
生成AIは今までのAIと何が違うのか?なぜいま盛り上がっているのか?

世界中で大きな盛り上がりを見せる「生成AI」。
生成AIを活用したChatGPTが史上最速で月間ユーザー数1億人を突破し、TIME誌の表紙を飾ったことは、その勢いを象徴する出来事だろう。
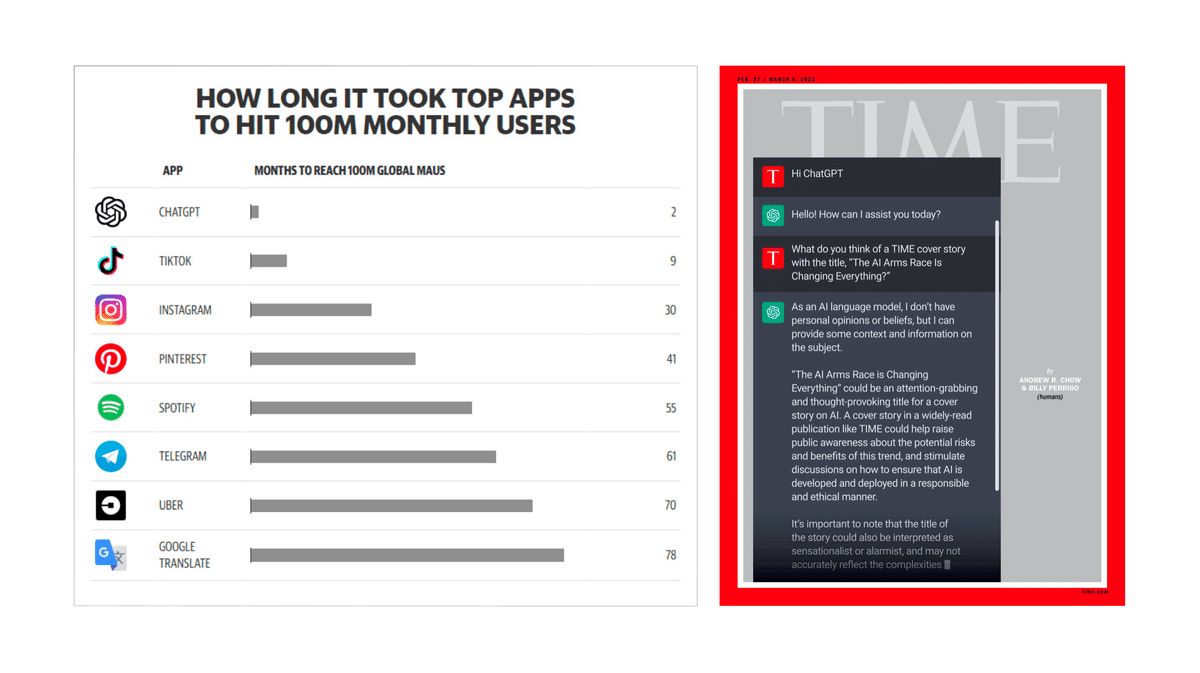
だが、ここで以下の2つの問いが浮かぶ。
生成AIは今までのAIと明確に何がちがうのか?
なぜ今このタイミングで生成AIがここまで盛り上がっているのだろうか?
この記事では上記2つの問いを海外のいくつかの記事を参考にしつつ解説していく。
生成AIと今までのAI技術との関係性
まず生成AI技術とこれまでのAI技術との関係性を概観しておこう。
広い意味でのAI技術として、データの特徴を学習してデータの予測や分類などの特定のタスクを行う機械学習が生まれ、その中でデータの特徴をマシン自体が特定するディープラーニング技術が発展した。
