
元大学教員の高校教諭が総務省「情報II」教材を利用した機械学習の授業案を考えてみた|第3回:SVMを使った学習モデルの向上

こんにちは。ヒューマノーム研究所 次世代先端教育特命研究員の辻敏之と申します。普段は中学・高校の教員をしながら、ヒューマノーム研究所のお手伝いをさせていただいています。
この連載では総務省から発表された「高等学校における「情報II」のためのデータサイエンス・データ解析入門」を授業で活用するアイデアについて共有します。
無理なくデータ解析全体の流れを学ぶことに主眼を置き、授業内でプログラミングレスな初心者向けノーコードAI構築ツール Humanome CatData(以下 CatData)とHumanome Eyes(以下 Eyes)を利用することで、生徒がより楽しくデータサイエンスが学べます、という提案です。
本稿内の全ての図は、記事の最後にPDF形式で無料配布します。授業でスライドとして示すなどしてご活用下さい。
これまでの連載は以下のリンクよりお読み下さい。
第3回となる今回は、前回作成したSVMをつかった学習モデルの精度を向上させることを考えていきます。
1. 前回の振り返り・今回の目標
前回はスマホの故障歴を使用状態から予測するため、SVMを利用して学習モデルを構築しました。その結果、お世辞にも性能の良い予測AIとはいえないものが出来上がってしまいました。ここでは改めてデータを見直しつつ、より深くデータを理解すること、より良い学習モデルを構築することを目標とします。
使用するデータは総務省のテキスト公開サイトで配布されているSVM.csvの項目名を日本語にしたGoogle スプレッドシート上のデータです。
早速振り返ってみましょう。構築した学習モデルの目的は「過去の故障歴(past_falls)」を予測することでした。そのために3つの項目「利用者の性別(sex)」「利用者の年齢(age)」「リングの有無(ring)」を学習データとして用いました。その結果、質の低い学習モデルが構築されてしまいました。
授業ではまず、なぜ精度が低い、予測できないAIができてしまったのか考えてみます。
2. データを可視化し、観察する
第2回のまとめでも書きましたが、この結果は過去の故障率について上記の3つの項目では説明しきれなかった、または故障歴とあまり関係なかったことを示唆しています。直感的にも使用者の性別や年齢とスマホの故障歴が強く関係あるとは思えません。
それよりも使っているスマホの使用月数(months)やスマホの大きさ(幅 width、長さ height、厚み thick)などの方がよっぽど関係がありそうに思えます。
これらのデータを用いてより良い学習モデルを作ることを考えます。しかし、当てずっぽうに項目を選択し、学習→評価を繰り返して予測精度の高いモデルが出るまで頑張る、というやり方は明らかに効率が悪いです。きちんとデータを観察してどんな関係があるのかを理解した上で項目を選択すること、そしてよい学習モデルが生成されることが素晴らしいことと考えます。つまり、モデルの精度はデータの理解度の目安となるわけです。
データをきちんと観察するためには、何はなくとも「可視化」することが重要です。CatDataにも可視化するための準備がありますので、実際にデータをみてみたいと思います。
CatDataで可視化する方法は2通りあります。
1つはデータ読み込み(Google スプレッドシートのURLを指定するところ)のあとのダイアログで「可視化」を選択する方法。もう1つは第2回で行ったのと同じようにダイアログで「学習」を選択し、「前処理:前処理結果の確認」まで進んだところで右上にある「可視化」を押す方法です(図1)。

どちらの方法でも同じように可視化できますが、可視化用のテーブルを作ると、あとで改めて学習用のテーブルを作る必要があります。
無料プランをご利用の場合、保持できるテーブルが1つのため削除しなくてはならず煩雑になるので、学習用のテーブルの中で可視化してしまう後者の方法がオススメです。
可視化を選択すると図2のような画面に移動します。初期段階では左にある列1に「ID」が選択されていると思います。これを別の項目、例えば「使用月数(months)」に変更するとヒストグラムが更新されることがわかると思います。
項目を1つしか選ばないとヒストグラムしか選択できませんが、列1と列2それぞれで項目を選択すると、数値データとカテゴリデータの組み合わせの場合は蜂群図や積み上げヒストグラムが、数値データ同士を選ぶと散布図を選択することができます。

では、列1に「使用月数(months)」、列2に「過去の故障歴(past_falls)」を選択してみましょう。数値データとカテゴリデータになるので初期状態だと蜂群図が示されます(図3)。
2-1. 蜂群図
横軸は過去の故障歴です。「0」は故障したことがない、「1」は故障したことがあることを示しています。縦軸はスマホを何ヶ月つかっているかを示します。各点はデータがそこにあることを示していて、複数あると大きく示されます。

