
動画生成AIの現状と仕組み

現在、文章から画像を生成するDALL-E2、Midjourney、Stable Diffusionなどの画像生成AIがブームになっています。
次の段階として、文章から動画を生成する動画生成AIが考えられますが、AIの開発スピードは予想以上で、早くもこうした動画生成AIが次々と誕生しています。
今回は、この動画生成AIの現状と仕組みについて解説します。
1.Make-A-Video
先月(2022年9月)29日、Meta(旧Facebook)が文章から動画を生成する動画生成AIのMake-A-Videoを発表しました。
動画生成AIを開発する場合の問題は、文章と画像のペアデータと比べて、文章と動画のペアデータが少ないため、画像生成AIほど大量のデータによる学習ができないことです。
Make-A-Videoは、学習済みの画像生成AIモデルを活用することにより、この問題を解決しています。
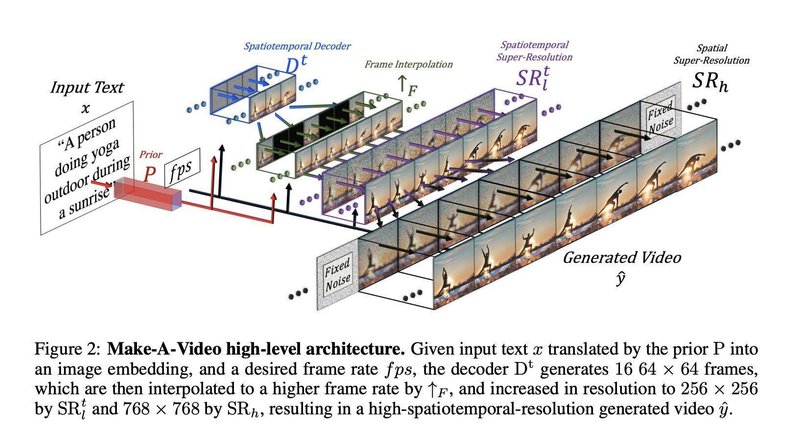
具体的には、先ず、文章と画像のペアデータで学習した画像分類AIのCLIPを使用して、入力された文章を画像特徴量に変換し、その画像特徴量をデコードして基本となる画像(フレーム)を生成します。
次に、動画のみのデータで学習したU-Netベースの拡散モデルで基本画像を時間方向、空間方向に拡張し、64×64ピクセルのフレームを16枚生成します。なお、U-Netは画像認識用の畳み込みニューラルネットワーク(CNN)の一種です。
そして、フレームレート(1秒間当たりのコマ数)を上げるために、生成した各フレームの間を埋める補間画像を複数枚生成して追加します。
最後に、超解像度モデルでフレームを768×768ピクセルまで拡大して、高解像度・高フレームレートの約4秒間の動画を生成します。
文章から動画を生成する以外に、入力した画像や動画から新しい動画を生成することもできます。

なお、これまでMetaは、大規模言語モデルのOPT-175Bや多言語翻訳AIのNLLB-200などAIモデルをオープンソースとすることを基本方針としてきましたが、今回はMake-A-VideoのAIモデルを公開していません。
ただし、今後、デモが公開される予定であり、利用希望者向けの登録フォームが公式サイトに用意されています。

