
PyTorchモデルをTorchServeのネイティブサポートでデプロイしてみた

こんにちは、エンジニアのすずきです。
以前の記事で、SageMaker Training JobsによるTabBERTモデルのFine-Tuningを行いました。
Fine-Tuning済モデルをS3にアップロードすることができたので、今回はSageMakerでモデルのデプロイをしてみました。
TorchServe
作成した機械学習モデルを推論システムとして使うためには以下の要素が必要となります。
学習済みの機械学習モデル
学習済みモデルに入力する特徴量作成の処理(特徴量生成、トークン化)
外部システムから学習済みモデルを利用するためのインタフェース(I/F)
これらの機能をまとめて提供するのがモデルサービングライブラリで、TensorFlowモデルであればTensorFlow Serving、PyTorchモデルであればTorchServeといったものがあります。
TorchServeを使うと、機械学習モデルのデプロイで課題となるような部分をいろいろ解決することができます。
予測性能とレイテンシのバランス(パフォーマンス) ⇒ 低レイテンシになるような最適化
前処理や後処理用のハンドラ作成(デプロイ容易性) ⇒ 画像分類やテキスト分類などの基本的なものであればデフォルトハンドラをもつ
本番運用におけるモデルの管理(セキュリティ、スケーラビリティ、信頼性) ⇒ 複数モデルのサービング、モデルバージョニング(A/Bテスト)、ログ/メトリクスの監視が可能
構成としては以下のようになり、外部システム向けの推論API(Inference API)、モデル管理API(Management API)、メトリクス収集API(Metrics API)をもちます。
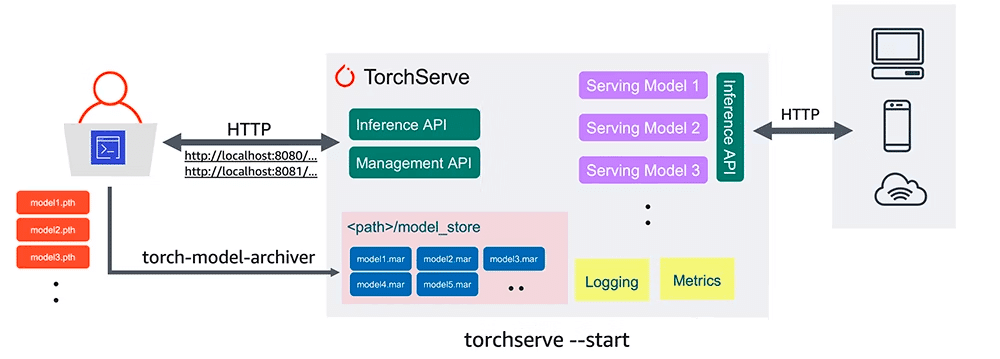
また、TorchServeによるデプロイ方法にはいろいろあり、EC2、EKS、SageMakerを使用することができます。
現在、TorchServeはSageMakerにおけるデフォルトの推論サーバとしてネイティブにサポートされているため、以前のような、SageMakerノートブックインスタンス上でのtorch-model-archiverのインストール、モデルのアーカイブ操作からのS3アップロード、DockerイメージのビルドとECRプッシュといった手間がなくなり、デプロイまでの操作がとても楽になっています。
※以下の記事に、TorchServeのネイティブサポート前の方法によるモデルデプロイの手順が書いてあるのですが、アーカイブ作成やDockerコンテナ作成の部分が手間に感じます。
SageMakerでデプロイした場合の構成は以下のようになります。
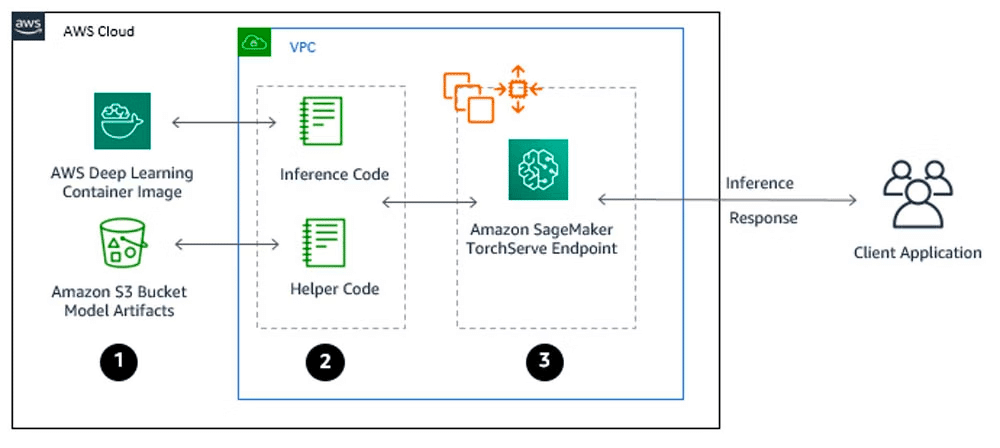
実装
以下のドキュメントやコードを元に、推論コードの実装からデプロイまで行います。
必要ファイルとディレクトリ構造
ノートブックインスタンスのルート直下に、ファイル操作やデプロイを行うためのノートブックdeploy_tabformer.ipynbとcodeディレクトリを配置します。
codeディレクトリには、推論用のコードinference.pyを配置します。
その他に、inference.pyでインポートする必要があるファイルやサードパーティライブラリのバージョン指定用のファイルrequirements.txtも配置します。
肝心のFine-Tuning済モデルfine_tuning_model.ptについては、ノートブックからではなくS3からmodel.tar.gzとして読み込みます。
.
├─ code
│ ├─ inference.py (推論)
│ ├─ common.py (モデル)
│ ├─ preprocessing.py (特徴量生成)
│ ├─ config.json (設定ファイル)
│ ├─ pytorch_model.bin (事前学習済モデル)
│ ├─ summary.encoder_fit.pkl (エンコーダー)
│ ├─ vocab_token2id.bin (辞書ファイル)
│ └─ requirements.txt (ライブラリバージョン指定)
