SNSのテキストをクラスタリングしてみたので備忘録的に(1/2)

今日は趣向を変えて最近勉強したことをメモ書き程度に書こうと思う。
僕は仕事でSNSに投稿されたデータの分析をしている。
何万件と言うビッグデータから、良い示唆を得るためには、様々な分析手法を学ぶ必要がある。
と言うことで最近は、テキストマイニング について勉強してみた。
元々統計やプログラミング初心者なのだが、初心者だからこその視点も参考になるかと思うので自分の備忘録も込めて紹介したい。
テキストマイニングとは
テキストマイニングとは「大量のテキストデータから有効な情報を取り出すことの総称」である。
例えば、Twitterの投稿データから、今後バズりそうなキーワードを分析するだとか、就活のエントリーシートから、将来出世する人が共通して使うキーワードを明らかにする。などなどいろんな分析手法がある。
今回やったこと
投稿エリアごとにどのような投稿パターンがあるかクラスタリングすれば、そのエリアでの典型的な行動パターンがわかるのでは?と言う仮説のもと、Twitterの投稿テキストをクラスタリングするスクリプトを書いてみた。
環境
こんな感じ
jupyter notebook
python3.8
scikit-learn(クラスタリングをするときに必要)
pandas(元々SNSのテキストデータ自体CSVで所持していたので
janome(自然言語解析のために必要)
matplotlib(クラスタリング結果をプロットしてみたい)
math(文章を数値化する工程で必要)
処理工程とコード
1.テキストデータのCSVファイルを読み込む
import pandas
twitter_text_data = pd.read_csv('Twitter_text_data.csv')※Twitter_text_data.csvにはuser_id,text.tweeted_atカラムが存在している。
2.CSVファイルからテキストデータのみを取り出し、janome.tokenizerで動かせるようにしておく
texts = list(twitter_text_data['text'])3.janome.tokenizerを用いて、投稿テキストを分かち書きする※
from janome.tokenizer import Tokenizer
t = Tokenizer()
word_list = []
for text in texts:
wakati_text = t.tokenize(text,wakati=True)
word_list.append(wakati_text)
※日本語は英語と違って単語が全てつながっているので品詞ごとに分ける処理が必要。これを分かち書きと呼ぶ。
4.全投稿テキスト分の固有キーワードリストを作る
unique_words = []
for words in word_list:
for word in words:
if word not in unique_words:
unique_words.append(word)
5.各テキストごとに、固有キーワードリスト内のキーワードが何個入っているか数える
bow_list =[]
for words in word_list:
bag =[]
for unique_word in unique_words:
num = words.count(unique_word)
bag.append(num)
bow_list.append(bag)6.重要度の低い言葉対策として、TF-IDFと言う数値に変換する
from math import log
n = len(descripts)
idf=[]
for i in range(len(unique_words)):
count= 0
for bow in bow_list:
if bow[i]>0:
count+=1
idf.append(log((n+1)/(count+1)))
tfidfs = []
for bow in bow_list:
tfidf = []
n=len(bow)
for i, value in enumerate(bow):
tf = value/n
tfidf.append(tf*(idf[i]+1))
tfidfs.append(tfidf)
3以降の処理について具体例を用いて解説
例えば「月が綺麗だ」と「お前があほだ」と言う二つの文章で考えてみよう。
この二文を分かち書きすると
月 / が / 綺麗 / だ
お前 / が / あほ / だ
となる。
そしてこの二文より固有キーワードリストを作ると。
キーワードリスト =(月、が、綺麗、だ、お前、あほ)
となる。
このリストを元にして、先ほど挙げた二文にリスト内のキーワードの出現頻度をカウントするのだ。
カウントしてみると
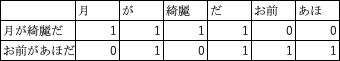
こんな感じになる。
仮に「月が綺麗だお前があほだ」と言う文章だとこうなる。

助詞の「が」と「だ」が2個カウントされているのがわかるだろう。
このようにしてテキストを数値に変換することができる。
しかし、これだと問題がある。どんな文章でもよく使われる言葉が頻出ワードとして認識されてしまうのだ。
上の図で言うと「が」とか「だ」は文章の中ではそんな大したことのない助詞なのに登場回数が多い。
もしこれがTwitterの中で頻出キーワードを分析するテキストマイニング をしているとすると、頻出は助詞の「が」と言う結果になってしまい、分析として全く使えない結果となってしまう。
このような問題を解決する手段として、TF-IDFと言う手法を使う。
これは単語の重要度を評価する手法だ。
TF-IDFはTF×IDFで表されるがそもそもその二つの意味が不明だ。
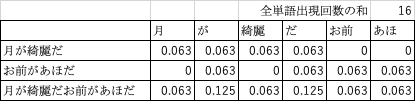
TFと言うのは単語の出現頻度のこと。これの計算式は以下の通りである。
単語の文章内での出現回数÷文章の中の全ての単語の出現回数の和
さっきの表で計算するとこのようになる。
次にIDFとはある単語が出てくる文書頻度の逆数になる。これはさっきの「が」や「だ」などは低くなる。
計算式は
log(全文書数÷ある単語が出現する文書の数)
log(対数)が苦手な人は数学2を勉強してほしい。
さっきので計算するとこうなる
![]()
あら不思議。「が」と「だ」がゼロになったので頻出ワードには出てこない。やったぜ
そしてTFとIDFをかけてみると、、、

このようになる。
これで文章の数値化が完了した。
エクセルでやるとcountif関数やらなんやら使わないといけないし、そもそも最初の分かち書きやキーワードの出現頻度を数えるなんてまぁまぁ泣けてくるのだが、Pythonを使うとものの数秒で終わってしまうのだからすごい。
次回は数値化した文章をクラスタリングしてみるところまでやってみようと思う。
この記事が気に入ったらサポートをしてみませんか?