
Pythonで学ぶ実践データ分析

はじめに
このnoteではPythonを用いてデータ分析を学びます。
(※実践データ分析と書いてありますが、あくまでもこれからデータ分析をPythonで行いたい初心者のための入門記事です。分析手法をなるべく実践に近い形でというようなニュアンスです。)
対象読者はPythonの基本文法を学び終えた方で、普段Excelや統計ソフトを触っているが、今後Pythonでデータ分析を行いたく、問題解決のための意思決定をしたいといった方です。
(上記と目的が近い方は参考になるかもしれません。)
また、これからデータ分析をする上で注意して頂きたいのは、現場ではいきなりデータ分析に取り組みません。
データ分析の前に、お客様や社内であれば担当者とヒアリングを行います。その上で、『解決したい問題が明確に定義する』ことが何よりも重要です。
いきなりデータ分析に取りかかると、定義した問題に対して、データが一致しないため、出した結論とアクションに相違が生まれます。
本来、①解決したい問題を明確にする→②データ分析するという手順がある中で、このnoteでは②の『Pythonを使ってデータ分析をする手順や分析方法』に関して学びます。
①に関して学びたい方は、こちらなどをご参考ください。
データ分析の手順
データ分析の手順は、CRISP-DM(CRoss-Industry Standard Process for Data Mining)というデータ分析プロジェクトのプロセスモデルが参考になります。
・ビジネス課題の理解
・データの理解
・データの準備
・モデル作成
・評価
・展開・共有
詳細はこちらを参考。
CRISP-DMにおける『データの理解』に関して学びたい方はこちら
分析ストーリー
ではここからPythonを用いてデータ分析を実践していきましょう。
今回の問題設定として、個人で開発したスマホアプリのダウンロード数をさらに1000ダウンロード増やしたいと考えています。
開発者が2年間でかけた毎月の広告費に対するアプリのダウンロード数をプロットすると、以下のようなグラフが得られました。
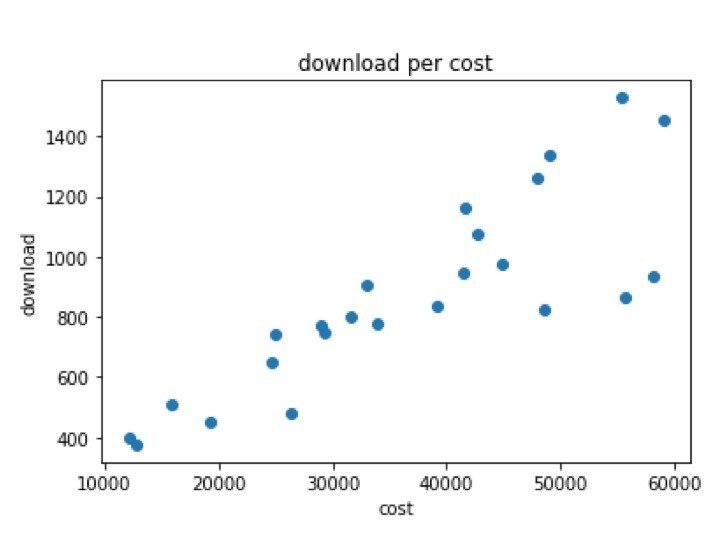
今回はいくらかければ、1000ダウンロード数増やすことが出来るのか分析していきましょう。
問題設定
アプリを開発したが、認知されていないため、ダウンロード数が少ない。
SNS広告を活用し、まずは1000ダウンロード数を達成したい。
条件(予算):広告予算に月に10万までかけることが出来る。
実際はもっと具体的に落とし込む方が良いですし、今回のケースは問題というほどの問題ではありませんが、今回はイメージしやすいよう簡易なものにしました。
回帰分析
分析手法に『単回帰分析』というのがあります。
単回帰分析は1つの目的変数(今回予測したいダウンロード数)を1つの説明変数(広告費)で予測する分析手法です。
Pythonにはscikit-learnという分析ツールがあるので、こちらを使って回帰分析を試していきましょう。
scikit-learnは下記でダウンロード可能です。
pip install sklearn必要なライブラリと学習データの準備
まず始めに今回利用する学習用のファイルを保存します。
下記のファイルを『download_cost.csv』と保存してください。
(保存場所はJupyter Notebookが動作する同じフォルダに配置してください。)
cost,download
29016,771
58171,933
49100,1339
55722,864
31631,800
33854,776
42734,1072
55382,1528
26392,481
48579,823
15929,509
29250,746
44825,973
24607,647
19217,452
41615,1164
39133,837
59073,1455
12115,398
48019,1264
41527,945
33018,903
12751,376
25027,742では次にpandasやscikit-learnなどをインポートします。
先ほど保存したdownload_cost.csvもここで読み込みます。
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
df = pd.read_csv("download_cost.csv")
x = df["cost"]
y = df["download"]上記のコードを実行し、エラーがなければ問題ありません。
ここで、FileNotFoundというエラーが出た場合、『download_cost.csv』が正しく読み込まれていない可能性があります。
データの分割
次にデータを分割します。
先ほど、変数xには広告費、変数yにはダウンロード数を代入しましたが、
次に学習用のデータとモデルの性能評価するためにテストデータに分割します。これをHold-Out法と呼びます。
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
学習(訓練)
それでは、学習データ(広告費用とダウンロード数)を用いて学習を行います。
# 単回帰分析するための準備
model = LinearRegression()
