ数が不足しています')
for idx, col in enumerate(col_rep):
output[idx] = col
return output
cols = replace_col(df_data.columns, df_class['@name'])
df_data.columns = cols
display(df_data.head())
display(df_class.head())
code2name_dict = {}
for key, data_class in zip(df_class['@name'], df_class['CLASS']):
#@codeと@nameの辞書作成
code2name = {data['@code']:data['@name'] for data in data_class}
code2name_dict[key] = code2name
#カテゴリカルデータを名前に変換
for key in df_class['@name']:
df_data[key] = df_data[key].map(code2name_dict[key])
display(df_data.head())
#2018年のデータを抽出
df_data2018 = df_data[df_data['時間軸(年次)']=='2018年']
#男性の平均身長のデータを抽出
query_men = '''
性別=="男性" and
表章項目=="平均値" and
身長体重=="身長(cm)" and
"総数" not in 年齢階級 and
"(再掲)" not in 年齢階級
'''
df_data2018_men = df_data2018.query(query_men.replace('\n ',''))
mask = [True if not '(再掲)' in x else False for x in df_data2018_men['年齢階級']]
df_data2018_men = df_data2018_men[mask]
#女性の平均身長のデータを抽出
query_women = '''
性別=="女性" and
表章項目=="平均値" and
身長体重=="身長(cm)" and
"総数" not in 年齢階級 and
"(再掲)" not in 年齢階級
'''
df_data2018_women = df_data2018.query(query_women.replace('\n ',''))
mask = [True if not '(再掲)' in x else False for x in df_data2018_women['年齢階級']]
df_data2018_women = df_data2018_women[mask]
#値を文字列から小数点データに変更
df_data2018_men['$'] = df_data2018_men['$'].astype(float)
df_data2018_women['$'] = df_data2018_women['$'].astype(float)
mean_men, mean_women = df_data2018_men['$'].mean(), df_data2018_women['$'].mean()
#可視化
plt.figure(figsize=(10, 5))
plt.bar(df_data2018_men['年齢階級'], df_data2018_men['$'], label='男性',
align='edge', width=-0.5, color='royalblue')
plt.bar(df_data2018_women['年齢階級'], df_data2018_women['$'], label='女性',
align='edge', width=0.5, color='tomato')
plt.plot(df_data2018_men['年齢階級'], np.ones(len(df_data2018_men))*mean_men, label='男性平均',
color='blue', linestyle='--')
plt.plot(df_data2018_women['年齢階級'], np.ones(len(df_data2018_women))*mean_women, label='女性平均',
color = 'red', linestyle='--')
plt.xticks(rotation=90)
plt.grid()
plt.legend()
plt.show()
[OUT]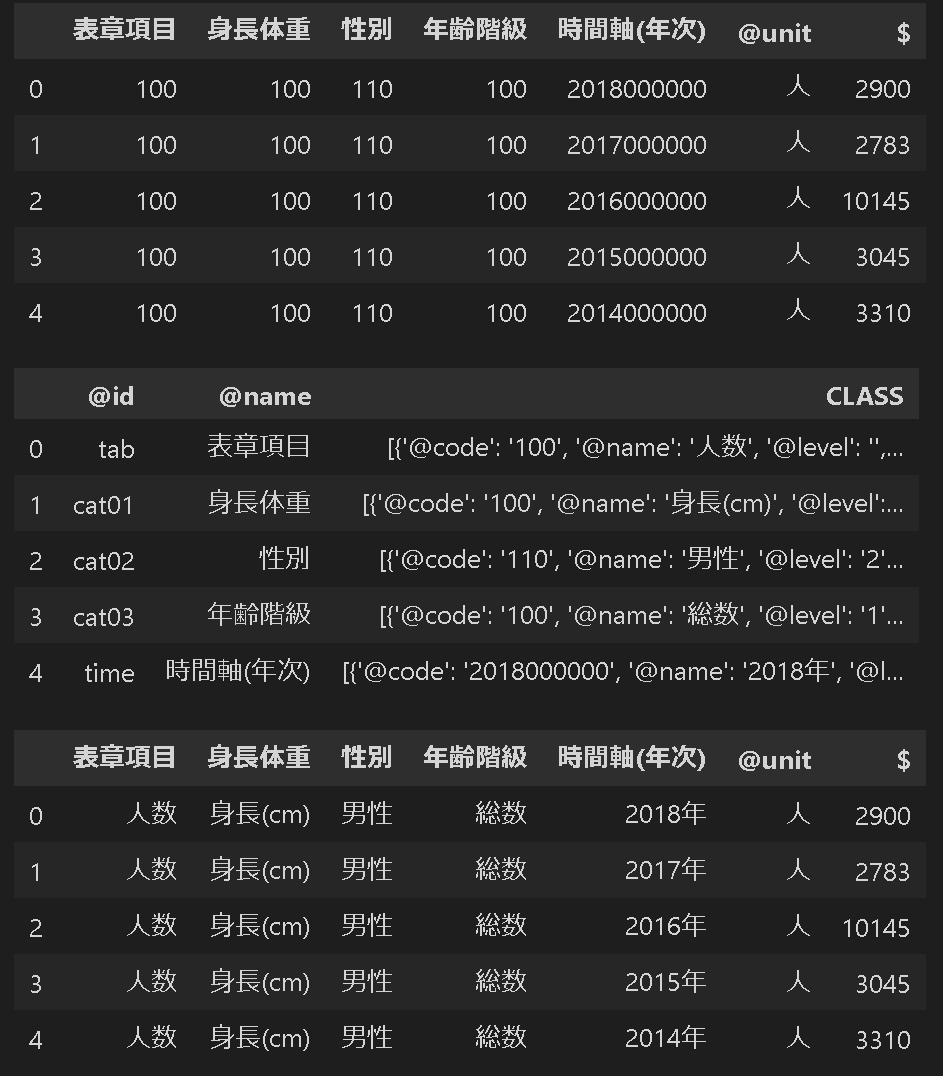

参考資料
統計データの探し方


API関係/その他
Python
あとがき
JSONの解析方法は追って追記予定。取り急ぎ発行