
ワクワクから始めるAI・データ解析(2.前処理編)

この記事は初心者向けのノーコードAI構築ツール「Humanome CatData」(以下「CatData」)を使い、まずデータをさわってAIづくりをはじめよう、という連載の第2回となります。これまでの記事は以下のリンクからお読みいただけます。
前回は、解析の大きな流れの説明を中心に、データ解析とAI構築の関係、データ解析のスタート地点となる目標設定の重要性についてお話しさせていただきました。
今回はデータ解析にかかる時間の7割はここに割かれると言われ、構築されるAIの精度に大きな影響を及ぼす行程「前処理」のお話になります。
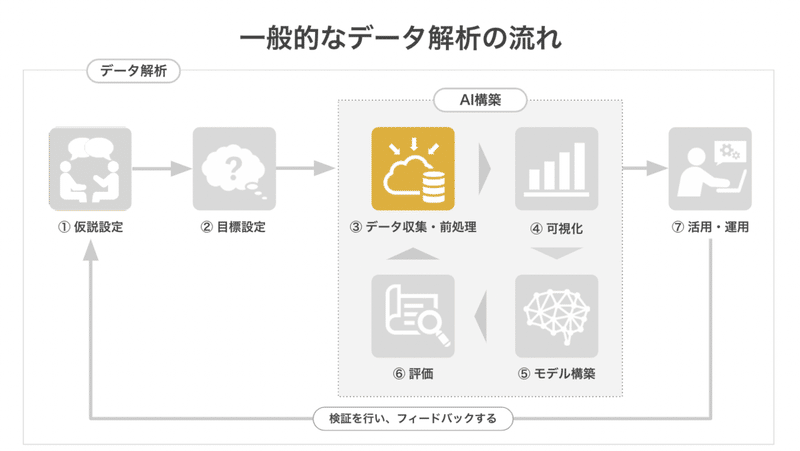
AI構築の中で最も重要なプロセスが前処理です。AIモデルを作る前に、構築に使えない項目を取り除いておくと、できあがったAIの精度が高くなります。この「きれいなデータ作り」のことを前処理といいます。料理で言う下ごしらえのような作業です。
下ごしらえをしなくてもそれなりの料理にはなりますが、きちんと下ごしらえをした材料で作る料理はぐっとおいしくなります。データをきれいに整え、よりよい仕上がりを目指していきましょう。
(1) データをアップロードする
さて、前回ダウンロードしたペンギンデータを使って、「くちばしや水かきの長さからペンギンの種名を予測するAI」を、実際に Humanome CatData を利用して作成します。
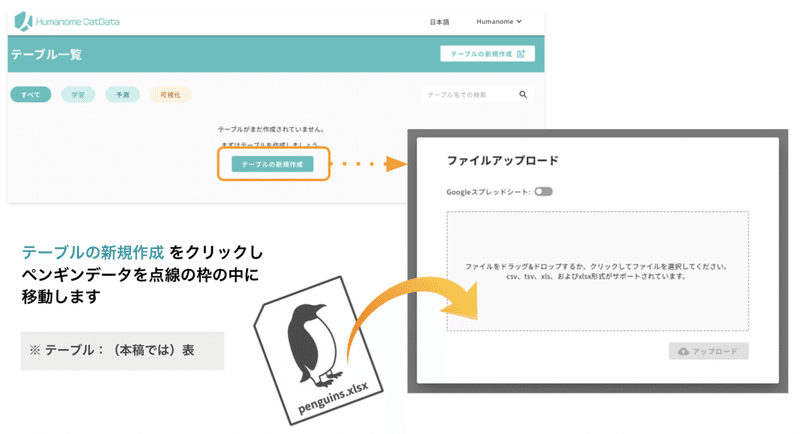
まずCatData にログインし「テーブル一覧 > テーブルの新規作成」から、ペンギンデータ(pengins.xlsx)をアップロードします。完了すると、テーブル(表)の確認画面に移動します。
(2) エラー表示を確認する
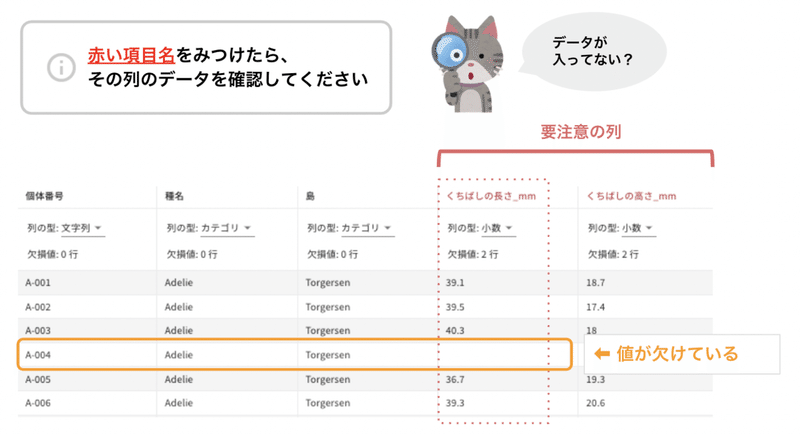
アップロードが完了すると、データの確認画面に移動します。ペンギンデータの場合、項目名の表示が赤と黒になっています。赤い文字は「この先の行程で問題が起こるかもしれない列」を事前にお知らせする表示です。赤い文字を見つけた際は、エラー対応してから次の行程に進みます。
