
GoogleのAI開発者「2年後くらいにAIでテレビドラマ全編を制作できるよ」-動画生成AIのPhenakiとImagen Videoを融合

Googleは今月(2022年11月)2日、ニューヨークでAIの開発成果などを発表するイベント「AI@」を開催しました。その中で、Googleが先月発表した2種類の動画生成AIを組み合わせて生成した以下の動画を公開しました。
Meet Imagen Video and Phenaki, two research approaches for text-to-video generation.
— Google AI (@GoogleAI) November 2, 2022
By combining diffusion & sequence learning techniques, we can generate videos that are super-res at the frame level and coherent in time. (4/5)https://t.co/O7gGzb9knWhttps://t.co/Uc0krTyTvk pic.twitter.com/Op4tonX2iw
これは、一連のテキストから長時間の動画を生成できるPhenakiと高解像度の動画を生成できるImagen Videoを融合したものです。
また、Phenakiの開発者は、現在の速度で技術が進歩していけば、2年後くらいにこのAI技術でテレビドラマ全編を制作できると述べています。
1.Imagen Video
先月(2022年10月)、Google Researchは、テキストから高解像度の動画を生成できる動画生成AIのImagen Videoを発表しました。Imagen Videoは、今年5月にGoogleが発表した画像生成AIのImagenを動画生成に応用したものです。
Imagen Videoでは、時間方向と空間方向の2種類の超解像度拡散モデルの組合せで、最初に生成した低解像度のフレームを高解像度、高フレームレートの動画に仕上げていくカスケード拡散モデルという仕組みを採用しています。
具体的には、文章を入力すると、先ず自然言語処理AIモデルのT5でテキストを特徴量にエンコードします。次に、このテキスト特徴量を基にして、U-Netベースの拡散モデルで24×40ピクセルのフレームを16枚生成します。
そして、時間的超解像度(TSR)モデルで各フレームの間を埋める補間画像を追加し、空間的超解像度(SSR)モデルでフレームを拡大するというのをそれぞれ3回ずつ行って、最終的に768×1,280ピクセルの128枚のフレームを使用した毎秒24フレームの約5.3秒間の動画を生成します。
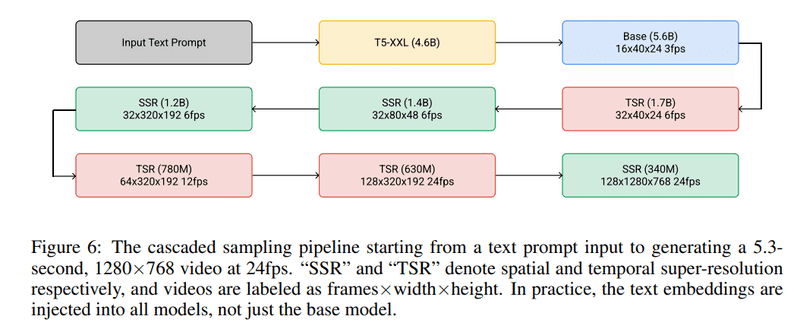
Imagen Videoでは、Stable DiffusionやDALL-E2では難しかったテキストのレンダリングが可能です。以下の図のように、植物の芽で「IMAGEN」と表示するなど、テキストを人間が読めるレベルの文字にレンダリングできます。

Sprouts in the shape of text 'Imagen' coming out of a fairytale book.
本から生えてくる植物の芽で「IMAGEN」と表示できます。
また、アーティストの画風を取り入れたり、3D構造を理解して、動画内に3Dモデルを登場させたりすることもできます。
なお、Googleは、社会的偏見が含まれるコンテンツなどが生成される懸念が残っているという理由で、Imagen VideoのAIモデルやソースコードは公開していません。