A golden retriever eating ice cream on a beautiful tropical beach at sunset, high resolution
【論文】Make-A-Video: Text-to-Video Generation without Text-Video Data
2.Imagen Video
MetaがMake-A-Videoを発表してから約1週間後の今月(2022年10月)5日、Google Researchが動画生成AIのImagen Videoを発表しました。
Imagen Videoは、Googleが今年5月に発表した画像生成AIのImagenを動画生成に応用したものです。
Imagen Videoでは、時間方向と空間方向の2種類の超解像度拡散モデルの組合せで、最初に生成した低解像度のフレームを高解像度、高フレームレートの動画に仕上げていくカスケード拡散モデルという仕組みを採用しています。
具体的には、文章を入力すると、先ず自然言語処理AIモデルのT5でテキストを特徴量にエンコードします。
次に、このテキスト特徴量を基にして、U-Netベースの拡散モデルで24×40ピクセルのフレームを16枚生成します。
そして、時間的超解像度(TSR)モデルで各フレームの間を埋める補間画像を追加し、空間的超解像度(SSR)モデルでフレームを拡大するというのをそれぞれ3回ずつ行って、最終的に768×1,280ピクセルの128枚のフレームを使用した毎秒24フレームの約5.3秒間の動画を生成します。
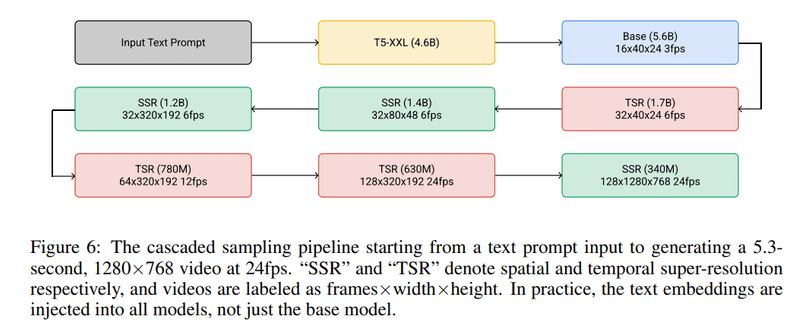
Imagen Videoでは、Stable DiffusionやDALL-E2では難しかったテキストのレンダリングが可能です。以下の図のように、植物の芽で「IMAGEN」と表示するなど、テキストを人間が読めるレベルの文字にレンダリングできます。
また、アーティストの画風を取り入れたり、3D構造を理解して、動画内に3Dモデルを登場させたりすることもできます。

Sprouts in the shape of text 'Imagen' coming out of a fairytale book.
なお、Googleは、画像生成AIのImagenの発表の時と同じように、社会的偏見やステレオタイプに基づくコンテンツが生成される懸念が軽減されるまでは、Imagen VideoのAIモデルとソースコードは公開しないと言っています。

Flying through an intense battle between pirate ships in a stormy ocean.
【論文】Imagen Video: High Definition Video Generation with Diffusion Models
3.Phenaki
Imagen Video発表と同日(2022年10月5日)に、Google Researchはもう一つの動画生成AIであるPhenakiを発表しました。
Phenakiは、Make-A-VideoやImagen Videoより長いストーリー性のある動画を生成できることが特徴です。
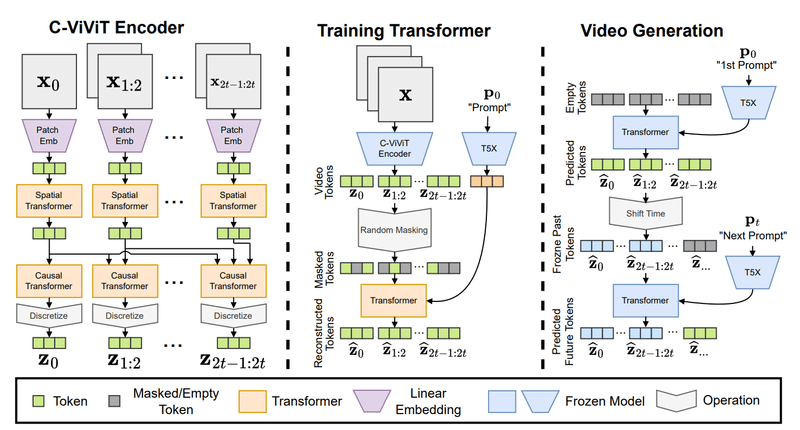
Phenakiは、動画をトークン(離散的特徴量)に圧縮するC-ViViTと呼ばれるエンコーダー・デコーダーモデルと、テキスト特徴量を動画トークンに変換する自己回帰的Transformerモデルの2つの主要モデルからできています。また、プロンプト(入力された文章)をテキスト特徴量に圧縮するために、学習済み言語モデルのT5X(T5の改訂版)が使用されています。
具体的には、先ず、C-ViViTエンコーダーで、動画を構成する連続したフレームの差分データを空間的Transformerと因果的Transformerで処理して、動画トークンを生成します。
次に、ランダムにマスキングされた動画トークンに、プロンプトをT5Xで変換したテキスト特徴量の条件を加えて、動画トークンを再構成するようにTransformerを訓練します。
そして、訓練したTransformerでプロンプトの条件に合った動画トークンを予測し、その動画トークンをサンプリングして最初の動画を生成します。
その後、最初の動画の最後のフレームをC-ViViTエンコーダーでトークンに変換し、同じように訓練したTransformerで次のプロンプトの条件に合った動画トークンを予測して、次の動画を生成します。
この作業を繰り返して、次々とプロンプトに合った動画を生成していくことにより、自然に繋がった長い動画を生成することができます。
Phenakiの公式サイトでは、ストーリー性のある連続したプロンプトから生成した約2分間の長さの動画サンプルも紹介しています。
さらに、30秒間の長さの動画を22秒間で生成することもできるということであり、将来的に、この技術によってリアルタイムで動画を生成し続けることも可能になりそうです。
なお、Phenakiも論文と動画サンプルの公開だけで、AIモデルは公開していません。