そして、生成AIはこのディープラーニング技術の発展の延長上にある技術だと言える。
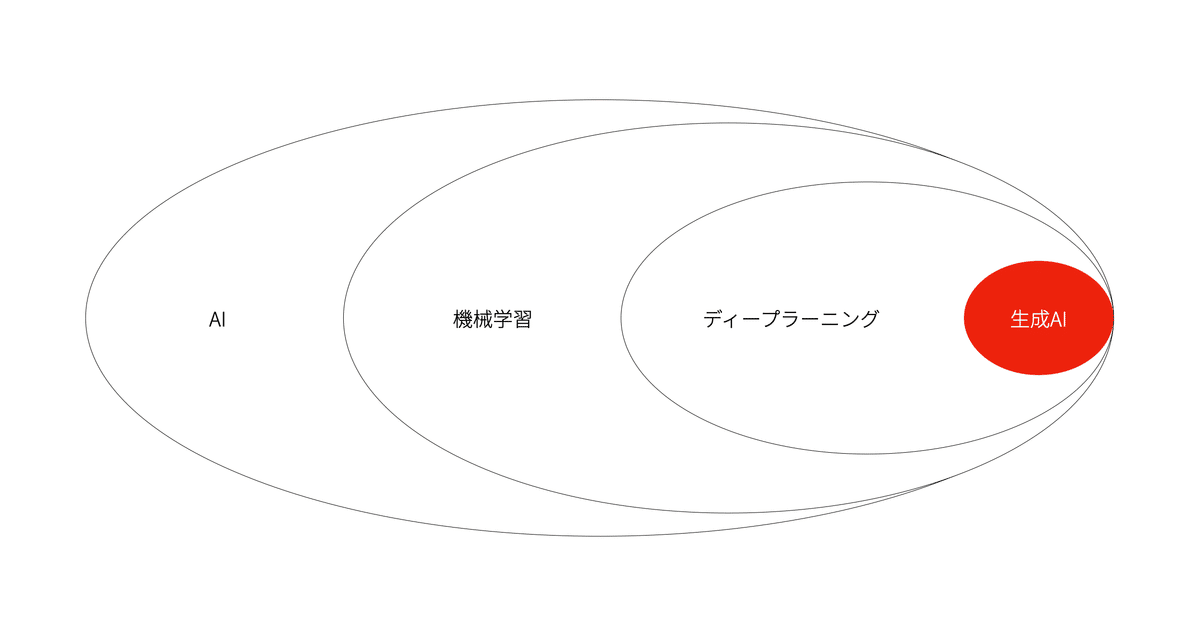
そして、「生成AI」という名称については対比的な意味で使われている側面もある。
2022年に生成AIがブームになるまで、ディープラーニングにおいて人間と同等以上の成果を出せる領域としては認識や識別がメインだった。
その時代のAIと明確に区別するために、AI自体で何かを作り出すという性質から「生成AI」という呼び名が使われている。
Generative AIに至るブレークスルーの概観
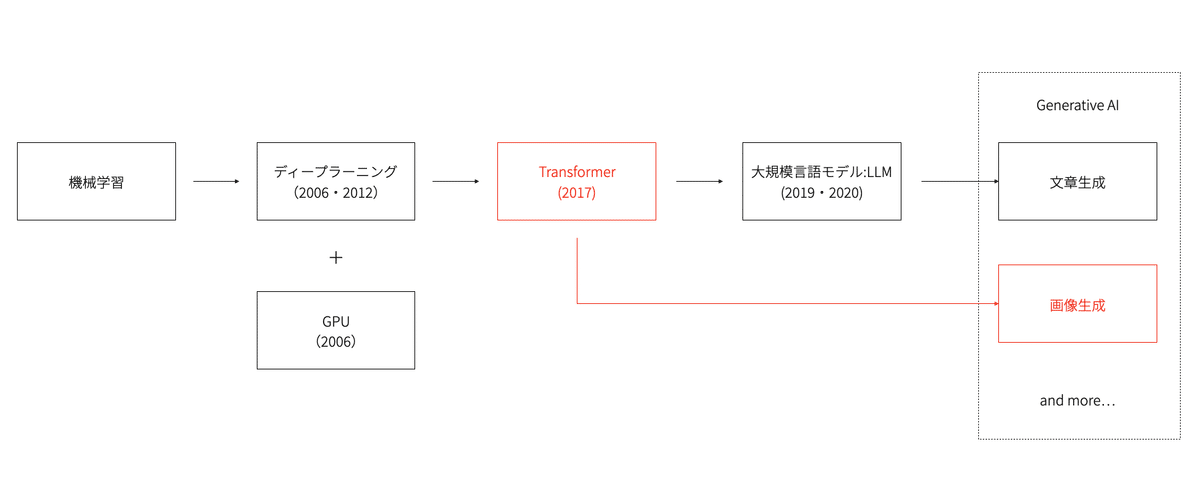
詳細に入る前に生成AIに至るブレークスルーを概観すると以下のようになる。
これから順を追って解説していこう。

