
ワクワクから始めるAI・データ解析(4.可視化編 その2)

この記事は初心者向けのノーコードAI構築ツール「Humanome CatData」(以下「CatData」)を使い、まずデータをさわってAIづくりをはじめよう、という連載の第4回となります。これまでの記事は以下のリンクからまとめてお読みいただけます。
前回は、データをグラフにすることで、情報の組み合わせを比較し、予想にあたりをつける手順についてご説明しました。
今回も引き続き「可視化」についてのお話になります。前回の補足的な位置づけとして、前処理と可視化を組み合わせて、データの詳細を見ていきます。
AI構築まで先を急がれる場合は、この記事は飛ばしていただいて構いません。しかしながら、今回の内容を知っておくことで、AI構築のときに利用するデータを構築する流れについて、より深く理解していただけるはずです。
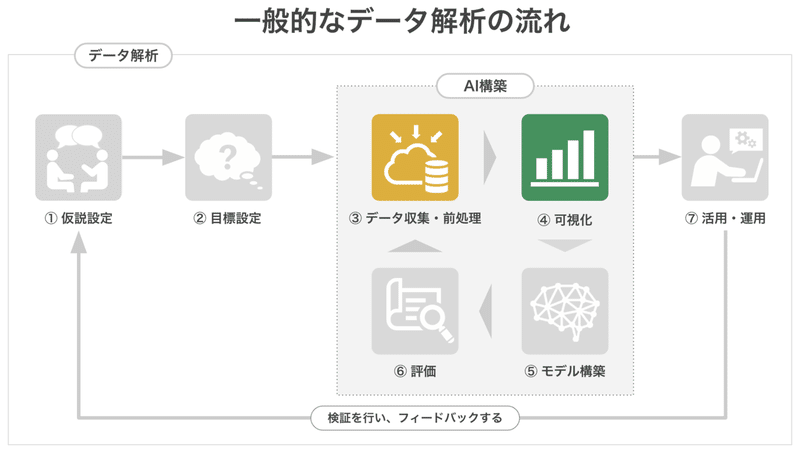
(1)「前処理」と「可視化」の実際の関係性
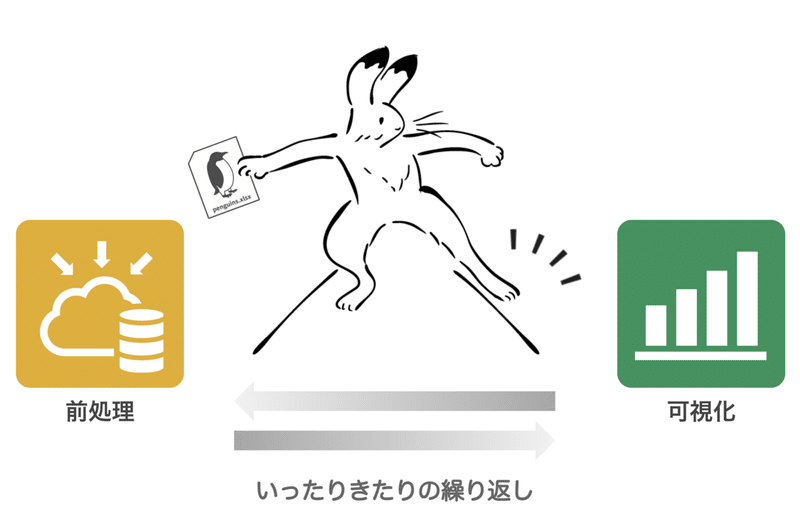
冒頭の「一般的なデータ解析の流れ図」の中では省略されていますが、実際にデータ解析を行う際は、前処理したデータを可視化し、可視化した結果を踏まえた条件で前処理を行い、それをもう一度可視化して・・・、というように両作業は地続きで進むことが多いです。こつこつと目標に向かって、前処理と可視化を繰り返すことで作られたきれいなデータがなくては、AIは構築できません。
とはいえ、最近はこれらの地道な作業を簡略化してくれる可視化ツールが発展してきています。CatDataも、プログラムを書かなくても、前処理と可視化がちょちょいとできたらいいのにな、という社内の希望を叶えるために開発をはじめたツールです。
(2) 可視化の下準備
さて、前処理で実施する作業は大きく分けて2つあります。ひとつは、第2回で説明した「欠損値をきれいにすること」、もうひとつは「AI構築に利用するデータを選択すること」です。
今回は後者の「データの選択」について、「②前処理編」で読み込ませたデータ「#1 penguins」を使って進めていきます。
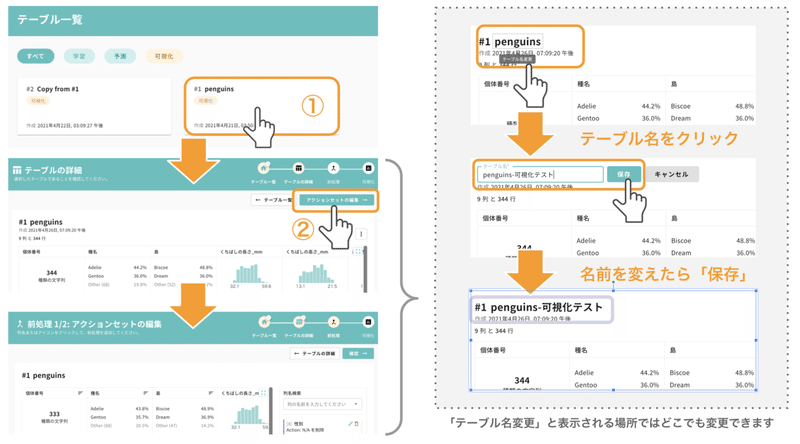
テーブル一覧にある「#1 penguins」を起点に、画面右上「アクションセットの編集」をクリックし、「アクションセットの編集」まで進んでください。
