
トランプ画像で物体検知AI開発を学ぼう!|第2回:柔軟性の高いAIを作る

こんにちは!ヒューマノーム研究所・インターンの塩谷です。
この連載では、誰もが知っているトランプを題材に、物体検知AI(ものを見つけるAI)の構築の流れや実用的な知識などについて、実践を交えながらお伝えしています。
前回の記事では、約60%の精度でトランプのスート(ハートやスペードなどの記号)を判別するAIを作ることができました。今回は判定画像の背景やアングルなどに左右されない、より柔軟性の高いAIの作成を目指します。今回も、プログラミングなしで簡単に物体検知AIを構築できるHumanome Eyes を使って作成していきます。
前回の記事で、AI作成の手順について詳しく説明しております。今回の内容を一緒にやってみたいという方は、そちらを参考にしていただければと思います。
モデルの柔軟性とは?
前回の記事では、最終的に精度が十分なモデルを作成することができました。以下のような判定画像では、6/10枚のスートが正しく判定されています。(図1)

このように、背景やアングルなど判定画像の撮影環境が学習した画像と同じようなものであれば、十分な精度を出すことができます。
では、判定画像の撮影環境が学習データと異なる場合は、どれくらいの精度が出るでしょうか。背景に柄があったり、背景と同化していたりする画像を判定画像に用いて、精度を検証してみました。(図2)

このように、判定画像の撮影環境を変えると、精度が大きく低下することがわかります。
AIは柔軟な判断ができると言われているものの、先ほどの例のように人間の柔軟性には到底かないません。ここでいう柔軟性の高さとは、判定画像の撮り方や背景などの要素に、精度がどれくらい左右されないかということを指します。
今回は、より柔軟性を高めることを目的としてモデルを作っていきます。
学習データを増やして柔軟性の高いAIを作る
1. 方法
より柔軟性の高いモデルを作成するには、どのような学習データを用意すればよいでしょうか。今回は、先ほど図2の検証時に使用した元画像(図3)の判定精度によって、モデルの柔軟性を評価したいと思います。

図1の結果から、判定画像が学習した画像と同じような撮り方であれば、ある程度精度が出ることが示されています。
この結果から、図3の判定画像で良い精度を出すためには、学習データの撮影環境を判定画像と同じ、以下のような条件にすればよいのでは?と考えました。
トランプに影がかかる
トランプの背景に柄がある
トランプが背景に同化している
また、この判定画像は角度をつけて撮影されており、一部のトランプは重なっています。カメラの正面に配置するという条件だけではなく、以下の配置条件も加えて撮影しました。
斜めから撮影される配置
トランプが重なった配置
これらを踏まえ、用意した学習データは図4の通りです。

計12枚の画像(1画像内にはトランプが3枚写っているため計36枚のトランプ)を1セットとしました。写っているトランプのスートと数字に偏りがないよう、1セットの中には2から10までの数字×4種類のスートが1枚ずつ含まれます。学習回数100回、学習データ3セット分から学習を始め、評価結果に基づいて学習回数や学習データを増やしていくことで、精度を高めていきました。
2. 結果
学習データ、学習回数を変えるとどのように精度が変化したでしょうか。まず、学習データ3セット分(画像:36枚、トランプ:108枚)、学習回数100回の精度を見てみます。

図5に示したように、Precision、Recallはそれぞれ、約0.17と約0.45しかありません。まだTotal Lossの値が下がりそう(=学習回数が不十分)なので、学習回数を500回に増やして精度を見てみます。

Precisionが0.55、Recallが0.56と、それぞれ値が大きくなっている、つまり精度が良くなっています。(図6)
一方で、Total Lossはまだ減少を続けているので、今度は学習回数を600回に増やして精度を検証します。

