
サッカー x 機械学習の最近の研究成果

この記事では、私の研究室におけるサッカーと機械学習に関する最近の研究成果を主に紹介したいと思います。研究室としては、機械学習を用いたスポーツや動物や車などの集団行動の解析を行っています。大まかな話は最近フットボリスタに寄稿したところなので、今回はもう少し細かい話やその他の最新の成果についても紹介したいと思います。研究室のHPも更新したところなので、サッカーあるいはその他スポーツの研究についてはこちらをご覧ください。最後にゲーム理論を導入するクラウドファンディング(2024/1/17~2024/3/14)の話も関連してきますので、そちらもお話しします。
サッカーなどの集団スポーツのプレーを自動で評価するためには、欧州のトップリーグや日本のJリーグで記録されているパスやシュートなどの「イベントデータ」と、選手全員がいつ・どこにいるかを示す「トラッキングデータ」が必要です(後者は基本的に有料です)。前者だけでもボールを持つ選手はある程度評価できますが、後者がなければ守備やボールから遠いオフボールの攻撃選手を評価することが非常に難しくなります。現在のサッカーの現場でも使われているゴール期待値(xG)は、選手全員の位置情報を使わずにボールの位置情報とイベントデータから算出されることが多く、ゴールの一歩手前のシュートを評価していると理解されますが、この方法ではボールを持つ選手の特定のラベル付けされた行動しか評価できません。全選手を評価する枠組みとして、私たちがサッカーについて研究してきたテーマは主に以下の2つがあります。
選手の軌道予測
1つ目は、機械学習を用いた選手の軌道予測手法です。選手の位置や速度などを入力として、次の時刻の位置や速度を予測する深層学習モデルを使うことで、サッカーやバスケットボールの選手位置の予測を十分正確に行うことができることを示してきました(Fujii et al. 2023, Neural Networks)。さらに、プレー評価に繋げるために、数理モデルを用いたスペース評価技術である、「次にどこにパスを出したら得点が入りそうか」という点を数値化する技術(Spearman et al. 2018, MIT SSAC)を活用しました。特に、機械学習による軌道予測を基準に、「基準と比べてどのくらい味方の得点機会の増加に貢献したか」を定量化することで、「味方のためにスペースを空ける動き」を評価することに成功しました(Teranishi et al. 2022 MLSA)。このアイデアは、その守備評価への発展として、もし選手がここに位置していたらという反事実の予測によるチームディフェンスのポジショニングの評価手法にも繋がっています(Umemoto & Fujii 2023, Statsbomb Conf.)。

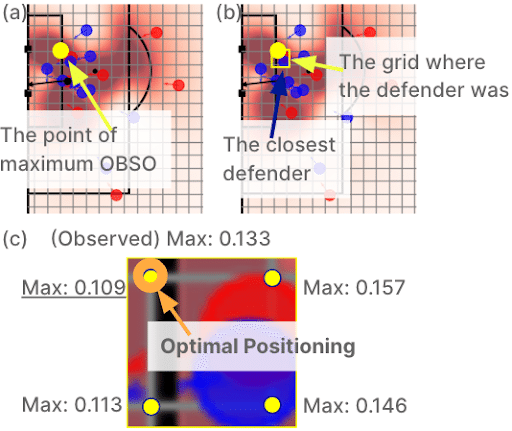
特に、軌道予測の研究と、数理モデルを用いたスペース評価の研究は、これまで別々に発展しており、前者だけでは選手を評価するまで至らず、後者だけではボールを受ける選手だけしか評価ができませんでした。Teranishi et al. 2022の研究はその点、味方のために犠牲となる動き(例えばスペースを空ける動きなど、別のフットボリスタの記事でも説明されています)が評価でき、Umemoto & Fujii 2023の方法では原理的には守備選手のポジショニングも評価できるため、ほぼ全員の動きを評価できる枠組みを提案したことになります。しかし、特にTeranishi et al. 2022の手法は、計算的には評価する選手ごとに軌道予測が必要なため、サッカーの22人を評価するには膨大な計算時間が必要でした。さらにエージェント(選手モデル)の入出力関係(状態を入力として行動を出力)だけを学習しているため、ゴールなどの目標を求めた戦術的な動きを表現できていないという課題がありました。
強化学習
2つ目のトピックである、報酬を得るために行動するエージェントとして選手をモデル化する強化学習は、そのような戦術的に行動するエージェントを学習できる有力な枠組みです。これまで実際の集団スポーツの選手の動きを評価する研究は存在し (Liu et al. 2018, IJCAI; Rahimian et al. 2022, MIT SSAC)、例えば行動ごとに価値を算出できる関数(Q関数)を推定することで、シュートやパスなどのボールに対するアクションを評価していました。しかし、チームを単一のエージェントとして考慮することが多く、すべての時間ステップでオフボールの選手まで評価できないという課題がありました。そのためこれらの課題を克服するために、Google Research Football(GFootball: Kurach et al. 2020, AAAI)を参考にしたエージェントモデルを使って、ゴールなどの単純な報酬に基づく深層強化学習モデルを提案しました(Nakahara et al. 2023, IEEE Access)。離散的な行動として、GFootballを模して8方向の移動や、シュートやパスなどをアクションとして定義し、それぞれの行動の価値(Q値)を出力する深層学習モデルを考えました(詳しくは以下のnoteもご覧ください)。この研究は、初めての試みとして非常に単純なパラメータ設定で検証を行いましたが、より正確にモデル化を行うことで、より正確な評価が可能になると期待されています。
