
Pythonライブラリ(音声認識):Whisper

1.緒言
1-1.概要
2022年9月22日にOpenAIから高精度な音声認識モデルのWhisperが公開されました。本記事ではこちらを実装してみます。
We've trained a neural net called Whisper that approaches human-level robustness and accuracy on English speech recognition. It performs well even on diverse accents and technical language. Whisper is open source for all to use. https://t.co/ueVywYPEkK
— OpenAI (@OpenAI) September 21, 2022
【実装無しで試したい方向け】
すぐに性能だけでも試したい方は下記サイトからトライアルできます。
1-2.モデルの概要
公式より下図参照



2.環境構築
Whisperが使用できるように環境構築を実施します。
参考までに、サンプルファイルは音声データ(mp3, wav, w4aなど)であればなんでもよいですが本記事ではyoutube-dlを使用してyoutubeからサンプルオーディオファイルを取得しました。
[TERMINAL]
pip install youtube-dl
youtube-dl --extract-audio https://www.youtube.com/watch?v=Yx1CqlmLJSs
[OUT]
千鳥・ノブがSKE48須田亜香里にNG発言連発!? 千鳥MC『チャンスの時間 # 129』-Yx1CqlmLJSs.m4a が生成される
2-1.ライブラリのインストール
「WhisperのGitHub」を参照して環境構築します。

Google Colabで使用する場合は下記のみで十分です。
[IN]
pip install git+https://github.com/openai/whisper.git
[OUT]2-2.Windowsでの環境構築
基本的な環境構築は下記記載のAnaconda+Pytorchの環境構築のみでいけました。
【謎のエラー】
Whisperインストール後にコード実行すると下記エラーがでました。

念のため下記実行しましたが既にAnaconda?には既にインストール済みでありエラーも消えませんでした。念のため"pip freeze"でインストール済みライブラリを確認してもlockfileは出ませんでした。
一度IDE(VS CODE)を閉じて再度実行したら何故かエラーは消えました。
[TERMINAL]
pip install filelock
pip freeze
3.モデルの実装
3-1.Pythonによる実装方法:シンプルVer.
最もシンプルな方法は公式記事より下記の通りです。下記のみでそこそこな精度(次節のlargeモデルは高精度)の音声認識ができております。
[IN]
import whisper
path_audio = '千鳥・ノブがSKE48須田亜香里にNG発言連発!? 千鳥MC『チャンスの時間 # 129』-Yx1CqlmLJSs.m4a'
model = whisper.load_model('base')
result = model.transcribe(path_audio)
print(result["text"])
[OUT]
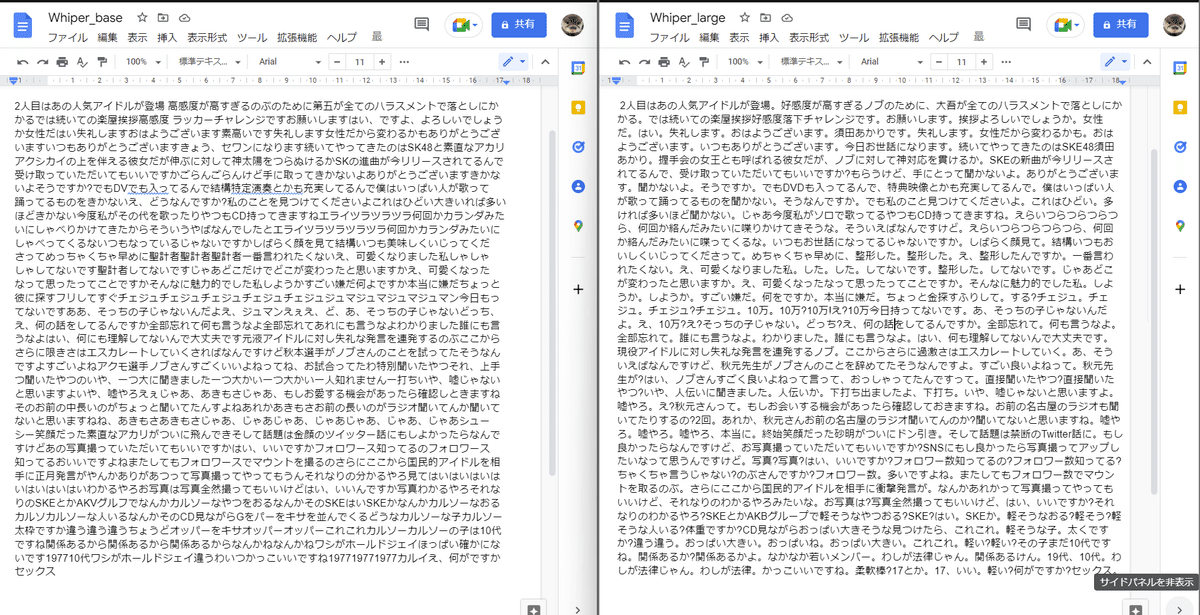
2人目はあの人気アイドルが登場 高感度が高すぎるのぶのために第五が全てのハラスメントで落としにかかるでは続いての楽屋挨拶高感度 ラッカーチャレンジですお願いしますはい、ですよ、よろしいでしょうか女性だはい失礼しますおはようございます素高いです失礼します女性だから変わるかもありがとうございますいつもありがとうございますきょう、セワンになります続いてやってきたのはSK48と素直なアカリアクシカイの上を伴える彼女だが伸ぶに対して神太陽をつらぬけるかSKの進曲が今リリースされてるんで受け取っていただいてもいいですかごらんごらんけど手に取ってきかないよありがとうございますきかないよそうですか?でもDVでも入ってるんで結構特定演奏とかも充実してるんで僕はいっぱい人が歌って踊ってるものをきかないえ、どうなんですか?私のことを見つけてくださいよこれはひどい大きいれば多いほどきかない今度私がその代を歌ったりやつもCD持ってきますねエライツラツラツラ何回かカランダみたいにしゃべりかけてきたからそういうやばなんでしたとエライツラツラツラツラ何回かカランダみたいにしゃべってくるないつもなっているじゃないですかしばらく顔を見て結構いつも美味しくいじってくださってめっちゃくちゃ早めに聖計者聖計者聖計者一番言われたくないえ、可愛くなりました私しゃしゃしゃしてないです聖計者してないですじゃあどこだけでどこが変わったと思いますかえ、可愛くなったなって思ったってことですかそんなに魅力的でした私しようかすごい嫌だ何よですか本当に嫌だちょっと彼に探すフリしてすぐチェジュチェジュチェジュチェジュチェジュジュマジュマジュマジュマン今日もってないですああ、そっちの子じゃないんだよえ、ジュマンえぇえ、ど、あ、そっちの子じゃないどっち、え、何の話をしてるんですか全部忘れて何も言うなよ全部忘れてあれにも言うなよわかりました誰にも言うなよはい、何にも理解してないんで大丈夫です元液アイドルに対し失礼な発言を連発するのぶここからさらに限きさはエスカレートしていくさればなんですけど秋本選手がノブさんのことを試ってたそうなんですよすごいよねアクモ選手ノブさんすごくいいよねってね、お試合ってたわ特別聞いたやつそれ、