└─ deploy_tabformer.ipynb (デプロイ用コード)今回、code内のファイル群については、deploy_tabformer.ipynb上でファイル操作をして配置します(common.py, inference.py, preprocessing.py, requirements.txtは手動で配置)。
pre_trained_model.tar.gzにすべてのファイルが含まれるのですが、不要なファイルもあるため、一旦modelディレクトリに展開して、必要なファイルのみcodeにコピーします。
ノートブックのストレージ確保のため、不要となったpre_trained_model.tar.gzやmodelは削除します。
import boto3
import tarfile
import os
import shutil
# 必要ファイルのダウンロード
s3 = boto3.resource('s3')
bucket = s3.Bucket('tabformer-opt')
bucket.download_file('<path>/model.tar.gz', 'pre_trained_model.tar.gz')
# ファイル展開
with tarfile.open(name='pre_trained_model.tar.gz', mode="r:gz") as mytar:
mytar.extractall('model')
# tar.gzの削除
os.remove('./pre_trained_model.tar.gz')
# 必要ファイルのコピー
shutil.copy('./model/vocab_token2id.bin', './code')
shutil.copy('./model/summary.3.2022-10-01_2022-11-30.encoder_fit.pkl', './code')
shutil.copy('./model/checkpoint-500/config.json', './code')
shutil.copy('./model/checkpoint-500/pytorch_model.bin', './code')
# modelディレクトリの削除
shutil.rmtree('./model')inference.pyの作成
inference.pyでは、以下の関数を記述します。
model_fn:モデルの読み込み
predict_fn:推論処理
input_fn:リクエストデータのデコード(predict_fnへのデータ受け渡し)
output_fn:レスポンスデータの生成(predict_fnからデータ受け取り)
import json
import sys
import logging
import pickle
import torch
from torch import nn
from os import path
from preprocessing import ActionHistoryPreprocessing
from common import CommonModel
logger = logging.getLogger(__name__)
logger.setLevel(logging.DEBUG)
logger.addHandler(logging.StreamHandler(sys.stdout))
MODEL_NAME = 'fine_tuning_model.pt'
JSON_CONTENT_TYPE = 'application/json'
def model_fn(model_dir):
model_path = '{}/{}'.format(model_dir, MODEL_NAME)
try:
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrained_model = path.join("/opt/ml/model/code/", f"pytorch_model.bin")
pretrained_config = path.join("/opt/ml/model/code/", f"config.json")
model = CommonModel(pretrained_config, pretrained_model)