# 訓練
# ※この記事では詳細に説明しませんが、fitおよびpredictに渡せるデータの形状に直しています。
model.fit(x_train.values.reshape(-1,1) , y_train)予測
では、テストデータを元に予測してみましょう。
予測結果はpredという変数に格納しておき、後ほどモデルの性能評価に利用します。
# この記事では詳細に説明しませんが、fitおよびpredictに渡せるデータの形状に直しています。
pred = model.predict(x_test.values.reshape(-1,1))モデルの評価
次に、決定係数を用いてモデルの評価を行います。
scikit-learnではr2_scoreを用いることで、モデルの評価を行えます。
決定係数(R2)とは、推定された回帰式の当てはまりの良さ(度合い)を表し、0から1までの値を取り、1に近いほど、回帰式が実際のデータに当てはまっていることを意味します。
# 決定係数(R2)とは、推定された回帰式の当てはまりの良さ(度合い)を表し、
# 0から1までの値を取り、1に近いほど、回帰式が実際のデータに当てはまっていることを意味します。
r2_score(y_test.values.reshape(-1,1) , pred)
実際に、いくら費用をかければ1000ダウンロードされるのか予測してみよう!
では先ほど学習した予測モデルを用いて広告費を適当に入力してみましょう。
まず試しに、30000円を入力してみます。
import numpy as np
download_num = model.predict(np.array([30000]).reshape(-1,1))
print(download_num) # 757ダウンロード結果757ダウンロードでした。
もう少し費用をあげてみましょう。
次に43000円を入力してみます。
import numpy as np
download_num = model.predict(np.array([43000]).reshape(-1,1))
print(download_num)1008でした!
つまり、この予測モデルでは43000円をかけることで、目標の1000ダウンロードを達成出来る可能性があるということになります。
その後・・・
この開発者は予測モデルが出した43000円(予算内!)を広告費としてかけたところ、無事1000ダウンロード達成出来ました!
さらに様々な分析手法を学ぶなら
いかがだったでしょうか?
noteのタイトルは『実践』と書いておりますが、既に業務でやっている人からすると当たり前すぎる内容ですし、しかもストーリーとしてはシンプルすぎて本来今回みたようなうまくいくケースはありません。
ですが、Pythonを学び始めた初学者が興味を持ってもらい、イメージをしてもらいやすくするために分析ストーリー形式でnoteを書いてみました。
今回のnoteを読み、もっと分析したい!業務で活用したい!と感じた方は、
是非AI Academy Bootcampのデータサイエンティストコースお待ちしております!
データサイエンティストコースでは、
scikit-learnやKerasで機械学習を用いた分析手法とSQLを用いたデータ抽出スキルや機械学習アルゴリズムの基礎理論などを学びます。
受講後は、問題解決としてのデータ分析として、Pythonを用いたデータの前処理からモデルの評価やチューニングまでといった機械学習の一連の流れが一通り行える上、データサイエンティストとしての考え方、問題解決力が身に付きます。
(2ヶ月16時間の講義+ハードな課題+Slackを用いた質問し放題が出来て10 万円(税込)で受講可能です。)
動画受講やオンラインマンツーマン受講も出来ますので、是非検討してみてください!(毎月少人数4人程しか募集していないので申し込みはお早めに!)
AI Academy Bootcamp データサイエンティストコース
コード全体
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
df = pd.read_csv("download_cost.csv")
x = df["cost"]
y = df["download"]
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=1)
model = LinearRegression()
model.fit(x_train.values.reshape(-1,1) , y_train)
pred = model.predict(x_test.values.reshape(-1,1))
r2_score(y_test.values.reshape(-1,1) , pred)
import numpy as np
model.predict(np.array([30000]).reshape(-1,1))
model.predict(np.array([43000]).reshape(-1,1))最後に
このnoteが良かった!という方は是非いいね!&シェア頂けると嬉しいです!
フォローもお待ちしております!
このnote書いた人
この記事が気に入ったらサポートをしてみませんか?