ひとつめはテーブルの中にあるデータの空欄部分への対応です。CatDataがデータに欠けを見つけた場合、エラーとしてお知らせしています。この「欠けているデータ」への対応については、次の段落でご説明します。

もうひとつは「列の型」のチェックです。「列の型」には、各項目のデータの種類を判定した結果が入っています。データの種類には「整数・小数・文字列・カテゴリ」があります。
赤い項目名の列は、データの種類がはっきりと判定できなかったため、CatDataが推測した結果が入っています。例えば「くちばしの長さ」は本来数字(整数・小数)のみが入る列ですが、「文字列」など別の種類のデータが混ざっている可能性があります。念の為確認してみてください。
同じ列に数字と文字など異なる種類(型)が混ざると、AIは正しく学習できません。該当する箇所を見つけた場合は、データファイルを修正し、再アップロードしてください。
(3) 欠損値をきれいにする理由
では、先程の「空欄データ」をきれいに整えていきます。
データの前処理にはさまざまな手法がありますが、その中でも「欠損しているデータへの処理」はよく利用される手法のひとつです。
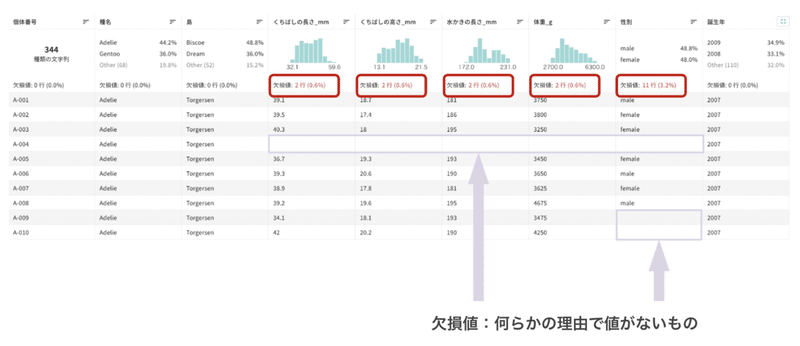
上図はペンギンデータをテーブル画面で表示したものですが、表の中に空欄となっている箇所がいくつか見られます。この「なにか理由があって記録されなかったデータ」を欠損値と呼びます。CatDataでは、列の中に欠損値がある場合、テーブル上部に赤い文字で表示することでお知らせしています。
欠損値があるとAIの構築ができないので、何らかの形で対処する必要があります。この方法には大きく分けて2種類あり、ひとつは欠損値を含む個体(行ごと)や特徴(列ごと)をデータから削除する、もうひとつは欠損値を補完するというやり方です。
(4) 欠損値を削除する準備をしよう
では、データの確認が終わったので、前処理の下準備へ進みます。
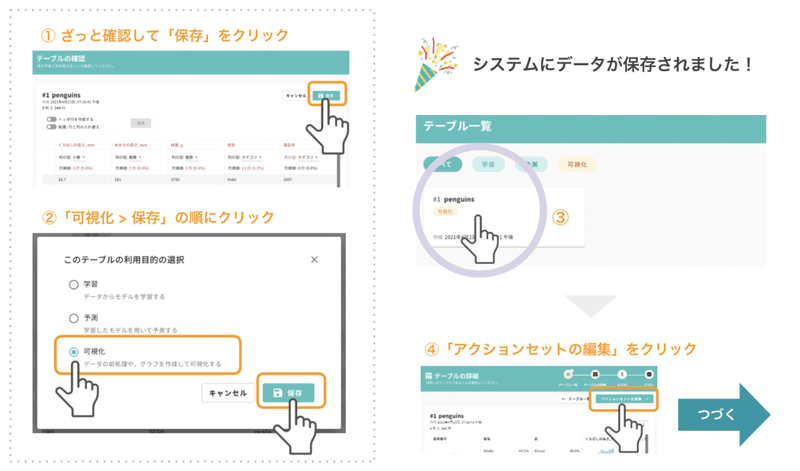
上図の通り、画面右上「保存」ボタンを押すと、次の処理を選ぶポップアップが出てくるので「可視化(前処理もここからできます)> 保存」の順にクリックします。