ここで、わかりやすくなるように「#1 penguins」というテーブル名を変更してみます。テーブル名の上にマウスカーソルを乗せると「テーブル名変更」と表示される場所では、上記の手順でお好きな名前に変更可能です。いろんな画面で変更できますので遊んでみてください。
(3) 実際に特定の値でデータを絞りこむ
さて、今回は「ペンギンの特定の誕生年によって、種の傾向は異なるのか?」について確認します。このような場合は、年をまたいで解析してもうまくいきません。そこで、ある年に生まれたペンギンだけを選択し切り出すことで、年ごとの大きさの可視化をしてみます。
それでは実際に、2009年に生まれたペンギンだけを選びます。
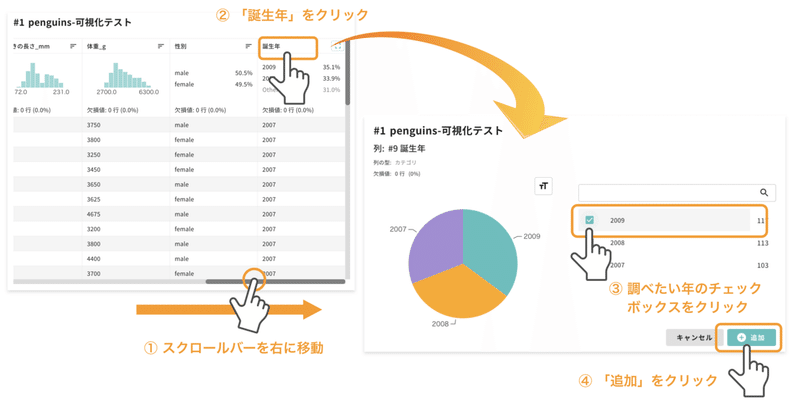
テーブルを右にスクロールし、誕生年の列を選びます。すると、新しいページに飛び、全ペンギンの誕生年の割合を示した円グラフが現れます。使われているのは2007, 2008, 2009 の3年間分のデータであることが分かります。
今回は、2009年生まれのペンギンだけに注目したいので「2009」にチェックを入れます。次に「追加(アクションを追加する、という意味です)」を押すと、元のデータ全体が表示された画面に戻ります。
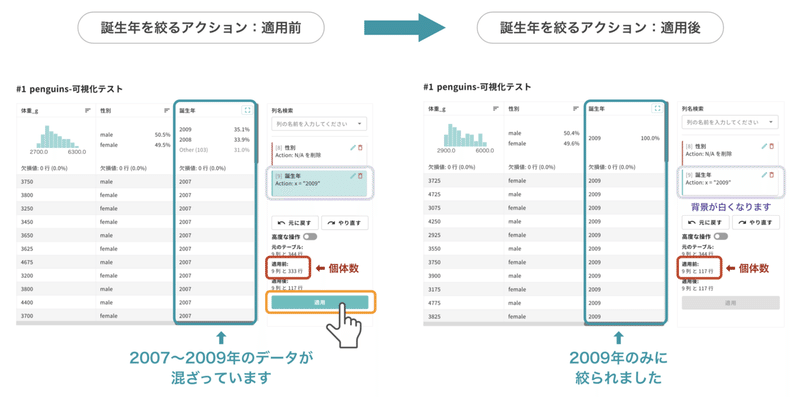
右側、欠損値を削除したときのアクションの下に「[9] 誕生年 Action : x=”2009”」というアクションが新しく現れ、「適用」ボタンが押せるようになっています。
複数のアクションが同時に表示されている場合、適用されるのは背景色があるアクションのみです。背景が白の「欠損値を削除するアクション」はこれまでの処理履歴として表示されており、今回適用されるアクションは「誕生年を絞るアクション」のみとなります。
では、「適用」ボタンをクリックして、作成したアクションをテーブルに適用します。
適用後のテーブルは、誕生年が2009年の個体だけに絞られました。また、適用ボタンの上にある詳細情報を見ると、もともと333個体だったデータが、117個体に絞られたことが確認できます。
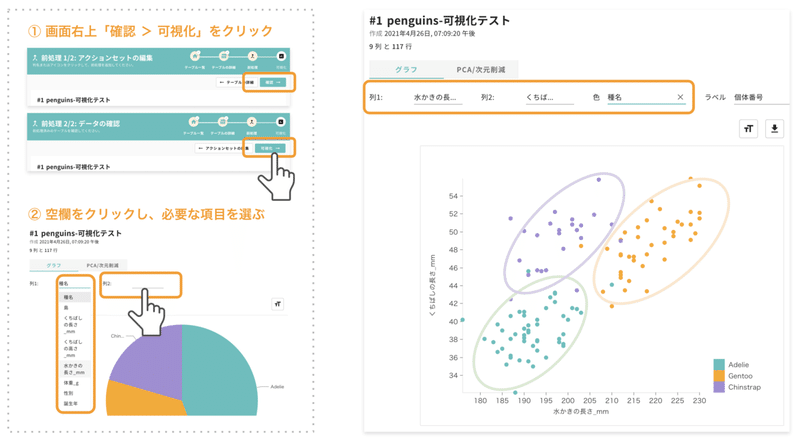
次に、先程の絞ったデータを図にして見てみましょう。上図の手順で、「くちばしの長さ」「水かきの長さ」「ペンギンの種類」の関係を示すグラフを作成します。2009年にデータを絞った後も、3種にはくちばしや水かきの長さにある程度の違いがみられるようです。
(4) 絞り込んだデータに特徴はあるのか?