Total Lossが減少しきって、横ばいになっています。一方で、Recall、Precisionともに値が大幅に下がってしまいました。(図7)
これは学習データが少ないのにもかかわらず、学習回数を増やしたため、過学習の状態になったと考えられます。
※ 過学習とは
学習で用いたデータに過剰に適合してしまい、未知のデータの予測精度が落ちてしまった状態。
過学習を起こしてしまったので、今度は学習データを9セット分(画像:108枚、トランプ:324枚)に増やし、学習回数600回で学習させてみます。
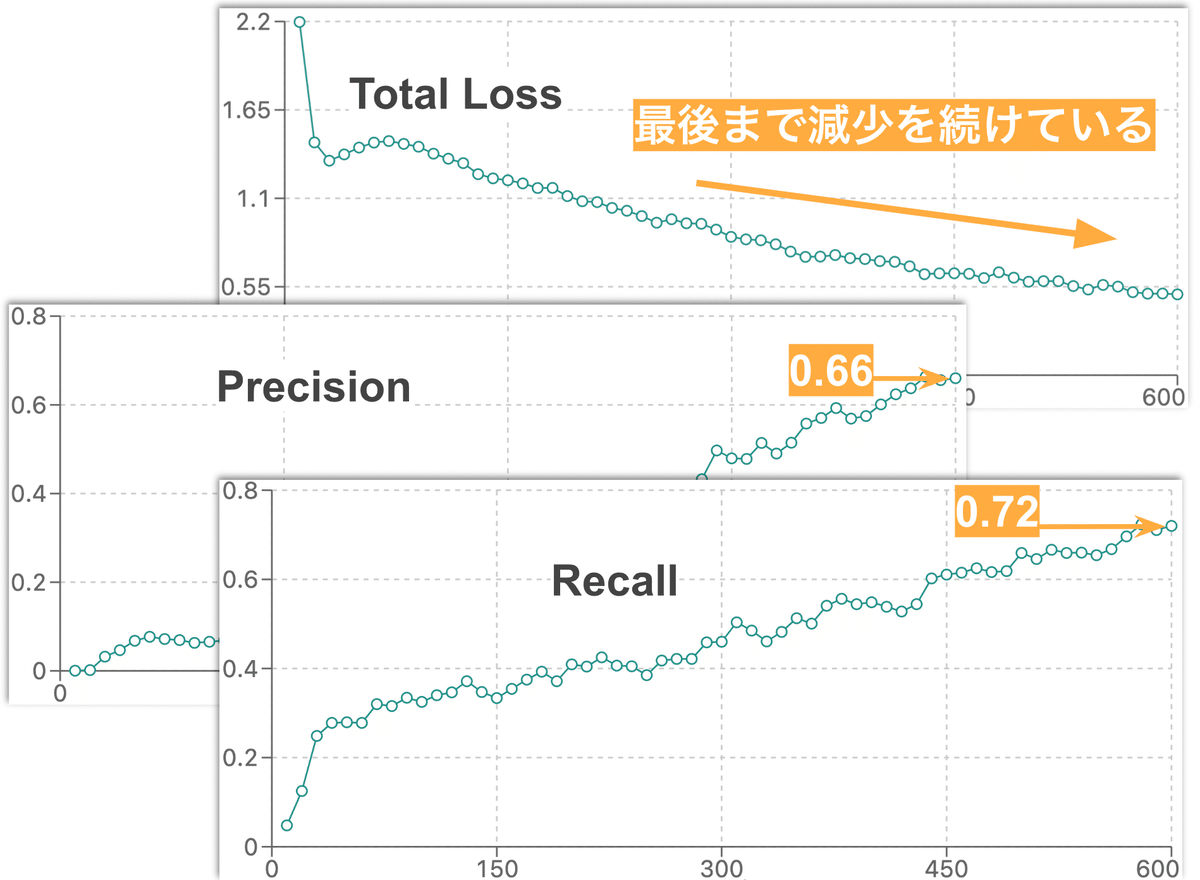
図8の通り、Precisionが約0.66、Recallが約0.72の精度を得ることができました。一方でTotal Lossが最後まで減少を続けている(=学習回数が足りない)ので、今度は学習回数を1000回に増やして精度を見てみます。

Total Lossのグラフを見ると一定の値に収束しているので、今度は十分な回数で学習できたようです。またPrecisionが0.74、Recallが0.79と、かなり精度の高いモデルを作ることができました。
いよいよ、この高い精度が得られたモデルを用いて、先ほどの画像を判定します。結果を図10に示します。

10枚中4枚のトランプのスートを判別することができました。(図10)
よく見てみると、白い紙の背景と同化しているトランプの判定がうまくいっていないことがわかります。人間であれば、色のついたスートの場所から大体のトランプの位置を推定できますが、AIにはできなかったということです。次の章でその理由を考察します。
3. 考察
白い背景と同化しているトランプが、正しく認識されなかったのはなぜなのでしょうか。まず考えられる原因は、白い背景と同化しているトランプは人間でも認識することが難しく、今よりも多く学習させなければ検知が難しいのではないか、ということです。
そこで、学習の過程でどれくらいの精度が出ているのかを確認します。以下に、1000回の学習を終えた時点で白い背景と同化した学習画像に対してはどのような判定がなされているのか示します。(図11)

正面(近く)、正面(遠く)、斜めから撮影した画像であれば高い精度で判定ができていますが、カードが重なっていると精度が落ちてしまっています。このことから、背景との同化はそれだけでは必ずしも精度が落ちる原因にはならないことが分かります。背景と同化していて、かつカードが重なっている場合のような混在パターンを、学習データとして与えていなかったため精度が落ちてしまったと考えられます。
先ほどの判定画像でも確かに、混在パターンとなっているカードの判定がうまくいっていないことが分かります。(図12)

このように、個々のパターンを学習していても、利用時にそのパターンが混在しうる場合は、その混在パターンも学習データに含める必要があるということが分かりました。
おわりに
今回は、判定画像の背景やアングルなどに左右されない、より柔軟性の高いAIの作成を目標にモデル作成を行いました。学習する画像を判定画像と同じような撮り方にすることで、精度の向上を試みましたが、パターンが混在する場合はやはり正しく判定することができませんでした。
このようにAIには人間の脳とは異なる性質、弱みがあり、それを理解してAIを作成・利用する必要があるということがわかりました。精度の高いAIを作成する際に、ぜひ参考にしてみてください。
ここまでお読みいただき、ありがとうございました!
※ 筆者紹介
塩谷 明日香(慶應義塾大学環境情報学部3年):VRを使ったスポーツトレーニングに興味があります。大学ではタッチフットボールに熱中しています。機械学習やプログラミングは一昨年から学び始めました。
---
私たちはワークショップのTA目線でのレポートや、機械学習ツールの使い方の紹介記事を執筆しています。今後も、AI構築の実際についてご紹介していきますので、お読みいただけると嬉しいです!
関連記事
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!
この記事が気に入ったらサポートをしてみませんか?