
よくわかるGoogleCloud#3_BigQuery remote functionsを使って分かち書きと感情分析する

皆様こんにちは。
本日もカホエンタープライズのnoteをご覧いただきありがとうございます!
4月からお届けしている、Google Cloudの活用方法をお伝えするシリーズ。本日は第3弾となります!
今回使用するツールは、Google BigQueryのremote frunctionsです。
こちらは、Cloud Functions、Cloud Runの関数をBigQueryから呼び出す機能となっております。
Natural Language APIを使用したCloud Functionsを作成し、分かち書きと感情分析を同時にBigQueryから実行してみます。
外部接続の作成
BigQueryとCloud Functionsとをつなぐために外部接続という機能を使います。以下に従って外部接続を作成します。

BigQueryのエクスプローラーのメニューから追加をクリックします。外部データソースへの接続を選択します。
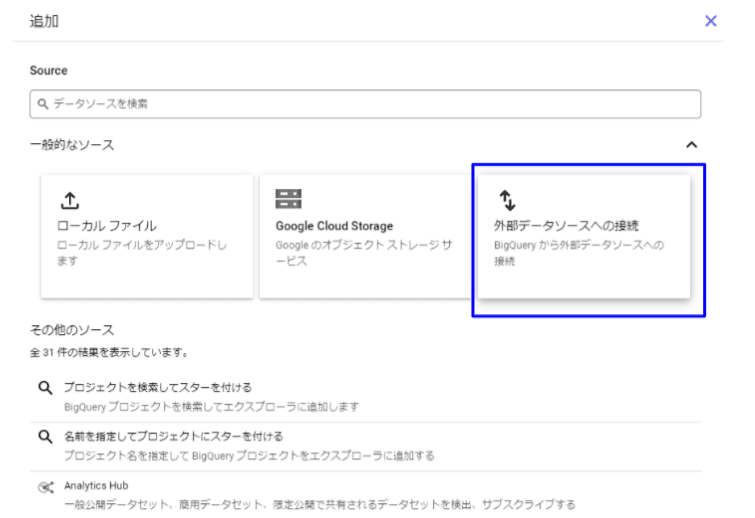
接続タイプを「Vertex AI リモートモデル、リモート関数、BigLake(Cloud リソース)」にし、接続IDに任意の名前をつけて接続を作成します。

外部接続が作成されました。

サービスアカウントに権限付与
外部接続で作成されたサービスアカウントにCloud Run起動元の権限を付与します。(Cloud Functions第1世代を使用する場合はCloud Functions起動元の権限を付与します。)

Natural Language APIの有効化
Natural Language APIが有効化されていない場合は、以下リンクのAPIを有効にするボタンをクリックしAPIを有効化しておきます。
https://cloud.google.com/natural-language/docs/setup?hl=ja#api

Cloud Functionsの作成
Cloud Functionsを作成します。
任意の関数名をつけ、トリガータイプはHTTPSの認証が必要、ランタイムでメモリ1GB、CPU1に設定して「次へ」をクリックします。

今回はインラインエディタでコードを記載してデプロイします。
ランタイムはPythonで、エントリポイントはnatural_langage_apiにします。

コードの内容は以下です。
requirements.txt
functions-framework==3.*
google-cloud-language==2.12.0python:main.py
import functions_framework
import json
from flask import Flask, request, jsonify
from google.cloud import language_v1
client = language_v1.LanguageServiceClient()
def get_analyze_results(message):
document = language_v1.Document(
content=message,
type=language_v1.Document.Type.PLAIN_TEXT)
syntax_response = client.analyze_syntax(
document=document,
)
separated_text = [s.text.content for s in syntax_response.tokens]
sentiment_response = client.analyze_sentiment(document=document)
return [{
"separated_text": separated_text,
"magnitude": sentiment_response.document_sentiment.magnitude,
"score": sentiment_response.document_sentiment.score
}]
@functions_framework.http
def natural_language_api(request):
try:
return_value = []
request_json = request.get_json(silent=True)
request_args = request.args
calls = request_json['calls']
for call in calls:
for text in call:
return_value.append(get_analyze_results(text))
return_json = json.dumps( { "replies" : return_value} )
print(return_json)
return return_json
except Exception as e:
return json.dumps( { "errorMessage": e } ), 400BigQueryにremote funcionsを作成する
以下のSQLを実行します。
<dataset>.<function_name>は任意の値を設定してください。
<connection_name>は作成したロケーション.外部接続の名称を設定します。(例:us.conn_functions)
<cloud_functions_url>は作成したcloud functionsのエンドポイントのURLを設定します。
sql:
CREATE OR REPLACE FUNCTION <dataset>.<function_name>(value STRING)
RETURNS JSON
REMOTE WITH CONNECTION `<connection_name>`
OPTIONS (
endpoint = '<cloud_functions_url>'
)
;実行
claude 3 Opusに以下の小売店舗のレビューサンプルを作ってもらいました。