A photorealistic teddy bear is swimming in the ocean at San Francisco
The teddy bear goes under water
The teddy bear keeps swimming under the water with colorful fishes
A panda bear is swimming under water
【論文】Phenaki: Variable Length Video Generation From Open Domain Textual Description
4.CogVideo
Make-A-VideoやImagen Videoなどより早く、今年5月29日には、中国の清華大学と北京智源人工智能研究院(BAAI)が動画生成AIのCogVideoを発表しています。
なお、BAAIは、2018年に北京市が中心となり、北京大学、精華大学、中国科学院、Baidu、ByteDanceなどの大学、研究機関及び民間企業の人材を集めて設立された人工知能専門の研究センターで、2021年6月には、1兆7,500億のパラメーターを持つ巨大言語モデルの悟道2.0を発表しています。
CogVideoは540万組の文章と動画のペアデータで学習した94億のパラメーターを持つTransformerベースの動画生成AIです。
また、CogVideoは、画像生成AIのCogView2の事前学習で得られた知識を継承しているのが特徴です。
以下の映像サンプルのように480×480ピクセルの32枚のフレームで構成された毎秒8フレームの4秒間の動画が生成されます。

a woman on the lawn play Tai Chi
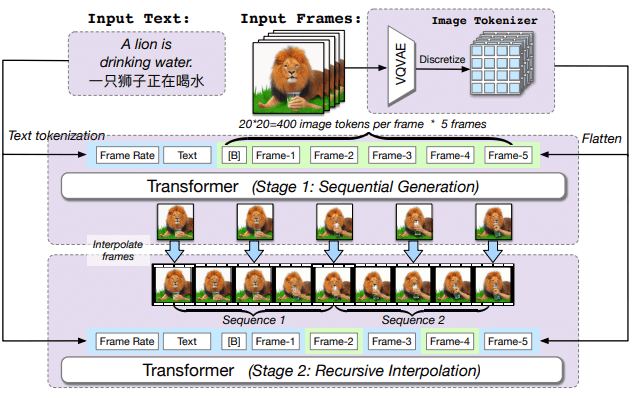
CogVideoでは、テキストと映像の時間的な対応関係を合わせるために、マルチフレームレートによる階層的な学習方法を取り入れており、逐次生成ステージと再帰的補間ステージという2つの学習ステージで構成されています。
学習の際には、先ずVQVAE(ベクトル量子化変分オートエンコーダー)で動画の各フレームを画像トークンに変換します。学習用のサンプル動画は、5枚の画像トークンで構成されます。
逐次生成ステージでは、フレームレートと入力テキストを条件として、5枚のキーフレームが順番に生成され、再帰的補間ステージでは、生成されたキーフレームを双方向のAttention領域として再入力し、補間フレームを生成して追加します。
こうして、入力したテキストと生成されたフレームができるだけ一致するように学習が行われます。
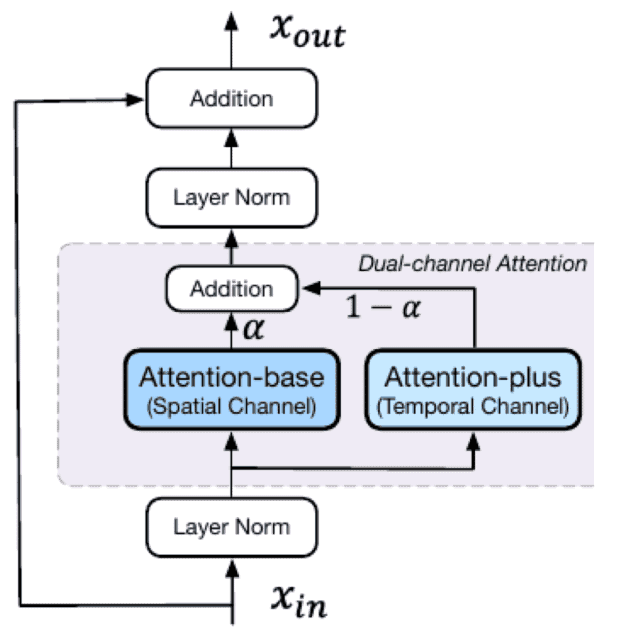
また、CogVideoでは、文書と画像のペアデータを追加学習する代わりに、事前学習済みの画像生成モデルを活用します。
具体的には、デュアルチャンネルAttention機構という手法を採用し、事前学習したCogView2の各Transformer層ごとに空間的Attentionチャンネルと時間的Attentionチャンネルを追加します。
これによりCogView2の既存のパラメーターは学習時にすべて固定され、新たに追加されたAttentionプラス層のパラメーターのみが学習可能となります。
CogVideoはオープンソースモデルで、Make-A-Video、Imagen Video、Phenakiと異なり、GitHubで AIモデルのコードを公開しています。
また、Hugging Face上にデモサイトを公開しており、プロンプトを自分で入力して動画生成を試してみることができます。筆者が試してみたところ、約3分半で1秒間の長さの動画が生成できましたが、画質が粗く感じました。