model.to(device)
model.load_state_dict(torch.load(model_path))
model.eval()
return model
except Exception as e:
logger.exception(f"Exception in model fn {e}")
return None
def predict_fn(input_data, model):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
input_records = input_data['records']
token2id_file = path.join("/opt/ml/model/code/", f"vocab_token2id.bin")
encoder_fname = path.join("/opt/ml/model/code/", f"summary.encoder_fit.pkl")
encoder_fit = pickle.load(open(encoder_fname, "rb"))
preprocessed_data = ActionHistoryPreprocessing(
input_data=input_records,
token2id_file=token2id_file,
encoder_fit=encoder_fit)
model_input = torch.tensor([preprocessed_data.getitem()], dtype=torch.long)
model_output = model(model_input.to(device))
pred = torch.argmax(model_output, 1)
pred_list = pred.tolist()
result = {
"reaction": pred_list[0]
}
return result
def input_fn(serialized_input_data, content_type=JSON_CONTENT_TYPE):
if content_type == JSON_CONTENT_TYPE:
data = json.loads(serialized_input_data)
return data
else:
pass
def output_fn(prediction_output, accept=JSON_CONTENT_TYPE):
if accept == JSON_CONTENT_TYPE:
return json.dumps(prediction_output), accept
raise Exception('Requested unsupported ContentType in Accept: ' + accept)model_fnでは、モデルやconfig.jsonなどのファイルをコンテナのディレクトリから読み込みます。
例えば、モデルfine_tuning_model.ptについては、S3からmodel_dir内にコピーされ、ノートブックのcodeディレクトリに配置したコードは、デプロイ時にコンテナの/opt/ml/model/code/にコピーされます。
なお、特徴量を生成するActionHistoryPreprocessingやCommonModelなどのモジュールについては、以下のようにインポートします。
from preprocessing import ActionHistoryPreprocessing
from common import CommonModelモデルデプロイ
PyTorchModelオブジェクトを作成してmodel.deploy()を行うと、SageMakerのTorchServe上でコンテナが起動します。
まず、SageMakerのセッションやロールを準備し、PyTorchModelオブジェクトを作成します。
model_data:model.tar.gzのS3パス
name:SageMakerに登録するモデル名
role:SageMakerを利用するためのロール
source_dir:コンテナの/opt/ml/model/code/にコピーするノートブック内のディレクトリ名