この蜂群図から読み解けることは何でしょうか?
ここからわかることは、「故障歴がない人はスマホを長い期間使っている傾向がある」ではないでしょうか。
図を見るとカテゴリ1、つまり故障歴がある場合、30ヶ月以上使用していることがないのがわかります。これは故障歴の有無を予測するために役に立ちそうなデータであると言えそうですね。このようにしていろいろな項目を見て、データの意味するところを読み取っていくのが「観察」です。
2-2. 散布図
では散布図も書いてみましょう。列1は「使用月数(months)」のまま、列2を「機種の幅(width)」にします。そうすると散布図が示され、全て緑色の点で表示されたのではないかと思います。これでは意味がないので、その下に出現した「色」という項目を「過去の故障歴(past_falls)」にすると故障歴ありはオレンジ色、なしは緑色と色分けすることができるようになります(図4)。
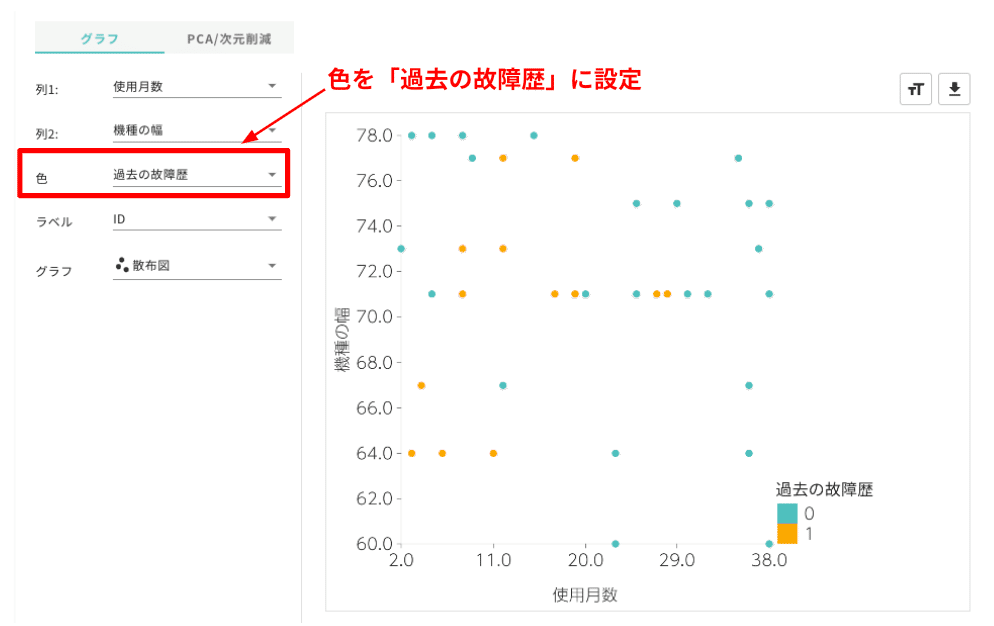
色々な数値データの組み合わせを選んで、より効果的なデータの組み合わせを探してみてください。ポイントはそのたびに、どうしてそういった関係になるのかちょっと考えてみることです。
たとえば図4では故障歴がある場合は、使用月数が短くて、幅が狭い傾向があるようにみえます。これは壊れたあとは落としにくい握りやすいスマホを選択していることが反映されているのかもしれません。
もちろん、上記の解釈はなんの根拠もない妄想です。こういった妄想を巡らせながらデータを観察することでその理解が深まっていくわけです。
3. 観察結果を踏まえて、学習モデルを再構築する
それでは上記の観察を踏まえた学習モデルを構築してみましょう。前回と同じように「過去の故障歴(past_falls)」を予測するために「使用月数(months)」、「機種の幅(width)」、「リングの有無(ring)」を使って学習させてみようと思います。
やり方は第2回で示したのと同じです。学習時に用いる項目にチェックを施すことで選択することができます。
実際に構築した学習モデルの混同行列を図5に示しました。テストデータの予測精度は0.6でした。これでもとても良いモデルだというわけではありませんが、第2回で構築したモデルのテストデータに対する精度は0.2だったので遥かに良くなっていることがわかります。

「もっともっと良くならないの? 予測したいのは0か1なんだから、ランダムでも0.5になるはずでは? 」と感じた方。まったくもっておっしゃるとおりです。もう少し良いモデルはできないのでしょうか。
先に答えからいうとできます。項目の数を増やすと、かなりの精度で予測できるモデルを構築することができます。
たとえば授業では組み合わせを知らせることなく、自由な組み合わせで学習モデルを構築できないか考えさせるのはどうでしょうか。より少ない項目でより予測精度の高いモデルを構築するコンテストも面白いと思います。
成果物として、なぜその項目を選んだのか、可視化したデータと共に根拠を示すレポートを作成することで、「データ解析はじめの一歩」を達成できると思います。
4. 本稿のまとめ
最後に、精度の高いモデルがうまく構築できた例を示します(図6, 7)。テストデータに対する予測精度は0.9です。またROCカーブを見てもかなり良いモデルであることがわかります。このモデルでは「使用月数(months)」、「1ヶ月以内に落とした回数(falls)」、「機種の幅(width)」、「機種の長さ(height)」、「機種の厚さ(thick)」を使っています。


今回は、可視化をつかってデータの観察をして、データの理解を深めることでよりよい学習モデルを構築することを目指しました。
単純に精度の高いモデルを求めるだけではなく、データを理解することがデータ解析の本質であることをほんの少しだけでも感じていただけたでしょうか。
なお、前回同様、今回使用した図はPDFにまとめました。以下のリンクよりダウンロードして下さい。授業でのスライド用途などにご利用いただけます。また、本連載は下記リンクからまとめて読むことができます。
次回、第4回では次のステップへと進み、ランダムフォレストを用いた常連さん予測を行います。ぜひお読み下さい!
※ 筆者紹介
辻敏之:機械学習やIoTデバイスを用いた先進的な教育活動に興味があります。好きなことは写真撮影と美味しいものを食べること。普段は中高生に理科を教えたり、研究指導したりしています。
連載第三回図版資料

5. データ解析・AI構築の初学者向け自習テキスト
表データを利用したAI学習テキスト(Humanome CatData)
画像・動画を利用したAI学習テキスト(Humanome Eyes)
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!
この記事が気に入ったらサポートをしてみませんか?