A panda is jumping on the sea.
【論文】CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers
5.まとめ
技術的には、画像生成AIの延長で短時間のビデオクリップしか生成できないCogVideo、Make-A-Video、Imagen Videoに対して、より長い時間の動画生成が可能なPhenakiが一歩進んでいるように見えます。
Phenakiの動画サンプルは、まだ画質が粗くぎこちないように見えますが、Imagen Videoの超解像度拡散モデルの技術と組み合わせれば、さらに高解像度、高フレームレートの動画を生成できるようになるでしょう。
今回のモデル発表は、Make-A-Videoの発表に対抗して、開発途中のモデルを慌てて出してきたようにも感じます。
しかし、CogVideo以外の動画生成AIが現在のところ、サービスやAIモデルを公開していないことが残念です。
現在の画像生成AIのブームは、Stable DiffusionなどがサービスやAIモデルを公開したことが重要なポイントであり、このことによって、多くのユーザーに利用され、新しい技術やサービスも次々と生み出されました。
また、文章生成AIのGPT-3の場合、最初に発表された文章生成サンプルは、驚くほど高品質な内容でしたが、実際にサービスを利用してみると、様々な欠点が見えてきましたので、動画生成AIも、サービスやAIモデルが公開されれば、現在は見えていない欠点が見えてくると思います。
現在も、AIを利用して作成したビデオクリップがSNS上に沢山掲載されていますが、これらは、テキストから直接動画を生成する動画生成AIによって生成された動画ではありません。
その正体は、画像生成AIの出力画像をズームしたり、シフトさせたりした後、その画像を初期値としてまたAIによる画像生成を繰り返すことによって作成した動画です。
こうした動画を作成するプログラムとしては、deforum氏が開発したDeforum Stable Diffusionなどが有名です。
Stable Diffusion VR - MiDaS Test 6DoF
— ScottieFox (@ScottieFoxTTV) October 15, 2022
Real-time immersive latent space -using depth maps.
Experimenting with freedom of motion & depth.
Tools used:https://t.co/W5UARpxuuIhttps://t.co/UrbdGfMgTd https://t.co/DnWVFZusrT#aiart #vr #stablediffusionart #touchdesigner #deforum pic.twitter.com/5bAk6az0kn
Stable Diffusionを開発・発表したStability AIも動画生成AIを開発中であり、近いうちに動画生成AIのサービスやAIモデルが公開されることを期待しています。
今後、高解像度、高フレームレートの動画生成AIが開発されて、サウンドや音声を生成するAIと組み合わすことにより、将来的に、脚本を用意するだけで本格的なビデオや映画を作成することができるようになるかもしれません。
画像生成AIの出現は、多くのユーザーに受け入れられると同時に、画家や絵師の仕事を奪うのではないかと騒動になりましたが、実用的な動画生成AIが誕生したら、そのインパクトは画像生成AI以上になると思います。
画像生成AIのブームで始まった生成AIモデルの発展は、無限の可能性を秘めているように感じられます。
この記事が気に入ったらサポートをしてみませんか?