以下のSQLを実行します。
(<~>の部分は適切に変換してください。)
sql:
SELECT
text,
res[0].score, -- cloud functionsのリターンに合わせる
res[0].magnitude, -- cloud functionsのリターンに合わせる
REPLACE(JSON_EXTRACT_SCALAR(text_element, '$'), '"', '') AS text_element
FROM (
SELECT
<テキスト列名>,
<dataset>.<remote_functions_name>(<テキスト列名>) AS res
FROM
<dataset>.<table_name>
)
,UNNEST(JSON_EXTRACT_ARRAY(res[0].separated_text)) AS text_element以下のような結果が返ってきます。

感情分析の値については以下のようです。
- score: -1.0(ネガティブ)~1.0(ポジティブ)のスコアで感情が表されます。これは、テキストの全体的な感情の傾向に相当します。
- magnitude: 指定したテキストの全体的な感情の強度(ポジティブとネガティブの両方)が 0.0~+inf の値で示されます。score と違って、magnitude は documentSentiment に対して正規化されていないため、テキスト内で感情(ポジティブとネガティブの両方)が表現されるたびにテキストの magnitude の値が増加します。そのため、テキスト ブロックが長いほど、値が高くなる傾向があります。
| 感情 | サンプル値 |
|:--|:--|
| 明らかにポジティブ | "score": 0.8, "magnitude": 3.0 |
| 明らかにネガティブ | "score": -0.6, "magnitude": 4.0 |
| ニュートラル | "score": 0.1, "magnitude": 0.0 |
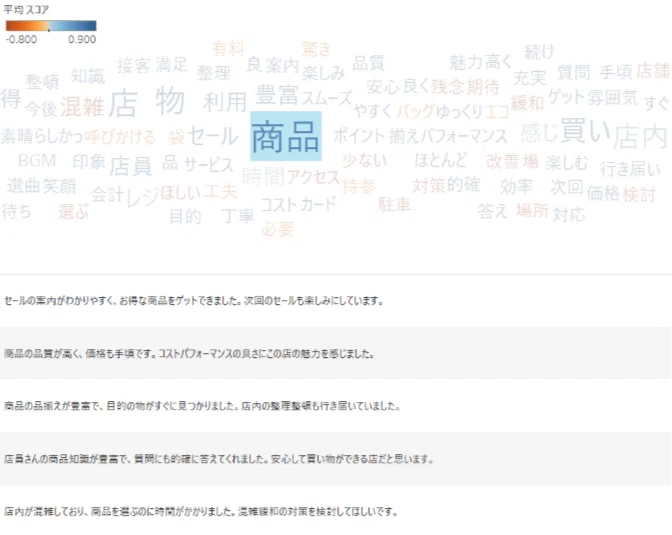
| 混合 | "score": 0.0, "magnitude": 4.0 |ここまで出来たら、TableauをはじめとするBIツールを使って、色々可視化してみてください!
ワードクラウドの形式が定番だと思いますが、その他にも様々な方法があると思います!
参考資料
[リモート関数を使用する](https://cloud.google.com/bigquery/docs/remote-functions?hl=ja#sample-functions-code)
[文字列の構文の分析](https://cloud.google.com/natural-language/docs/samples/language-syntax-text?hl=ja)
[感情分析のチュートリアル](https://cloud.google.com/natural-language/docs/sentiment-tutorial?hl=ja)
カホエンタープライズについて
当社はホームセンター「グッデイ」におけるDX化の経験をもとに、データ活用に関する実績及び様々な支援メニューを用意しております。
今回ご紹介したTableau関連の御支援はもちろんのこと、他にも様々な知見がございます。
データ活用・管理に関してお困り等ございましたら、是非お気軽にご相談ください!
⇩詳細はホームページをご覧ください!
事業内容:
① データ活用に関する御支援
・ Tableauライセンス提供
・ Tableau導入に関する支援/ダッシュボード画面構築支援
・ データ分析基盤(データウェアハウス)構築及び運用支援
・ Tableau操作トレーニング
・ Tableau内製化に向けた伴走支援
・ AI等最新クラウドサービスの活用支援
② クラウドサービス活用支援
・ Google Workspaceライセンス販売
・ Google Workspace導入支援
・ Google Workspace操作トレーニング
③ クラウド型分析サービス(KOX)導入支援
④ DX人材育成サービスの提供
<問い合わせ先>
株式会社カホエンタープライズ
担当者:湯野 礼之輔(ゆの れいのすけ)
Mail:sales@kaho-enterprise.co.jp
TEL:070-8814-5939
この記事が気に入ったらサポートをしてみませんか?