機械学習における「三位一体」
まず前提として機械学習における重要な要素は以下の3つだ。これは後述する大規模言語モデルにおいて重要な「べき乗則」の3要素とも対応している。
入力されたデータから望ましい出力に導くための「モデル」
学習のための「データ」
演算を支えるための「計算機」

ディープラーニングの発展から生成AI発展に至るまでの道筋はこのAIにおける「三位一体」を前提に見ていくと分かりやすい。
ディープラーニング発展の歴史をおさらい
実は2000年代から存在していたディープラーニング
ディープラーニングの直接の起源は、ジェフリー・ヒントンが2006年に考案したスタックトオートエンコーダだと言われている。
それ以前もCNN(畳み込みニューラルネットワーク)は存在していたが、必要な演算能力が高いため実用的でなかった。
つまり「モデル」の誕生に対して、「計算機」のピースが明確に欠けていた。

NvidiaがGPUを汎用スーパーコンピューターとして利用可能に
それを変えたのが、2006年にNvidiaが発表したプログラミング言語の「CUDA」だ。これにより、GPUを汎用スーパーコンピュータとして利用できるようになった。

ラベル付き画像データベース「Imagenet」の登場
そうして「モデル」と「計算機」が揃った2006年のタイミングから3年後の2009年、スタンフォード大学のAI研究者らが、コンピュータビジョンアルゴリズムの学習に使用されるラベル付き画像の「データベース」であるImagenetを発表した。

ILSVRCにおけるディープラーニングの圧勝
そうして「モデル」「データ」「計算機」が揃いディープラーニングは円熟の時期を迎える。
2012年の「ILSVRC」(画像認識の精度を競うAIの競技会)で、初出場したジェフリー・ヒントン教授のチームが他を圧倒して優勝したのだ。
当時画像認識AIの精度は75%程度で1年に1%改善するのが精一杯だったところから他のAIに比べて10%以上も高い驚異の精度を叩き出し、ここから一気にディープラーニングブームが始まった。

ディープラーニングブームから生成AIに至るまでの大きな溝
当時のディープラーニングにおける大きな限界
しかし、当時のディープラーニングにも大きな限界があった。
画像認識においては人間を上回る精度を出せるようになったが、自然言語処理(NLP)、つまりマシンに人間の言葉を理解させ、動作させるには大きな壁があったのだ。
なぜなら画像認識においては順序は関係ない(画像の中の猫はどこにいても猫)が、言語処理においては順序が重要(「わたしがAIについて学ぶ」と「AIがわたしについて学ぶ」は異なる)からだ。
最近までの一般的な手法「RNN」「LSTM」
最近まで、データを時間的に処理し分析するために、リカレントニューラルネットワーク(RNN)や長期短期記憶(LSTM)のようなモデルを主に使ってた。
これらのモデルは、時系列データを扱えるという意味でこれまでのニューラルネットワークの手法に対して画期的であり、インターネット上の文章を人間が情報を付与するアノテーションが原則必要ないという意味でデータの問題もクリアしていた。だが、長い文章を扱うのは苦手で、SiriやAlexaのようなシンプルな音声アシスタントには向いていたが、それ以上のことをやろうとすると精度が全く足りないのが実態だった。
生成AIブレークスルー前夜の状況
こうして生成AIブレークスルー前夜の状況を整理すると、自然言語AIは、既に存在する「計算機」と「データ」を活用できる「新しいモデル」が足りない状態、つまり最期のピースだったのだ。

すべてを変えた「Transformer」の登場
そうした状況に風穴を空けるモデルが、Googleの言語翻訳研究チームから生まれる。
それが「Attention Is All You Need」という有名な論文で発表された「Transformer」だ。
これが生成AIにおける大きなブレークスルーになった。
なぜGoogleの翻訳研究チームから生まれたかというと、彼らも翻訳という語順が重要な自然言語の問題に取り組んでいたからだ。
Googleの中から生まれた論文によってブレークスルーを迎えた生成AIを使ったChatGPTやBingAIなどが大きな脅威となってGoogleが社内に非常事態宣言を出すに至った状況を考えると何とも皮肉が効いている。

