
文字組の話(広域調整)

今回は広域調整の話をしようと思います。
広域調整とはなんでしょうか。
今回もChatGPTに聞いてみましょう。
「文字組の広域調整」というのは、文書全体や複数の段落にわたって、文字の配置や間隔を調整して、読みやすく美しいレイアウトを作る作業のことです。具体的には、行間、文字の間隔(字間)、段落の位置などを調整して、全体が見やすく、バランスの取れた文章にすることが目的です。
広域調整は、以下のポイントで行われます:
字間調整(カーニング・トラッキング)
文字同士の間隔を調整すること。特に見出しなど、文字が大きい場合は字間が広がりすぎないようにしたり、密すぎないように調整します。
行間調整
行と行の間のスペースを均一にしたり、必要に応じて少し広げたり狭めたりして、読みやすい間隔を保ちます。
段落の揃え方
左揃え、右揃え、中央揃え、均等割り付けなど、段落ごとの配置を決めます。日本語の場合は左揃えが多いですが、場合によっては中央揃えなども用いることで視覚的な変化を作ります。
禁則処理
行頭や行末に「、」「。」といった句読点や、区切りの悪い文字が来ないように調整します。これにより、文章の読みやすさが向上します。
ページ全体のバランス
ページの上や下に余白を適切に設けたり、段落の始まりが均一に揃うようにすることで、視覚的にまとまった印象を与えます。
前回話題にした禁則処理や、最初の方に話題にしたフォントの話で出てきたカーニングも含まれていますね。要は文字、ひいては文章全体を綺麗に読みやすくする工夫なので、スコープの範囲は異なるにせよ、広域調整のポイントとなるわけですね。その他のポイント、行間調整や段落の捉え方、そしてページ全体のバランスは文書レイアウトそのものの話なので此処では割愛します。(センスを問われるところなので私には解説は不可)
一般的な広域調整として思いつく処理としては、文章を表示する領域があり、その領域内に文章を収める調整です(下図)。
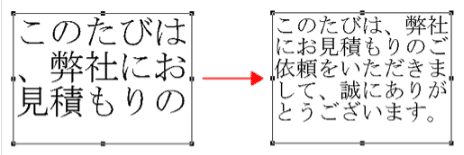
領域に余裕があれば、行間を広げたり、文字間を広げたりして領域を埋めます。領域に余裕がない場合は、行間を縮め、文字サイズや文字間を積め、その領域に文章が収まるように調整を行います。文字間の調整をする際は文字種の組み合わせにより最大値や最小値を持ちます。これら、調整するポイントの各々の調整値、調整する順番をどうデザインするかが腕の見せ所になりますね。
ちなみに弊社のSVFのテキストフレームでは広域調整としては文字サイズの調整が行われます。設定としては最小文字サイズや、調整量を指定することが可能です。(SVFのマニュアル)
もう一つ、別の広域調整があります。禁則処理によって行の文字数に偏りがあった場合に段落全体で行のコンテンツを均一化する調整です。例を出して説明していきます。

上図のように、禁則処理(T9010001174206という文字列が分割禁止のため次の行に追い出し)により、その前行の文字数が他の行に比べて少なくなってしまった場合、行のバランスが非常に悪いです。下図のように「段落の揃え方」の「均等割り付け」で調整したとしても、行の終端は揃えることはできますが、文字の間が不自然に開いてしまって読むのが困難になってしまいます。

ではこの場合はどうすれば読みやすく出来るのでしょうか。
正解は、足りない文字を前の行から借りてくるのです。具体的には行の幅のどれくらいの割合を行として満たすかの閾値を決め、その値が満たされるまで前の行から文字を借ります。その結果、その行がその閾値を満たさなくなってしまった場合、さらに手前の行から文字を借ります。それを延々と繰り返し、上手くいけば最終的に全ての行の文字数(正確には行の空白の大きさ)が均一化され、段落全体としても読みやすくなります。(下図)

ただ、こういった調整を行う課題として、処理コストが高いことが挙げられます。次回は文字組における処理コストの課題について整理してみようと思います。
お読みいただき、ありがとうございました。