SNSのテキストをクラスタリングしてみたので備忘録的に(2/2)

昨日の記事でテキストデータを数値化するところまでやったのでクラスタリングしてみるとこまでやってみる。
7.クラスタリングを行う
from sklearn.cluster import KMeans
km = KMeans(n_clusters=15,random_state=0)
clusters = km.fit(tfidfs)8.各テキストのラベルを元データに結合する
cluster = pd.Series(clusters.labels_)
img_with_cluster = pd.concat([twitter_text_data,cluster],axis=1)
img_with_cluster.rename(columns={0:'cluster'},inplace=True)これで一旦必要な処理は終了。
ただ、どんな感じでクラスタリングされているか散布図で見てみないと、クラスター数が適切かわからない。
そこで必要なのが、主成分分析→縦横の散布図にプロットと言う流れ。
9.主成分分析をしてみる
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(tfidfs)
x_pca = pca.transform(tfidfs)
pca_df = pd.DataFrame(x_pca)
pca_df['cluster']=img_with_cluster['cluster']10.散布図でプロットしてみる
import matplotlib.pyplot as plt
%matplotlib inline
for i in img_with_cluster['cluster'].unique():
tmp = pca_df.loc[pca_df['cluster']==i]
plt.scatter(tmp[0],tmp[1])結果は・・・
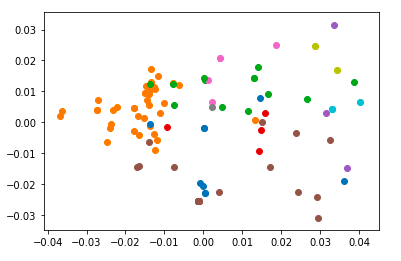
うーむ、、、、。綺麗にクラスタリングはできていないものの。オレンジ色のプロットを見てみると一部クラスターができているようにも見える。
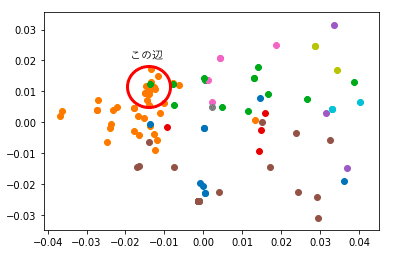
なのでこの辺のツイートを細かく見ていけば特徴的な投稿内容をみることができるかもしれない。
課題に感じたこと
課題点としては
・適切なクラスター数を総当たりで計算しているのでかなりめんどくさい。(もちろんエクセルでやるより楽なんだが)
・そもそもK-MEAN法じゃないクラスタリングの方法も検討した方が良いかもしれない。
今後やってみたいこと
課題の解決もだが。
・テキストマイニング で数値化した文章データを説明変数に、スキ数や閲覧数を目的変数とした重回帰分析
・リツイート傾向などを分析し、リツイートされやすい文章の自動生成
こんなことできたら面白そうと感じた。
この記事が気に入ったらサポートをしてみませんか?