上手つ聞いたやつのいや、一つ大に聞きました一つ大かい一つ大かい一人知れません一打ちいや、嘘じゃないと思いますよいや、嘘やろえぇじゃあ、あきもさじゃあ、もしお愛する機会があったら確認しときますねそのお前の中長いのがちょっと聞いてたんすよねあれかあきもさお前の長いのがラジオ聞いてんか聞いてないと思いますねね、あきもさあきもさじゃあ、じゃあじゃあ、じゃあじゃあ、じゃあ、じゃあシューシー笑顔だった素直なアカリがついに飛んできそして話題は金顔のツイッター話にもしよかったらなんですけどあの写真撮っていただいてもいいですかはい、いいですかフォロワース知ってるのフォロワース知ってるおいいですよねまたしてもフォロワースでマウントを撮るのさらにここから国民的アイドルを相手に正月発言がやんかありがあつって写真撮ってやってもうんそれなりの分かるやろ見てはいはいはいはいはいはいはいわかるやろお写真は写真全然撮ってもいいけどはい、いいんですか写真わかるやろそれなりのSKEとかAKVグルフでなんかカルソーなやつをおるなんかそのSKEはいSKEかなんかカルソーなおるカルソカルソーな人いるなんかそのCD見ながらGをパーをキサを並んでくるどうなカルソーな子カルソー太枠ですか違う違う違うちょうどオッパーをキサオッパーオッパーこれこれカルソーカルソーの子は10代ですね関係あるから関係あるから関係あるからなんかねなんかねワシがホールドジェイほっぱい確かにないです197710代ワシがホールドジェイ違うわいつかっこいいですね197719771977カルイえ、何がですかセックス注意点として「GPUあり」で使用しないと"FP16 is not supported on CPU; using FP32 instead”というエラーが発生します。

参考までに出力したテキストはファイルへの書き込みで保存できます。
[IN]
with open('transcription.txt', 'w') as f:
f.write(result['text'])
[OUT]
transcription.txt が生成3-2.モデルの設定
Whisperではモデルを5種類(うち4種は英語オンリーモードあり)を選択可能です。最も性能が高そうな"large"を使用して"base"と比較しました。

[IN]
import whisper
path_audio = '千鳥・ノブがSKE48須田亜香里にNG発言連発!? 千鳥MC『チャンスの時間 # 129』-Yx1CqlmLJSs.m4a'
model = whisper.load_model('large')
result = model.transcribe(path_audio)
print(result["text"])
[OUT]
2人目はあの人気アイドルが登場。好感度が高すぎるノブのために、大吾が全てのハラスメントで落としにかかる。では続いての楽屋挨拶好感度落下チャレンジです。お願いします。挨拶よろしいでしょうか。女性だ。はい。失礼します。おはようございます。須田あかりです。失礼します。女性だから変わるかも。おはようございます。いつもありがとうございます。今日お世話になります。続いてやってきたのはSKE48須田あかり。握手会の女王とも呼ばれる彼女だが、ノブに対して神対応を貫けるか。SKEの新曲が今リリースされてるんで、受け取っていただいてもいいですか?もらうけど、手にとって聞かないよ。ありがとうございます。聞かないよ。そうですか。でもDVDも入ってるんで、特典映像とかも充実してるんで。僕はいっぱい人が歌って踊ってるものを聞かない。そうなんですか。でも私のこと見つけてくださいよ。これはひどい。多ければ多いほど聞かない。じゃあ今度私がソロで歌ってるやつもCD持ってきますね。えらいつらつらつらつら、何回か絡んだみたいに喋りかけてきそうな。そういえばなんですけど。えらいつらつらつらつら、何回か絡んだみたいに喋ってくるな。いつもお世話になってるじゃないですか。しばらく顔見て。結構いつもおいしくいじってくださって。めちゃくちゃ早めに、整形した。整形した。え、整形したんですか。一番言われたくない。え、可愛くなりました私。した。した。してないです。整形した。してないです。じゃあどこが変わったと思いますか。え、可愛くなったなって思ったってことですか。そんなに魅力的でした私。しようか。しようか。すごい嫌だ。何をですか。本当に嫌だ。ちょっと金探すふりして。する?チェジュ。チェジュ。チェジュ?チェジュ。10万。10万?10万!え?10万今日持ってないです。あ、そっちの子じゃないんだよ。え、10万?え?そっちの子じゃない。どっち?え、何の話をしてるんですか。全部忘れて。何も言うなよ。全部忘れて。誰にも言うなよ。わかりました。誰にも言うなよ。はい、何も理解してないんで大丈夫です。現役アイドルに対し失礼な発言を連発するノブ。ここからさらに過激さはエスカレートしていく。あ、そういえばなんですけど、秋元先生がノブさんのことを辞めてたそうなんですよ。すごい良いよねって。秋元先生が?はい、ノブさんすごく良いよねって言って、おっしゃってたんですって。直接聞いたやつ?直接聞いたやつ?いや、人伝いに聞きました。人伝いか。下打ち出ましたよ、下打ち。いや、嘘じゃないと思いますよ。嘘やろ。え?秋元さんって。もしお会いする機会があったら確認しておきますね。お前の名古屋のラジオも聞いてたりするの?2回。あれか、秋元さんお前の名古屋のラジオ聞いてんのか?聞いてないと思いますね。嘘やろ。嘘やろ。嘘やろ、本当に。終始笑顔だった砂明がついにドン引き。そして話題は禁断のTwitter話に。もし良かったらなんですけど、お写真撮っていただいてもいいですか?SNSにもし良かったら写真撮ってアップしたいなって思うんですけど。写真?写真?はい、いいですか?フォロワー数知ってるの?フォロワー数知ってる?