さて、2009年で見られたデータの特徴は、他の年でも確認できるのでしょうか?
2007〜2008年のデータを可視化したデータと、前回「可視化例2:くちばしの長さと水かきの長さから種名を決めることはできるのか?」で作成したデータを並べて比較してみます。
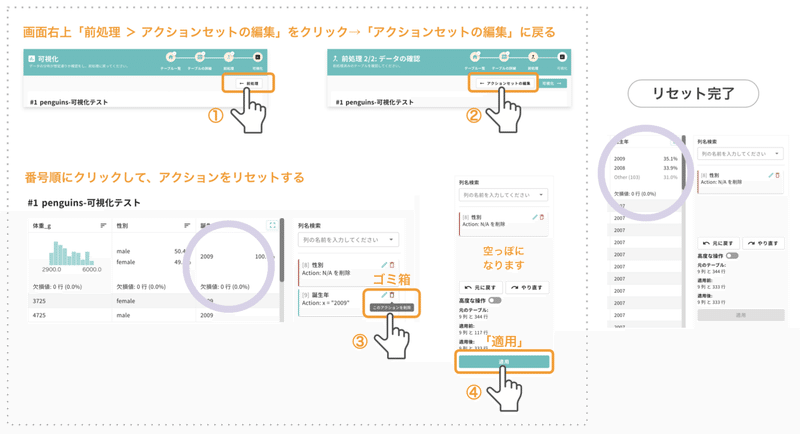
まず、他の年のデータを可視化するため、2009年だけに絞られている状態を最初の状態に戻します。先程設定したアクションを削除しましょう。
アクションセットの編集画面に戻り、作成したアクションにあるゴミ箱 > 右下の「適用」の順にクリックします(「適用」ボタンを押すまでは、絞られた状態のままです)。これで全ての年のデータが揃う最初の状態に戻りました。
リセットが完了したら、それぞれ調べたい年に絞り込んで可視化してください。得られた画像を並べて比較します。
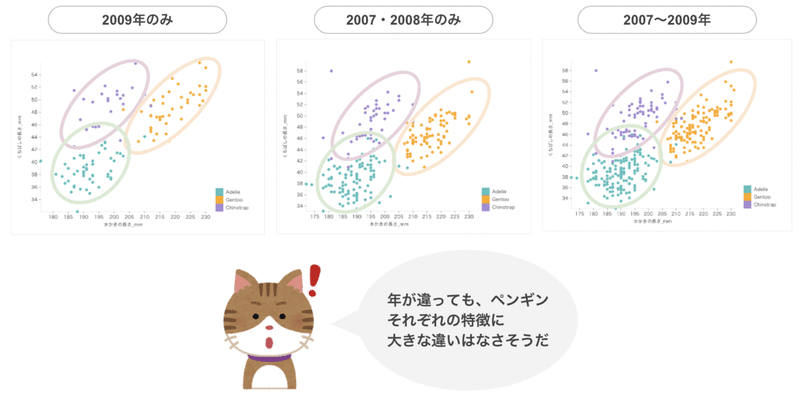
2009年は飛び抜けてくちばしの長さが長い個体がいなかったようで、若干グラフ縦軸の縮尺が異なっていますが、2009年のペンギンの種類ごとの特徴は例年と同様の傾向を持つようです。
これらのデータから、ペンギンの生まれ年は「くちばしの長さ」「水かきの長さ」にはそれほど大きな影響を及ぼさない、ということが確認できました。
このように一部のデータを選択し、切りだして傾向を比較することは、より正確に予測するAIをつくるために大切なプロセスとなります。ぜひお手持ちのデータを利用して、いろんな切り出し方を試してみてください。
次回のお知らせ
今回はAIの構築・評価に役立つ、前処理と可視化を組み合わせたデータ傾向の確認方法についてお話させていただきました。
次回はいよいよAI構築についてご紹介します。ぜひお読みいただけるとうれしいです。
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!
この記事が気に入ったらサポートをしてみませんか?