「Transformer」の仕組み
「Transformer」の仕組みをざっくりとだけ紹介すると、以下の2つが特徴になっているが、特に開発を行わない方は大筋の理解には影響しないので読み飛ばしてもらって結構だ。
Embedding(埋め込み):埋め込み(Embedding)とは入力されたトークン(≒単語)を自然言語処理ネットワークが扱いやすい低次元のベクトル空間へとマッピングするプロセスを指す。一言で言うと、言葉同士の意味の近さを数学的に表現しやすくするための処理である。
Multi Head Attention(マルチヘッドアテンション):Transformerモデルでは自己注意機構(Self Attention)といって、一文の中の各単語が他の単語とどれくらい関係しているかの関連度スコアを計算する。そしてMulti Head Attentionでは、その関連度スコアを1種類だけ計算するのではなく、複数の異なるスコアリングを並列で行い、それらのスコアを最終的に統合することで各単語間の関係性を浮き彫りにし、例えば「The cat was hungry because it didn’t eat anything.」という文章があった場合に、「it」という単語が「The cat」を指しているなど擬似的に文法を把握しているかのような処理を可能にする。
Feed Forward(フィードフォワード):フィードフォワードとはディープラーニングにおいて出力層から入力層に向かって誤差逆伝播で学習するのとは反対に、入力層からネットワークの各層を順に通過し、出力を行う処理を指す。大規模言語モデルの性能を示す際によく用いられるパラメーター数の大部分はこのフィードフォワードプロセスの重みの数に当たり、インプットされた文章から次の単語の確率を出力するという、大規模言語モデルの処理の根幹をなす部分だ。
「Transformer」のインパクト
「Transformer」は、以下の2つの点で多くの言語問題を解決するのにピッタリのモデルだった。
文章が長くなると精度が下がるRNNやLSTMと異なり、文章が長くなっても文脈を捉えたような処理が可能になった
計算数が単語数に比例してしまうRNNやLSTMと異なり、分散学習を効率的に行えるモデルなのでGPUでの処理と相性が良い
つまり1の特徴によって実用的な長さでの文章などの文字列の生成が可能になり、2の特徴によってGPUという計算機を用いることができるようになった。
これで「モデル」「データ」「計算機」の3つが揃ったのだ。
「翻訳」の再解釈
ここで面白い再解釈が起きる。
翻訳というのは日本語から英語など異なる言語間であるという必要もない。
日本語と日本語の間での翻訳でも良いのだ。
例えば、長い日本語のエッセイをいくつかの短い段落に要約する、であったり、プロダクトに関するレビューをそれが肯定的か否定的かを判断する、などだ。
OpenAIによるGPT2のリリース(2019)
こうした発想に基づき、OpenAIはTransformerを活用した大規模言語モデル「GPT2」を開発する。
ChatGPTにも用いられている「GPT」とは「Generative Pre-trained Transformer」の略で「生成に使える事前学習されたTransformer」という意味だ。
名前を見るとTransformerがいかに重要なピースかが分かる。
そしてGPT2は、それまでの基準からすると驚くほどリアルで人間のようなテキストをセンテンスレベルではなく段落レベルで生成可能になった。
しかし、テキストが長くなると破綻したり、プロンプトの柔軟性がなかったりとまだ課題も多かった。
GPT3への進化(2020)
真に生成AIのブレークスルーが起きたのはGPT2からGPT3に進化したタイミングだ。
GPT2のパラメータが約15億個だったのに対して、GPT3はその100倍で約1750億のパラメータ数になった。
そして、GPT3はGPT2よりはるかに優れており、人間が書いたものとほとんど見分けがつかないようなエッセイを丸ごと書くことができるようになった。
GPT3リリース時に「The Guardian」がGPT3によって執筆された記事を公開して大いに話題になったのは記憶に新しい。

このように、学習のデータセットサイズ 、計算資源、モデルのパラメータ数のそれぞれを上げていくと精度が上がる法則は「べき乗則(Scaling Raw)」と呼ばれており、GPT-3への進化はその最たる例である。ちなみに、このべき乗則もGPT-4で限界を迎えたと、OpenAI CEOのサム・アルトマン氏自身も語っている。今後は、MetaのLlama 2のように学習データサイズは増やしつつパラメーター数は押さえて早い推論が行えるようなモデルの小型化や、「Attention Free Transformer」のような従来のTransformerに代わる新しいモデルの開発がトレンドになっていくであろうことは補足しておく。
GPTの研究者の想定を超えた進化
モデルを大きくすることで、単にテキストを生成する能力が向上するだけではなく、リクエストを入力するだけでパラグラフを要約したり、文章を特定のスタイルに書き換えることができるようになった。これは正直、OpenAIの研究者たちも想像していなかったようだ。
そして、GPT3は単一目的の言語ツールを超えて、様々な用途に使えるツールになった。
従来は基本的にタスクごとにモデルの学習が必要だった。だが、GPTなどのTransformerを活用したAIモデルにおいては、モデルを固定してプロンプトの形で指示を変えるだけで様々なタスクに対応できる汎用モデルとなった。
再掲)Generative AIに至るブレークスルーの概観
こうしてディープラーニングの流れから生まれた「Transformer」によって全てが変わり、それを用いて生まれた大規模言語モデル「GPT」によって様々な文章生成ができるようになった。
しかし、いま生成AIと言ったときに指すのは文章だけではなく画像も含まれる。
次に画像生成に至る流れも見ていこう。