ちゃくちゃ言うじゃない?のぶさんですか?フォロワー数。多いですよね。またしてもフォロワー数でマウントを取るのぶ。さらにここから国民的アイドルを相手に衝撃発言が。なんかあれかって写真撮ってやってもいいけど、それなりのわかるやろみたいな。お写真は?写真全然撮ってもいいけど、はい、いいですか?それなりのわかるやろ?SKEとかAKBグループで軽そうなやつおる?SKE?はい。SKEか。軽そうなおる?軽そう?軽そうな人いる?体重ですか?CD見ながらおっぱい大きそうな見つけたら、これこれ。軽そうな子。太くですか?違う違う。おっぱい大きい。おっぱいね。おっぱい大きい。これこれ。軽い?軽い?その子まだ10代ですね。関係あるか?関係あるかよ。なかなか若いメンバー。わしが法律じゃん。関係あるけん。19代、10代。わしが法律じゃん。わしが法律。かっこいいですね。柔軟棒?17とか。17、いい。軽い?何がですか?セックス。"large"モデルは細かい単語の精度や文字起こしの見やすさ(カタカナではなく漢字や数値への置き換え)の精度が圧倒的に上がっています。
3-3.詳細な引数の設定
その他設定できそうな引数は下記のようなものがあります。
[whisper/transcribe.py] ※一部抜粋
def cli():
from . import available_models
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter)
parser.add_argument("audio", nargs="+", type=str, help="audio file(s) to transcribe")
parser.add_argument("--model", default="small", choices=available_models(), help="name of the Whisper model to use")
parser.add_argument("--model_dir", type=str, default=None, help="the path to save model files; uses ~/.cache/whisper by default")
parser.add_argument("--device", default="cuda" if torch.cuda.is_available() else "cpu", help="device to use for PyTorch inference")
parser.add_argument("--output_dir", "-o", type=str, default=".", help="directory to save the outputs")
parser.add_argument("--verbose", type=str2bool, default=True, help="whether to print out the progress and debug messages")
parser.add_argument("--task", type=str, default="transcribe", choices=["transcribe", "translate"], help="whether to perform X->X speech recognition ('transcribe') or X->English translation ('translate')")
parser.add_argument("--language", type=str, default=None, choices=sorted(LANGUAGES.keys()) + sorted([k.title() for k in TO_LANGUAGE_CODE.keys()]), help="language spoken in the audio, specify None to perform language detection")
parser.add_argument("--temperature", type=float, default=0, help="temperature to use for sampling")
parser.add_argument("--best_of", type=optional_int, default=5, help="number of candidates when sampling with non-zero temperature")
parser.add_argument("--beam_size", type=optional_int, default=5, help="number of beams in beam search, only applicable when temperature is zero")
parser.add_argument("--patience", type=float, default=None, help="optional patience value to use in beam decoding, as in https://arxiv.org/abs/2204.05424, the default (1.0) is equivalent to conventional beam search")
parser.add_argument("--length_penalty", type=float, default=None, help="optional token length penalty coefficient (alpha) as in https://arxiv.org/abs/1609.08144, uses simple length normalization by default")