すると画面が「テーブル一覧」となり、先程確認したペンギンデータが「#1 Pengins」という名前で保存されていることが確認できると思います。これで、データを操作をする準備ができました。
既に前の段落でデータ確認が終わっているので、アップロード後の確認は省略して、さくっと前処理へ進みます。テーブル「#1 Pengins 」>遷移後の画面右上「 アクションセットの編集」の順にクリックしてください。
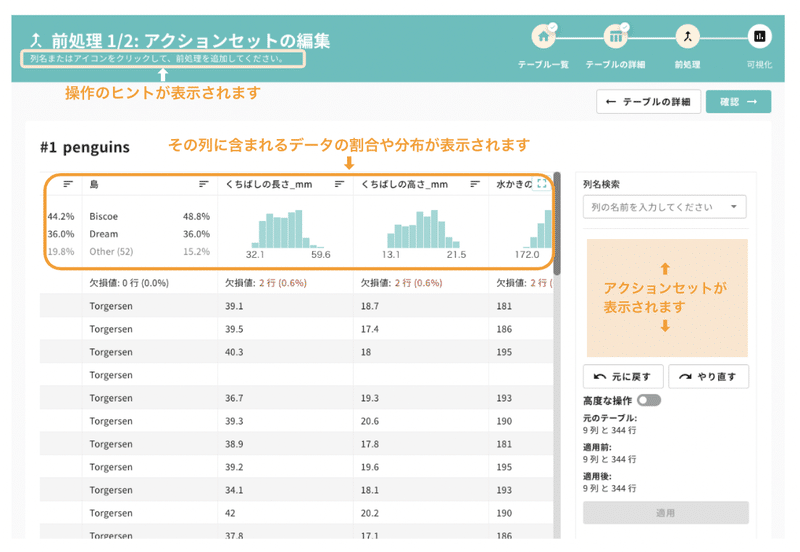
CatDataでは、前処理に関する一つ一つの動作をアクションと呼び、それらをまとめたアクションセットを作成し、前処理を実施します。1つ1つのアクションは、「誕生年が2009年の個体を選ぶ」とか「水かきの長さが200mm以上の個体を選ぶ」といったシンプルなものです。
前処理では、このようにシンプルな条件を組み合わせて、AI構築に利用するデータを選別していきます。
(5) 実際に欠損値を削除してみよう
今回は、欠損値がある個体を取り除くことで、欠損値のないデータを作成します。加工後のデータは、CatDataの中に新しいテーブルとして保存することにしましょう。
先程のテーブルの詳細から「くちばしの長さ」「高さ」「水かきの長さ」「体重」「性別」に欠損値があることがわかります。「性別」に含まれる欠損値が一番多かったので、最初に性別に値がない個体から削除してみます。
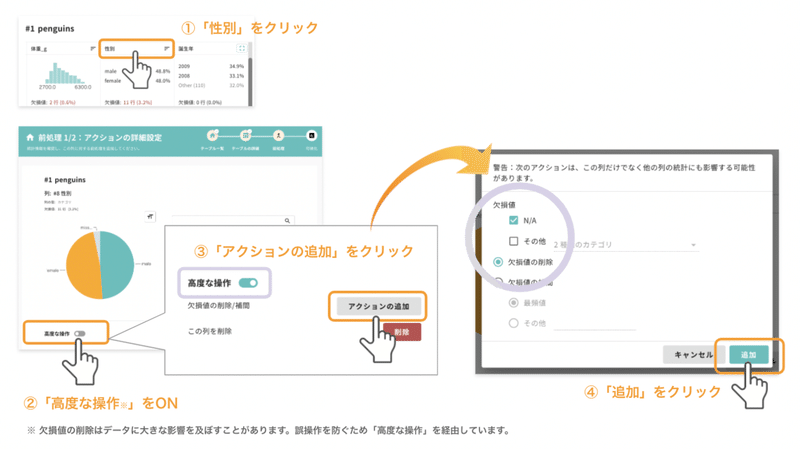
項目名「性別」をクリックすると、欠損値を削除するためのアクション(前処理に関する一つ一つの動作)を作成するページ「アクションの詳細設定」へ移動します。画面左下の「高度な操作」をONにして、欠損値削除に進むためのメニューを表示します。
メニューから「欠損値の削除 / 補間」の右にある「アクションの追加」ボタンをクリックするとポップアップが現れます。「N/A」と「欠損値の削除」が選択されていることを確認したら、右下の「追加」を押してください。
ペンギンデータのように欠損値が空欄となっている場合は、「N/A」を選択することで欠損値が削除できます。特定の数字・文字が欠損値を表す場合は、「その他」に対応する表記を入力してください。