entry_point:source_dir内でエントリーポイントとなるファイル
framework_version:コンテナのPyTorchバージョン
py_version:コンテナのPythonバージョン
framework_versionとpy_versionが指定されている場合、デプロイ時に適当なDockerイメージをSageMaker側で選択して実行してくれます。
例えば、framework_version=1.9.0, py_version=38を指定すると、763104351884.dkr.ecr.ap-northeast-1.amazonaws.com/pytorch-inference:1.9.0-gpu-py38が選択されます。
カスタムしたDockerイメージを使いたい場合は、image_uriでDockerイメージのURLを指定します。
また、framework_versionについては、学習時の環境と揃えないと、モデル読み込み時にエラーが発生する場合があります。
import boto3
import sagemaker
import pandas as pd
from sagemaker import get_execution_role
from sagemaker.utils import name_from_base
from sagemaker.pytorch.model import PyTorchModel
from sagemaker.predictor import Predictor
from sagemaker.serializers import JSONSerializer
from sagemaker.deserializers import JSONDeserializer
sess = sagemaker.Session()
bucket = sess.default_bucket()
role = sagemaker.get_execution_role()
region = boto3.Session().region_name
sm = boto3.Session().client(service_name='sagemaker', region_name=region)
class ReactionPrediction(Predictor):
def __init__(self, endpoint_name, sagemaker_session):
super().__init__(endpoint_name,
sagemaker_session=sagemaker_session,
serializer=JSONSerializer(),
deserializer=JSONDeserializer()
)
model = PyTorchModel(model_data='s3://tabformer-opt/<path>/model.tar.gz',
name='tabformer-opt',
role=role,
entry_point='inference.py',
source_dir='code',
framework_version='1.9.0',
py_version='py38',
predictor_cls=ReactionPrediction)model.deploy()でデプロイを行います。
instance_typeでインスタンスタイプを指定したり、endpoint_nameでエンドポイント名を指定することができます。
predictor = model.deploy(initial_instance_count=1,
instance_type='ml.g4dn.2xlarge',
endpoint_name='tabformer-opt',
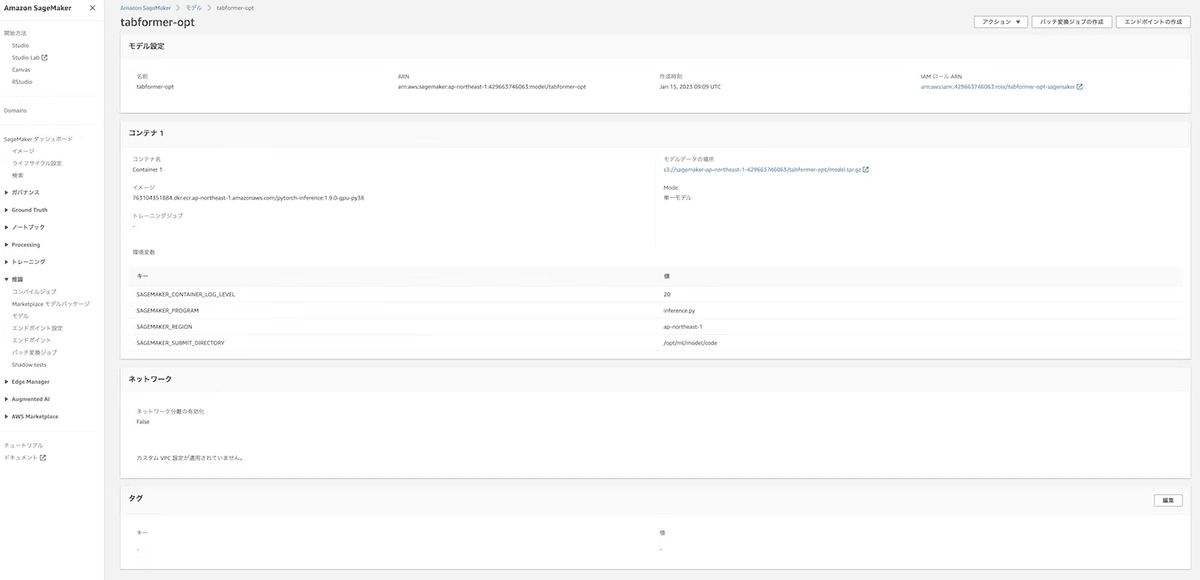
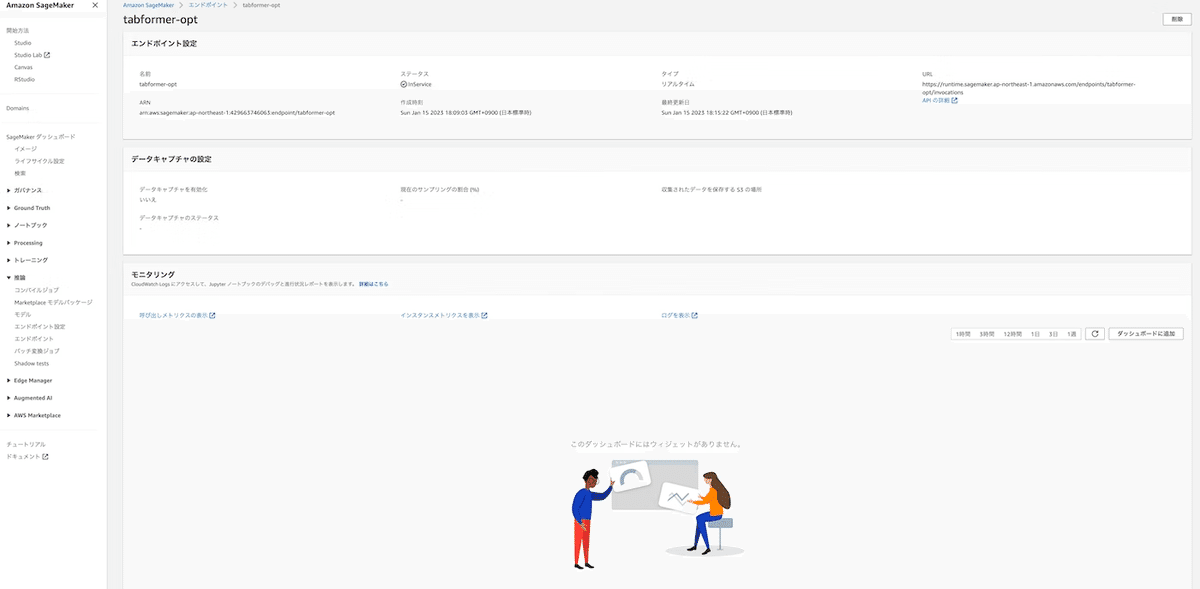
wait=False)デプロイに成功すると、SageMakerの推論 > モデルでモデル設定やコンテナの詳細、推論 > エンドポイントでエンドポイント設定などを確認することができます(ステータスもInServiceとなります)。
デプロイモデルが正常にレスポンスを返すかどうかを確認するために、リクエストデータ(2連続の時系列データ)を入力してみます。