parser.add_argument("--suppress_tokens", type=str, default="-1", help="comma-separated list of token ids to suppress during sampling; '-1' will suppress most special characters except common punctuations")
parser.add_argument("--initial_prompt", type=str, default=None, help="optional text to provide as a prompt for the first window.")
parser.add_argument("--condition_on_previous_text", type=str2bool, default=True, help="if True, provide the previous output of the model as a prompt for the next window; disabling may make the text inconsistent across windows, but the model becomes less prone to getting stuck in a failure loop")
parser.add_argument("--fp16", type=str2bool, default=True, help="whether to perform inference in fp16; True by default")
parser.add_argument("--temperature_increment_on_fallback", type=optional_float, default=0.2, help="temperature to increase when falling back when the decoding fails to meet either of the thresholds below")
parser.add_argument("--compression_ratio_threshold", type=optional_float, default=2.4, help="if the gzip compression ratio is higher than this value, treat the decoding as failed")
parser.add_argument("--logprob_threshold", type=optional_float, default=-1.0, help="if the average log probability is lower than this value, treat the decoding as failed")
parser.add_argument("--no_speech_threshold", type=optional_float, default=0.6, help="if the probability of the <|nospeech|> token is higher than this value AND the decoding has failed due to `logprob_threshold`, consider the segment as silence")
parser.add_argument("--threads", type=optional_int, default=0, help="number of threads used by torch for CPU inference; supercedes MKL_NUM_THREADS/OMP_NUM_THREADS")参考資料
参考資料1:実装関係
参考資料2:技術関係
Whisperの日本語fine-tuningについて、Hugging Faceブログに沿ってやる方法を書きました。
— nokomoro3 (@nokomoro3) November 9, 2022
自社データの活用もこれでできるやも?#DevelopersIO Hugging FaceでOpenAIの音声認識”Whisper”をFine Tuningする方法が公開されました https://t.co/lvGGxH3uAn
やっぱり CPU 推論だけはあって GPU よりは遅いっぽいけど、グラボ依存なしに動くのは強いな
— Torishima (@izutorishima) November 7, 2022
Whisper CPP で C/C++ で音声認識を極めたいメモ https://t.co/EKhXdGnB8I #Qiita
なんか OpenAI が出した高性能音声認識 AI Whisper の C++ 移植版が出てるんだけど…!?!?!?!?
— Torishima (@izutorishima) November 7, 2022
謎の最適化技術で CPU だけでそこそこ高速に文字起こしできるようになってるらしく、large モデルでも最大で 4.7GB のメモリしか使わないらしいのが驚異的過ぎる 革命https://t.co/ZfGKVDqrWK
あとがき
取り急ぎ先出し。自宅PCのGPU使ってbaseモデルで実行すると1.5minくらいかかるのでCPUでの実行は非現実的かと思うので記載は取りやめ。
この記事が気に入ったらサポートをしてみませんか?