聖書全部読んで話すAIと地図の例え

①聖書全部読み込んで。
②イエス様は自分についてどう述べてる?
上記指令を、ChatGPTやBingやGoogle等のサービス使わないで、自分のパソコンに入れたAIに答えてもらった。答えてくれた。ヨハネ16:23-33を引用してた。 これが20行のプログラムで無料で実行できる時代が来たわけか。びっくりですね。

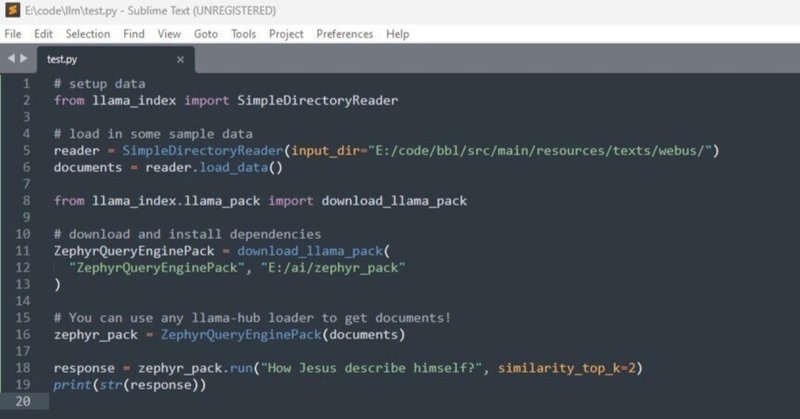
20行のプログラミングのコードはこれだけです。言語はPython。
# setup data
from llama_index import SimpleDirectoryReader
# load in some sample data
reader = SimpleDirectoryReader(input_dir="E:/code/bbl/src/main/resources/texts/webus/")
documents = reader.load_data()
from llama_index.llama_pack import download_llama_pack
# download and install dependencies
ZephyrQueryEnginePack = download_llama_pack(
"ZephyrQueryEnginePack", "E:/ai/zephyr_pack"
)
# You can use any llama-hub loader to get documents!
zephyr_pack = ZephyrQueryEnginePack(documents)
response = zephyr_pack.run("How Jesus describe himself?", similarity_top_k=2)
print(str(response))
ちなみに、読み込ませたのはWorld English Bibleで、ここにおいてあります。著作権の縛りがない現代英語の聖書です。
AIはZephyr-7bという大規模言語モデルです。 聖書を全部入力した上で「イエスは自分についてどう述べたか?」に対するAIの答えは以下画像のとおり:

これは僕の個人的な考えですが、各派の文章を大量に読み込ませ、〇〇派ではこうだという回答ができるようになるようにファインチューニング・微調整・学習させる必要があると思います。というか、教派ごとに個別の大規模言語モデルを作ったほうが良い気がします。
同一教派でも意見の分かれる問題もあるかもしれませんし。そしたら「誰々はこういう意見を述べていた」という引用形式で出典を明記して答えるように大規模言語モデルをチューニングしたほうがより問題が起きにくいとは思います。
あと、チューニングだといろいろなコストがたくさんかかるので、Retrieval-Augmented Generation (RAG)という方法で出典を参照させる方法もあるのですが、今回僕がやってみたのはRAGでした。RAGを自分のPCで実行する方法を @llama_index が発表してたので飛びついたわけです。
なんでこういうことをしているのか。新しい技術が出てきたた時にキリスト教の世界における問題を新しい方法で解決するために応用できはしないかと、試しに使っているのです。
キリスト教の仕事をするのですが、今まで問題とみなされてこなかったことを問題として発見し、それを解決して世界宣教の役に立つようにする仕事をしたいと考えています。そのためにITの技能を使っていきたいと思っています。そのために今世に出てる技術で何ができるかを見知らぬ土地のように探索してます。
土地の探索を例にすると
「到達地点」=「問題が解決された状態」
「解決までの道筋」=「複数の要素技術の組み合わせ」
「各経由地点」=「分割した部分問題とそれを解決する個々の要素技術」
に例えることができ、できるだけ多くの要素技術を知るのが最短ルートを見出すのに役立つからです。
そして、現在出揃ってる要素技術が把握できると
「到達不能地点」=「現在は解決できない問題」
「到達可能地点」=「今解決できる問題」
これの線引ができるようになります。ただ、新しい道路ができるように、日々新しい要素技術は生まれるので到達可能地点はずっと広がり続けます。
土地勘のある住み慣れた地元にとどまるのは楽ですが、他所の知見を得たければ、見知らぬ土地に旅や移住をしなければいけません。
同様に
自分の使い慣れ習熟した技術で満足するのは楽ですが、それで解決できる問題の範囲限界を突破したければ、見知らぬ技術で試行錯誤しなければいけません。
「地図」に「空白があって」存在している近道が表示されていない場合、到達不可能だと誤判断したり、無駄な遠回りをします。
同様に
「各要素技術の把握」に「抜けがあって」存在している「特定の要素技術」を知らないで問題解決をしようとする場合、解決不可能と誤判断したり、無駄な苦労をします。
本当は解決できるはずの問題を解決できないと見送ったり、簡単に導入できる解決方法がすでにあるのにそれを知らないがために自力で解決の道具を作るのに貴重な時間と労力を大量に投入してしまったりする事態を避けたいので、まず現在存在する要素技術の相互関連をできるだけもれなく把握したいのです。
要素技術の把握は具体的には
(*英語で)
・SNSで技術の最先端にいる人達からリアルタイムの技術開発情報を得る
・Githubで関心範囲の技術者をフォローしておすすめ欄に表示される技術を最適化する
・GithubトレンドやHacker Newsを定期的に見る
・気になる技術をキーワードにして検索する
等です。
これを2013年くらいからやってます。
これはと思った技術はお気に入りマークを付けておくわけですが、10年やって3800個くらいです。フォローしてる技術者は1万1100人くらいになりました。日々増えてます。雪だるまような効果があってGithubのおすすめ欄にまだ見ぬソフトウェアが提示される時の提案の精度が非常に高くなりました。
3800個全部覚えてるわけはないんですね。これはと思って見たら、すでに何年か前に自分でお気に入りに入れていて忘れていたという例もいっぱいあります。個々の技術を忘れても、こういう技術はありそうだな、こう検索すれば見つかりそうだなという勘が働くようになり、道具を探す作業が捗ります。
1万1千人技術者をフォローしていてその人達はその人の専門分野では自分より経験もあり能力も高い人で、フォローするだけでその人達を自分の師匠にできるわけです。その人達がお気に入りに入れたソフトウェアが僕に通知で届きます。「なるほどこの人が使ってるのか。自分も試してみよう」となります。
幼いころから理系的な分野が自分に合っていたこと、何かと英語に触れる環境で育ったこと、キリスト教の大学の理学科に入ってクリスチャンになったこと。こういう道を歩まされたので世界宣教の貢献のために技術を世俗から教会に輸入するのが召命だと信じてます。

あと、こういうこと好きじゃないとできないですよね。無理にやろうとすると苦になるならやらないほうがいいですよ。趣味でもあります。止めろと言われてもするでしょう。神様が自分を技術や英語が好きな人として創造してくださったというのがそもそものきっかけです。自分の人生もこれまで合った機会も環境も神様から授かったものです。この授かりものをどう使えば良いか。自分で考え、その一部でも神様に捧げよう。そういう意図と目的を持って今はAIの応用を学んでます。
この記事が気に入ったらサポートをしてみませんか?