test_data = {"records": [['2022-10-01 04:06:01', 1844060, 1643750, None, 'transition', None, None, None, 76, 'HP', 3, 'HP', 'smartphone', None, None, None, None, None, None, 'https://aaa.com/', 14.0], ['2022-10-01 08:05:31', 1845599, 1645078, None, 'transition', None, None, None, 76, 'HP', 3, 'HP', 'smartphone', None, None, None, None, None, None, 'https://bbb.com/', 19.0]]}
prediction = predictor.predict(test_data)正常にレスポンスが返りました。
{'reaction': 0}遭遇したエラーとその解決方法
エラーにハマりすぎて年末年始が消えたので、メモとして残します。
モデルの保存形式による読み込みエラー
ModelError: An error occurred (ModelError) when calling the InvokeEndpoint operation: Received server error (500) from primary with message "'NoneType' object is not callableRuntimeError: version_ <= kMaxSupportedFileFormatVersionINTERNAL ASSERT FAILED at "../caffe2/serialize/inline_container.cc":139, please report a bug to PyTorch. Attempted to read a PyTorch file with version 10, but the maximum supported version for reading is 6. Your PyTorch installation may be too old.学習時と推論時のtorchバージョンの差分によってモデルをうまくロードできないのかと思い、torchとtorchvisionのバージョンを両環境で揃えたのですが、解決できませんでした。
そこで、Fine-Tuning後の保存方法をtorch.jit.save()(TorchScript)からtorch.save()(モデル全体)に変えたところ別のエラーが発生しました。
/opt/conda/lib/python3.8/site-packages/sklearn/base.py:310: UserWarning: Trying to unpickle estimator LabelEncoder from version 1.1.3 when using version 0.24.2. This might lead to breaking code or invalid results. Use at your own risk.torch.save(model.state_dict(), ~)(モデルパラメータ)に変えたところ、解決しました。
サードパーティライブラリの未インポートによるエラー
ModuleNotFoundError: No module named 'transformers'common.pyでインポートしているtransformersがコンテナにインストールされていないことでエラーが発生しました。
codeにrequirements.txtを作成し、ライブラリ名とバージョンを指定することで、デプロイ時にインストールされるようにしました。
transformers==3.2.0参考資料
採用情報
バックエンドが得意な方を募集中です。
AWSやバックエンドの経験があれば、インフラ設計やパフォーマンスチューニングなどなんでもお任せします。
もしご興味があれば、採用情報ページの画面左下のボタンからチャット(かWeb通話)でお声がけいただけると幸いです。