画像生成AI誕生の流れ
Transformerの言語領域以外への拡張
Transformerによって大規模言語モデルが生まれ、それによって文章生成が花開いていったが、画像生成はそれとは別のルートでTransformerを活用することで発展した。
画像にも使えるTransformer
翻訳とは抽象化すると、ある並びの記号の集合から別の並びへのマッピングだ。
つまり、言語と同じ方法でそのメディアを表現する方法を見つけ出せれば、
その言語間で翻訳を行うためにトランスフォーマーモデルを活用できる。
そして、それがまさに画像生成で起こったことだ。
画像を言語として扱い“Transform”する
ディープラーニングによって、基本的な線や形、パターンなどの語彙を基本構成要素として画像を捉えることがきるようになった。
つまり、ディープラーニングは画像の「言語」の表現を解明したと言える。
そして、画像が「言語」であるならば、Transformerによって「翻訳」が行える。
そうして、画像から重要な特徴を抽出し、それを座標空間にプロットし、その座標空間を移動することで画像を描くことが可能になったのだ。
つまり、AIにとって「画像を描くとは、座標空間内を移動すること」となった。

インターネット上に豊富にあるラベル付き画像
インターネットにはAlt Textという形でラベル付き画像が豊富にある。
それによって、OpenAIは画像とテキストの世界を行き来するための膨大なデータセットを構築することができ、モデル、データ、計算機が一体となり、画像をテキストに変換するDall-Eが誕生した。

拡散モデルによる発展
現在画像生成AIとして広く使われているStable Diffusionも、Text Encoderと呼ばれる部分でTransformerを用いている。そしてStable Diffusionは拡散モデルと呼ばれる手法をかけ合わせることによって、単にTransformerを用いる以上にクオリティーの高い画像を生み出すことに成功している。
拡散モデルとは簡単にいうと、テキストとペアになったある画像に対して徐々にノイズをかけていき、AIにそのノイズが乗った画像から元画像を予測させるという学習をしていくモデルを指す。これによりテキストを入力すると、粗いノイズ画像が生成され、それが徐々にきれいな画像に生成されているという挙動が実現できる。

DeepLearningとTransformerが生成AIのブレークスルーを生んだ
まとめると、画像を含めて様々なメディアの「言語」を学習するディープラーニングと、そうした言語間の「翻訳」を可能にしたTransformerの
2つが組み合わさることで今日のGenerative AIにおけるブレークスルーが生まれたのだ。

このブレークスルーは文章や画像に留まらない
そして、この生成AIのブレークスルーは文章や画像に留まらない。
言語のような構造で対象を表現する方法と、それを学習するためのデータセットがあれば、Transformerはルールを学習して、言語間の翻訳を行うことができる。
例えば、Github Copilotは英語と様々なプログラミング言語の間を「翻訳」し、GoogleのAlphafoldはDNAの言語とタンパク質配列の間の「翻訳」を行うことができる。
このように生成AIは無限の可能性を秘めているのだ。

参考リンク
本記事は主に以下の記事や動画を参考にさせてもらった。特に1番上の記事は相当な部分で参考にさせてもらった。
https://arstechnica.com/gadgets/2023/01/the-generative-ai-revolution-has-begun-how-did-we-get-here/
https://ig.ft.com/generative-ai/
https://time.com/6255952/ai-impact-chatgpt-microsoft-google/
https://www.mckinsey.com/featured-insights/mckinsey-explainers/what-is-generative-ai
https://www.youtube.com/watch?v=4Bdc55j80l8
https://dl.acm.org/doi/full/10.1145/3560815
まとめ
本来は翻訳のために作られたモデルを人間が「再解釈」と「転用」をすることで生成AIの領域は花開いていったのは非常に興味深い。
そして、翻訳の研究でそのきっかけを作ったGoogleが生成AIによるリスクに晒されているのはなんとも皮肉でドラマチックだと思わないだろうか。
生成AIは一過性のトレンドやビジネス的な意図で作られたトレンドではなく、デジタル世界の景色を一変させる技術だ。
ぜひ皆さんも色々な生成AIを触ってみて自社の事業にどう活かせるか考えてみるのをオススメします!
さいごに
生成AI,XR/メタバース、新規事業立ち上げ、サービス体験デザイン、サービスグロースなどの領域に関するメンタリングや勉強会などの依頼をお受けしています。ご興味ある方はTwitterやFacebookでお気軽にご連絡ください!
AIやXRなどの先端テック、プロダクト戦略などについてのトレンド解説や考察をTwitterで日々発信しています。 👉 https://twitter.com/kajikent