Flying through an intense battle between pirate ships in a stormy ocean.
【論文】Imagen Video: High Definition Video Generation with Diffusion Models
2.Phenaki
Imagen Videoと同時に、Google Researchはもう一つの動画生成AIであるPhenakiを発表しています。Phenakiは、Imagen VideoやMetaの開発したMake-A-Videoより長編のストーリー性のある動画を生成できることが特徴です。
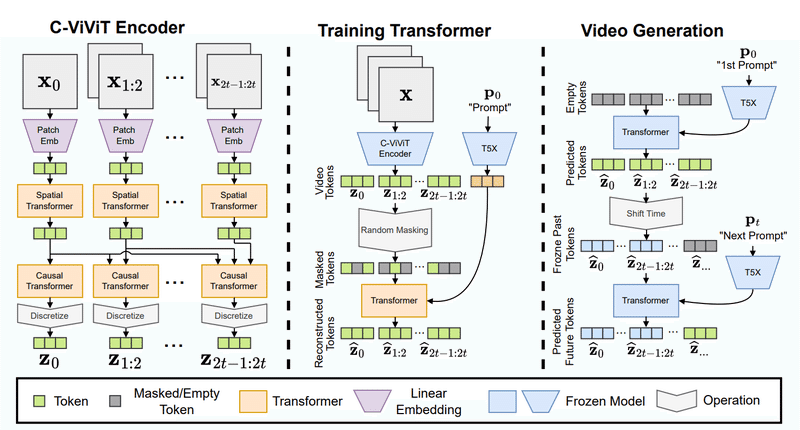
Phenakiは、動画をトークン(離散的特徴量)に圧縮するC-ViViTと呼ばれるエンコーダー・デコーダーモデルと、テキスト特徴量を動画トークンに変換する自己回帰的Transformerモデルの2つの主要モデルからできています。また、プロンプト(入力された文章)をテキスト特徴量に圧縮するために、学習済み言語モデルのT5X(T5の改訂版)が使用されています。
具体的には、先ず、C-ViViTエンコーダーで、動画を構成する連続したフレームの差分データを空間的Transformerと因果的Transformerで処理して、動画トークンを生成します。
次に、ランダムにマスキングされた動画トークンに、プロンプトをT5Xで変換したテキスト特徴量を加えて、動画トークンを再構成するようにTransformerを訓練します。
そして、訓練したTransformerでプロンプトの条件に合った動画トークンを予測し、その動画トークンをサンプリングして最初の動画を生成します。
その後、最初の動画の最後のフレームをC-ViViTエンコーダーでトークンに変換し、同じように訓練したTransformerで次のプロンプトの条件に合った動画トークンを予測して、次の動画を生成します。
この作業を繰り返して、次々とプロンプトに合った動画を生成していくことにより、自然な繋がりの長い動画を生成することができます。
Phenakiの公式サイトでは、ストーリー性のある連続したプロンプトから生成した約2分間の長さの動画サンプルも紹介しています。
なお、Phenakiも論文と動画サンプルの公開だけで、AIモデルやソースコードは公開していません。

A photorealistic teddy bear is swimming in the ocean at San Francisco.
The teddy bear goes under water.
The teddy bear keeps swimming under the water with colorful fishes.
A panda bear is swimming under water.
【論文】Phenaki: Variable Length Video Generation From Open Domain Textual Description
3.PhenakiとImagen Videoの融合
Phenakiが最初に発表されたときにも、Imagen Videoとの融合の可能性が言及されていましたが、現在、これらの技術を組み合わせたAIモデルの開発が実際に行われており、その開発途中の成果が今回発表されました。
5秒程度のImagen Videoのサンプル動画より長く、Phenakiのサンプル動画より解像度が上がっています。
AI short film created with text-to-video. https://t.co/DNEsTga216https://t.co/7D5myWmYvS
— alonso martinez (@alonsorobots) November 2, 2022
At the rate of advance in this area of research, we are likely ~2 years out from seeing a major tv show fully created using similar techniques.
prompt in comments!#generativeart #AIart pic.twitter.com/dNVX14bC2N
My roomies got used to me bursting out laughing at the results from using #Phenaki + #ImagenVideo
— alonso martinez (@alonsorobots) November 2, 2022
prompt in comments!https://t.co/7D5myW5VtShttps://t.co/MKTU2x9oTU#generativeart #AIart pic.twitter.com/IOZMRJsLfj
具体的には、まずPhenakiによって、一連のプロンプトに基づいた長編で低解像度のビデオを生成します。
次にImagen VideoのモデルがPhenakiの出力したビデオとプロンプトを受け取り、TSRとSSRの2種類の超解像度モデルでフレームを拡大し、高解像度の動画を生成します。Imagen Videoは、超解像度モデルにもプロンプトのテキストを取り込めるため、プロンプトに合わせた高解像度動画を生成できます。
このように、2つの動画生成AIモデルを組み合わせて、双方の特性を生かすことにより、高解像度で長く安定した動画を生成することができます。
Phenakiを開発しているGoogleの主任 AI 研究者のアロンソ・マルチネス氏は、現在の速度で技術が進歩していけば、2年後くらいにこのAI技術でテレビドラマ全編を制作できると主張しています。
この記事が気に入ったらサポートをしてみませんか?