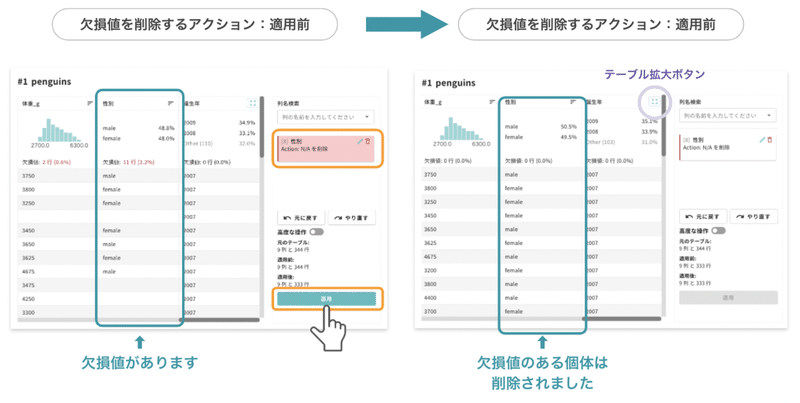
全体のテーブルに戻りました。右側に、先程作成したアクション「[8]性別 Action:N/Aを削除」が表示されています。これが先程作成した「前処理」の内容を示すアクション(フィルタ)の表示です。「8列目・性別のデータから、N/Aとなっているデータ(=欠損値)を選ぶ」という指示になります。
アクションを作成すると、グレーアウトしていた右下の「適用」ボタンが緑に変わります。クリックして、作成したアクションをテーブルに適用してください。これで性別に欠損値がある個体が除かれました。
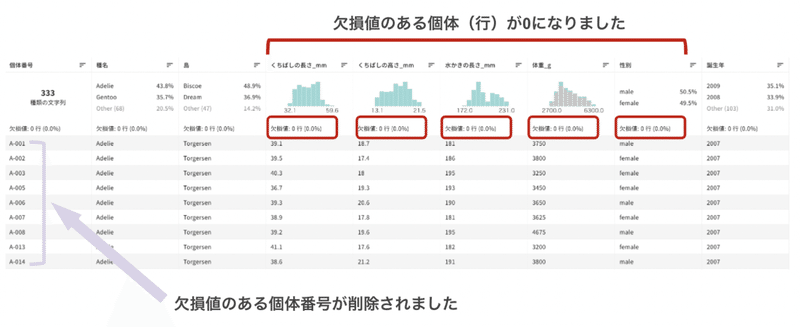
もう一度全体のデータを確認してみます。「くちばしの長さ」や「体重」などにも欠損値がありましたがなくなっています。性別に欠損値のある個体を削除したところ、他の欠損値も全て削除できました。
このことから「くちばしの長さや体重を計測できなかった個体は、性別もよく分からない個体だった」ことがわかります。このようなことは現実でも頻繁に起こります。このような個体や項目は、他の値も信用できないことが多いです。
欠損値という「信用できない値」を削除することで、より綺麗なデータ、より正確なAIの構築につながります。
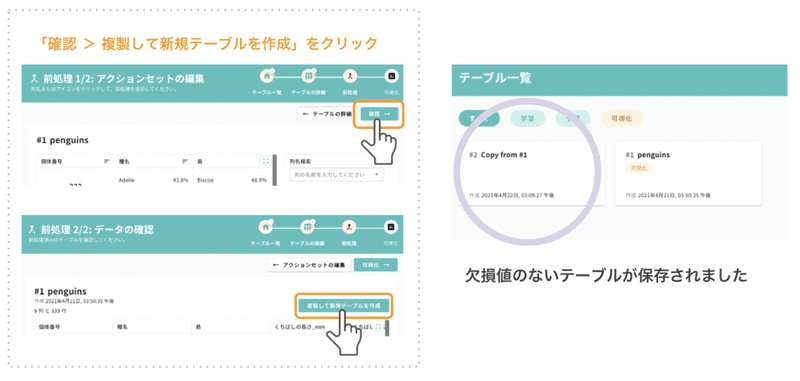
最後にきれいになったデータを保存します。
画面右上の「確認」を押すと、再びテーブルが表示されます。アクションセットを適用した後のテーブルとして、正しい内容であるか確認する画面です。問題なければ、右上の「複製して新規テーブルを作成」をクリックします。
これで、欠損値のないテーブルが保存できました。前処理はこれでおしまいです。
次回のお知らせ
今回は精度の高いAI構築には欠かせない、データを綺麗にする重要行程「前処理」についてお話させていただきました。
次回は「可視化」についてご紹介します。ぜひお読みいただけるとうれしいです。
AI・DX・データサイエンスについてのご質問・共同研究等についてはお気軽にお問い合わせ下さい!
この記事が気に入ったらサポートをしてみませんか?