その発展として、「逆強化学習」と「ゲーム理論」の導入により、選手のプレー精度や意思決定の質まで評価する方法を開発するクラウドファンディングのプロジェクトが進行中です。「逆強化学習」とは、選手が何を考えてプレーしているのかを、研究者が考えた報酬に基づいて計算するのではなく、データから推定する方法です。サッカーに逆強化学習を適用した研究はありますが(Luo et al. 2020, IJCAI; Rahimian et al. 2021, MLSA)、ゲーム理論は本格的には導入されていません。ゲーム理論をサッカーなどの集団スポーツに導入するというアイデアは、DeepmindのTuylsらが展望論文(Tuyls et al. 2021, JAIR)を発表し、我々も1対1の状況のシュートに関する分析(Yeung &Fujii, 2023, arXiv)について発表しましたが、前者においてもペナルティキックなどの静的な状況を想定しており、Nakahara et al. 2023のような選手の強化学習モデル化に直接適用するのは困難でした。今回導入しようとしているのは動学ゲーム理論であり、時間の経過とともに連続的または離散的に行動が選択されるゲームにおいて、プレイヤーは過去の行動に基づいて戦略を選択します。この動学ゲーム理論に詳しい香港科技大学の経済学者である川口さんや、東大ア式蹴球部出身で自然言語処理を専門としている染谷さんの紹介も含め、これまでの経緯については、以下のクラウドファンディングのページにて詳しく紹介されています。
その第一歩として、染谷さんと川口さんと一緒に、「言語モデリングによる行動選択・状態推移確率の推定に基づく選手定量評価指標」という題の研究を発表しました(染谷ら, 2024, スポーツデータサイエンスコンペティション優秀賞)。この研究では、ゲーム理論と逆強化学習ベースの戦術評価のために必要なサッカーにおける行動選択確率と状態遷移確率を推定する方法を開発しました。そのために、Transformerベースの言語モデルを用いて、データから仮想の試合モデルを構築し、選手やチームを評価できる手法を提案しました。
2023年度スポーツデータサイエンスコンペティションにて、優秀賞をいただきました!
— Taiga Someya (@agiats_football) January 7, 2024
この研究は引き続き発展させていきますので、今後ともご期待ください!
(後輩のきのけい(@keigo_ashiki )とのツーショットも注目ポイントです) pic.twitter.com/ix3QUW25Tp
現在世界中で考えられていそうなアプローチは、ChatGPTに代表される膨大なデータと大規模な機械学習モデルに基づき、正確な系列予測(今回の場合シミュレーション)を行うようなアプローチです。こちらは染谷さんとスコットさんが産総研の覚醒プロジェクトに採択され、研究を進めています。私たちの研究室でも先行して、イベントデータから次のパスやシュートなどのイベントの種類と場所、時間を予測するTransformerベースのNeuralイベント時空間点過程モデルというのを提案しています(Yeung et al. 2023, arXiv)。また、データだけからシミュレータを作る方法以外にも、数理モデルをベースに状態遷移が可能なシミュレータを作成し、選手の行動を実世界のお手本として活用した強化学習に関する手法も最近開発しています(Fujii et al. 2024, ICAART)。
データの問題
別の大きな問題として、データの絶対量の確保の問題があります。機械学習モデルの学習には大量のデータが必要になりますが、そのためには自分たちで独自に取得するかデータ会社から購入するかしかありません。自分たちで取得したデータは小規模な機械学習モデルの学習や評価には使えますが、今回のような大規模な機械学習モデルの学習に用いるには量が足りません。今回のクラウドファンディングの目的は、学習のための欧州リーグ1シーズン分のデータをデータ会社から購入することです。
データの量さえ確保できれば、分析から得られる示唆はいくらでも豊かになりうると考えています。例えば私たちはこれまで数十試合のトラッキング・イベントデータを使用していましたが、1リーグだと各チーム数試合のためチーム単位での評価か、1シーズンの試合を確保したチームの選手しか評価ができませんでした。1シーズン全試合のデータがあれば、そのシーズンの全チームの主要な選手の評価ができるので、データの量はとても重要です。
ただし、購入したデータは公開できないというデメリットがあります。そのため、私たちの研究室では主に筑波大学の蹴球部(特に、スコットさんと内田さん)と連携して、サッカーの公開トラッキングデータセットとアルゴリズムの研究(Scott et al. 2022, CVSports)などに取り組んでいます。現状でもデータの利活用はまだまだトッププロに限定されており、すべてのカテゴリーで平等に利用できているわけではなく、すべての選手が平等に質の高い指導を受けられる状況にもありません。現在行っているような研究を通じて、そのような知識を誰でも受け取れる世界にしたいというのが私の願いでもあります。
https://github.com/AtomScott/SportsLabKit にてツールキットを公開中。
最後に(クラウドファンディング)
クラウドファンディングでは、上記の動学ゲーム理論と逆強化学習を導入した方法を確立した上で、欧州リーグのデータを用いて選手の意思決定の質とプレー精度を評価してみる予定です。その後は、東京大学のア式蹴球部(サッカー部)などと協力して、概念実証を行いたいと考えています。
このプロジェクトは1月17日の開始と同時に驚異的なペースで支援が集まり、3日目に最初の目標金額を達成しましたが、3月14日17時まで寄付を受け付けています。この資金で欧州リーグ1、2シーズン分のデータを購入して概念実証とユースケースの創出を行い、今後多くの人にこの技術を使ってもらえるための第一歩としたいと考えています。ご支援をいただけると幸いです!
(追記:下記のリンクより、開始から3日目で目標金額を達成しました。応援してくださった皆さま、ありがとうございました!)
この記事が気に入ったらサポートをしてみませんか?